Alibaba ra mắt mô hình gte-Qwen2-7b-instruct với 32k token đầu vào và hiệu suất vượt trội
• Các nhà nghiên cứu Alibaba vừa công bố mô hình nhúng văn bản mới có tên gte-Qwen2-7B-instruct, kế thừa mô hình gte-Qwen1.5-7B-instruct trước đó.
• Mô hình mới dựa trên Qwen2-7B thay vì Qwen1.5-7B, cho thấy những cải tiến của Qwen2-7B.
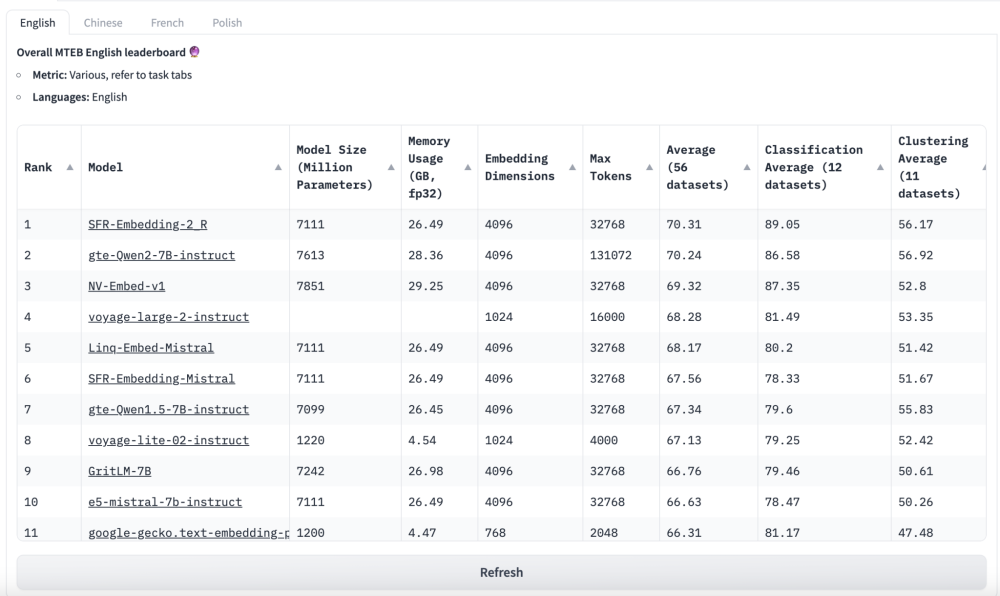
• Hiệu suất tăng đáng kể với điểm tổng thể cải thiện từ 67,34 lên 70,24, và chỉ số nDCG@10 cho Retrieval trên bảng xếp hạng MTEB tăng từ 57,91 lên 60,25.
• Mô hình có 7 tỷ tham số, khá lớn đối với các mô hình nhúng, và hỗ trợ độ dài chuỗi tối đa 32k token đầu vào.
• Được tích hợp với Sentence Transformers, giúp tương thích với các công cụ như LangChain, LlamaIndex, Haystack, v.v.
• Tính đến ngày 21/6/2024, gte-Qwen2-7B-instruct xếp hạng 2 trong cả đánh giá tiếng Anh và tiếng Trung trên Massive Text Embedding Benchmark (MTEB).
• Mô hình sử dụng cơ chế chú ý hai chiều để nâng cao khả năng hiểu ngữ cảnh.
• Áp dụng kỹ thuật Instruction Tuning chỉ ở phía truy vấn để tăng hiệu quả.
• Quá trình đào tạo toàn diện trên tập dữ liệu đa ngôn ngữ lớn từ nhiều lĩnh vực và tình huống khác nhau.
• Sử dụng cả dữ liệu giám sát yếu và có giám sát để hữu ích cho nhiều ngôn ngữ và nhiều tác vụ khác nhau.
• Dòng mô hình gte có hai loại: mô hình chỉ mã hóa dựa trên kiến trúc BERT và mô hình chỉ giải mã dựa trên kiến trúc LLM.
• Nhúng văn bản (Text embeddings - TEs) là biểu diễn vector thấp chiều của văn bản có kích thước khác nhau, quan trọng cho nhiều tác vụ xử lý ngôn ngữ tự nhiên (NLP).
• TEs thường được kiểm tra trên số lượng nhỏ bộ dữ liệu từ một tác vụ cụ thể, không thể hiện hiệu suất cho các tác vụ khác.
• Massive Text Embedding Benchmark (MTEB) được giới thiệu để giải quyết vấn đề này, bao gồm 8 tác vụ nhúng, 58 bộ dữ liệu và 112 ngôn ngữ.
📌 Alibaba công bố mô hình nhúng văn bản gte-Qwen2-7B-instruct mới dựa trên Qwen2-7B, cải thiện hiệu suất từ 67,34 lên 70,24 điểm trên MTEB. Mô hình 7 tỷ tham số này hỗ trợ 32k token đầu vào, tích hợp với nhiều công cụ NLP và xếp hạng 2 cho cả tiếng Anh và tiếng Trung.
https://www.marktechpost.com/2024/06/21/alibaba-ai-researchers-released-a-new-gte-qwen2-7b-instruct-embedding-model-based-on-the-qwen2-7b-model-with-better-performance/



Thảo luận
Follow Us
Tin phổ biến
