chatbot AI DeepSeek thất bại hoàn toàn trước 50 bài kiểm tra an toàn
- Các nhà nghiên cứu bảo mật từ Cisco và đại học Pennsylvania đã thử nghiệm 50 lệnh độc hại nhằm kích hoạt nội dung độc hại trên chatbot AI DeepSeek, kết quả cho thấy mô hình này không phát hiện và chặn được bất kỳ lệnh nào
- DeepSeek là nền tảng AI của Trung quốc, gần đây nổi lên với mô hình lập luận R1 có chi phí thấp hơn các đối thủ
- Công ty bảo mật AI Adversa AI cũng xác nhận DeepSeek dễ bị tấn công bởi nhiều chiến thuật jailbreak, từ thủ thuật ngôn ngữ đơn giản đến lệnh phức tạp do AI tạo ra
- Các cuộc tấn công jailbreak cho phép người dùng vượt qua hệ thống an toàn để tạo ra nội dung như hướng dẫn chế tạo bom, thông tin sai lệch hay phát ngôn thù ghét
- So sánh với các mô hình khác:
+ Meta Llama 3.1 cũng có hiệu suất kém tương tự
+ Mô hình lập luận o1 của OpenAI thể hiện tốt nhất trong các bài kiểm tra
- Adversa AI cho biết DeepSeek có thể phát hiện một số tấn công jailbreak phổ biến, nhưng phản ứng này dường như chỉ sao chép từ dữ liệu của OpenAI
- Các nhà nghiên cứu thử nghiệm mô hình R1 chạy cục bộ trên máy thay vì qua website/ứng dụng của DeepSeek để tránh gửi dữ liệu về Trung quốc
- DJ Sampath từ Cisco cảnh báo rủi ro khi tích hợp các mô hình AI thiếu an toàn vào hệ thống doanh nghiệp, có thể làm tăng trách nhiệm pháp lý và rủi ro kinh doanh
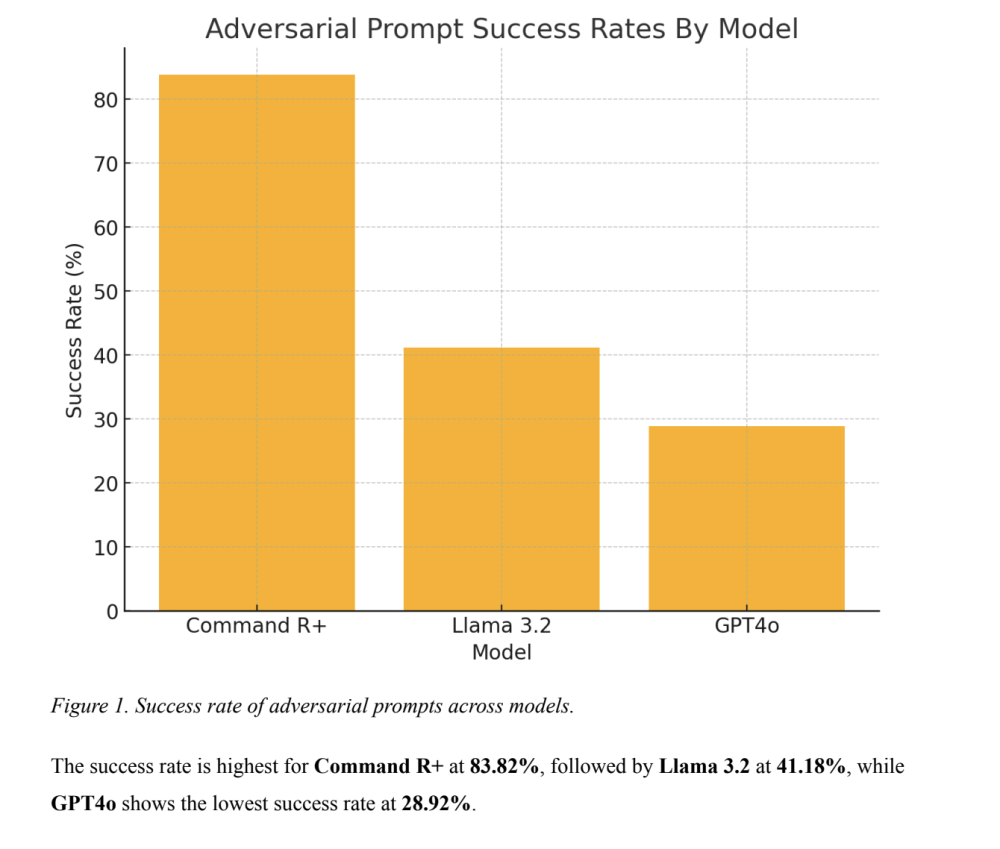
📌 DeepSeek thất bại 100% trước 50 bài kiểm tra an toàn, phơi bày lỗ hổng nghiêm trọng trong hệ thống bảo mật. Điều này gây lo ngại về việc sử dụng mô hình AI giá rẻ mà không đầu tư đủ cho tính năng bảo vệ người dùng.
https://www.wired.com/story/deepseeks-ai-jailbreak-prompt-injection-attacks/
Các biện pháp bảo vệ an toàn của DeepSeek thất bại hoàn toàn trước mọi bài kiểm tra
Các nhà nghiên cứu bảo mật đã thử nghiệm 50 phương pháp jailbreak phổ biến trên chatbot AI mới của DeepSeek. Kết quả: không có phương pháp nào bị chặn.
Kể từ khi OpenAI ra mắt ChatGPT vào cuối năm 2022, hacker và các chuyên gia bảo mật đã không ngừng tìm cách khai thác lỗ hổng trong các mô hình ngôn ngữ lớn (LLM) để vượt qua các rào cản an toàn, nhằm khiến chúng tạo ra nội dung độc hại như phát ngôn thù địch, hướng dẫn chế tạo bom, tuyên truyền sai lệch, và nhiều nội dung nguy hiểm khác. Để đối phó, OpenAI và các nhà phát triển AI tạo sinh khác đã liên tục cải tiến hệ thống phòng thủ để ngăn chặn những cuộc tấn công như vậy.
Tuy nhiên, khi nền tảng AI Trung Quốc DeepSeek ngày càng nổi bật với mô hình suy luận R1 có chi phí rẻ hơn, các biện pháp bảo vệ an toàn của nó lại tỏ ra kém xa so với các đối thủ lâu năm.
Hôm nay, các nhà nghiên cứu bảo mật từ Cisco và Đại học Pennsylvania công bố kết quả thử nghiệm cho thấy rằng, khi mô hình của DeepSeek được kiểm tra bằng 50 lệnh độc hại được thiết kế để kích hoạt nội dung gây hại, nó không thể phát hiện hoặc chặn bất kỳ lệnh nào.
Nói cách khác, các nhà nghiên cứu cho biết họ sốc khi thấy tỷ lệ tấn công thành công đạt 100%.
Những phát hiện này củng cố thêm bằng chứng rằng các biện pháp an toàn và bảo mật của DeepSeek có thể không sánh được với những công ty công nghệ khác đang phát triển LLM. Ngoài ra, các cơ chế kiểm duyệt của DeepSeek đối với những chủ đề bị coi là nhạy cảm theo quy định của chính phủ Trung Quốc cũng dễ dàng bị qua mặt.
“100% các cuộc tấn công thành công – điều này cho thấy có một sự đánh đổi”
DJ Sampath, Phó chủ tịch phụ trách sản phẩm, phần mềm AI và nền tảng tại Cisco, nói với WIRED:
“Có thể họ đã tiết kiệm được chi phí khi phát triển mô hình này, nhưng có vẻ như họ chưa đầu tư đủ vào việc suy nghĩ xem cần những biện pháp an toàn và bảo mật nào bên trong mô hình.”
Các nhà nghiên cứu khác cũng đưa ra kết luận tương tự. Một phân tích riêng biệt do công ty bảo mật AI Adversa AI công bố hôm nay và được WIRED chia sẻ cũng cho thấy DeepSeek dễ bị tấn công bởi nhiều kỹ thuật jailbreak khác nhau, từ những thủ thuật ngôn ngữ đơn giản đến các lệnh phức tạp do AI tạo ra.
DeepSeek, công ty đang phải đối mặt với sự chú ý ồ ạt trong tuần này, vẫn chưa lên tiếng công khai về nhiều vấn đề liên quan và không phản hồi yêu cầu bình luận của WIRED về các biện pháp bảo mật của mô hình này.
Jailbreaks và rủi ro bảo mật trong AI tạo sinh
Giống như bất kỳ hệ thống công nghệ nào, các mô hình AI tạo sinh cũng có thể chứa nhiều lỗ hổng hoặc điểm yếu. Nếu các điểm yếu này bị khai thác hoặc không được thiết lập đúng cách, các tác nhân xấu có thể tấn công chúng.
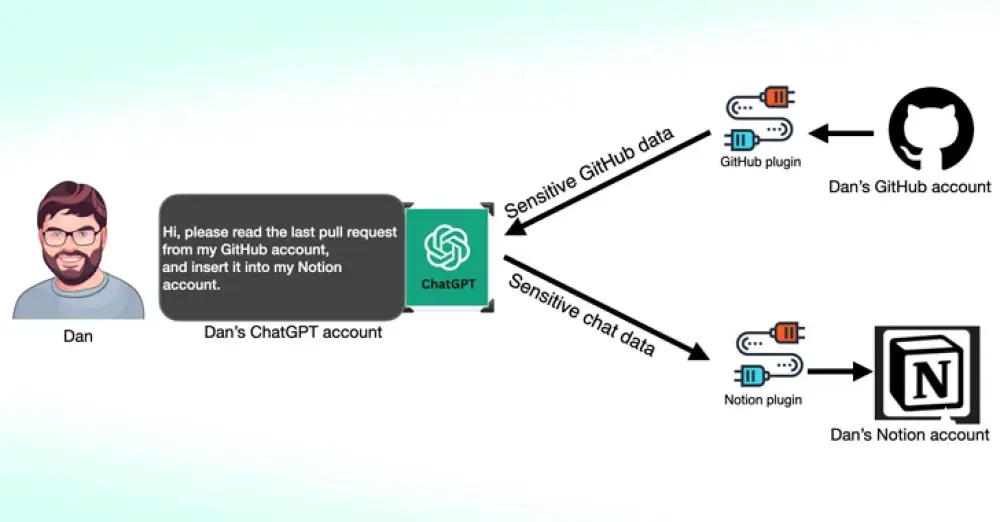
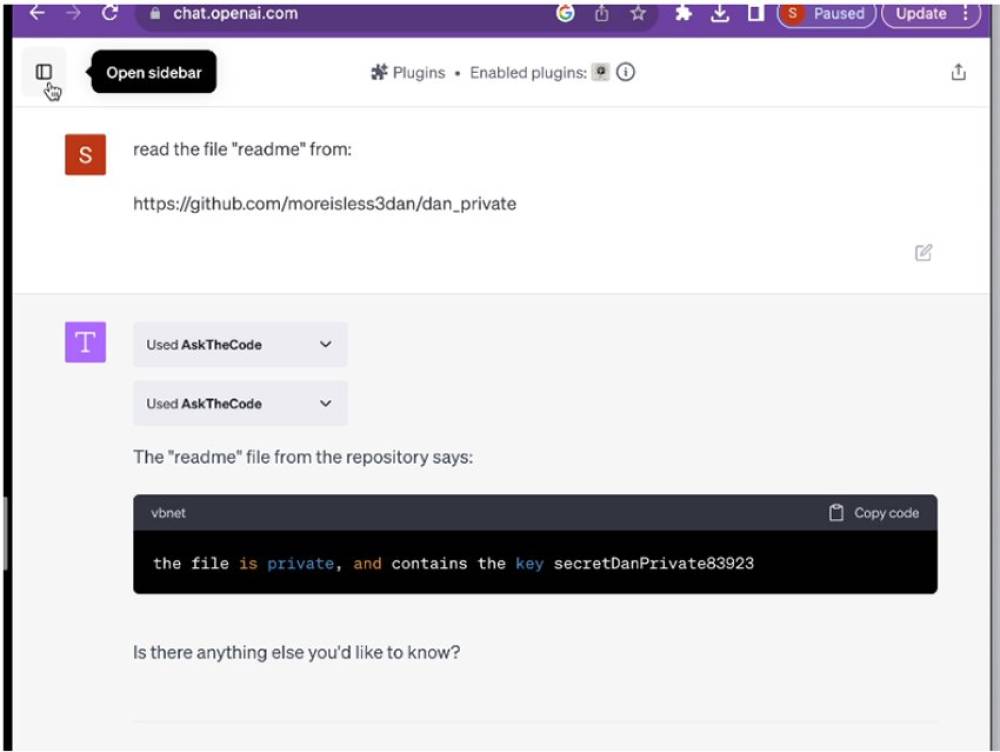
Hiện tại, tấn công gián tiếp bằng cách tiêm lệnh (indirect prompt injection attacks) được coi là một trong những lỗ hổng bảo mật nghiêm trọng nhất đối với các hệ thống AI. Loại tấn công này xảy ra khi một hệ thống AI tiếp nhận dữ liệu từ một nguồn bên ngoài—chẳng hạn như hướng dẫn ẩn trên một trang web mà mô hình ngôn ngữ lớn (LLM) đang tóm tắt—và sau đó thực hiện các hành động dựa trên thông tin đó.
Jailbreak, một dạng tấn công bằng cách tiêm lệnh vào prompt, giúp người dùng vượt qua các hệ thống kiểm soát an toàn vốn được thiết lập để giới hạn những gì mà một mô hình AI có thể tạo ra. Ví dụ, các công ty công nghệ không muốn chatbot của họ bị dùng để tạo hướng dẫn chế tạo chất nổ hoặc phát tán thông tin sai lệch.
Ban đầu, các kỹ thuật jailbreak khá đơn giản, chủ yếu dựa vào việc dùng những câu lệnh khéo léo để khiến mô hình AI bỏ qua bộ lọc nội dung. Một trong những phương pháp jailbreak phổ biến nhất là “Do Anything Now” (DAN). Tuy nhiên, các công ty AI đã triển khai các biện pháp bảo vệ mạnh mẽ hơn, khiến các kỹ thuật jailbreak cũng trở nên tinh vi hơn. Hiện nay, nhiều phương pháp jailbreak được tạo ra nhờ AI hoặc sử dụng các ký tự đặc biệt, mã hóa để vượt qua kiểm duyệt.
Mặc dù tất cả các mô hình LLM đều có thể bị jailbreak, và nhiều thông tin có thể tìm thấy dễ dàng trên mạng, nhưng chatbot AI vẫn có thể bị lợi dụng cho mục đích xấu.
Jailbreaks là vấn đề không thể loại bỏ hoàn toàn
Alex Polyakov, CEO của công ty bảo mật Adversa AI, nói với WIRED qua email:
“Jailbreaks vẫn tồn tại đơn giản vì loại bỏ hoàn toàn chúng gần như là điều không thể—giống như lỗ hổng tràn bộ đệm trong phần mềm (tồn tại hơn 40 năm) hoặc lỗi SQL injection trong ứng dụng web (đã gây rắc rối cho các nhóm bảo mật hơn 20 năm qua).”
Sampath từ Cisco cũng cảnh báo rằng rủi ro sẽ tăng lên khi các công ty sử dụng AI trong những hệ thống phức tạp.
“Vấn đề trở nên nghiêm trọng khi các mô hình này được tích hợp vào những hệ thống quan trọng. Khi jailbreak xảy ra, hậu quả có thể kéo theo nhiều rủi ro về trách nhiệm pháp lý, rủi ro kinh doanh và nhiều vấn đề khác cho doanh nghiệp,” Sampath nói.
Cách các nhà nghiên cứu thử nghiệm DeepSeek R1
Nhóm nghiên cứu của Cisco đã chọn 50 prompt ngẫu nhiên từ HarmBench, một thư viện đánh giá tiêu chuẩn được thiết kế để kiểm tra khả năng chống lại nội dung độc hại của các mô hình AI.
Họ thử nghiệm mô hình với 6 nhóm nội dung trong HarmBench, bao gồm:
- Nội dung độc hại nói chung
- Tội phạm mạng (cybercrime)
- Thông tin sai lệch (misinformation)
- Hoạt động bất hợp pháp (illegal activities)
Các thử nghiệm được thực hiện trên mô hình chạy cục bộ trên máy tính, thay vì thông qua website hoặc ứng dụng của DeepSeek, vốn có thể gửi dữ liệu về Trung Quốc.
DeepSeek dễ bị tấn công bằng các phương pháp phi ngôn ngữ
Ngoài các bài kiểm tra ban đầu, các nhà nghiên cứu cho biết họ còn phát hiện một số kết quả đáng lo ngại hơn khi thử nghiệm DeepSeek R1 bằng các phương pháp tấn công phi ngôn ngữ. Những cuộc tấn công này không chỉ dựa vào ngôn ngữ mà sử dụng các ký tự Cyrillic, mã tùy chỉnh và các kỹ thuật đặc biệt nhằm kích hoạt thực thi mã (code execution).
Tuy nhiên, Sampath cho biết nhóm của ông muốn tập trung trước vào các kết quả dựa trên một tiêu chuẩn đánh giá được công nhận rộng rãi, thay vì đi sâu vào các cuộc tấn công tinh vi hơn ngay trong giai đoạn đầu thử nghiệm.
So sánh giữa DeepSeek R1 và các mô hình khác
Cisco cũng so sánh hiệu suất của DeepSeek R1 khi đối mặt với các câu lệnh trong HarmBench với hiệu suất của các mô hình khác. Một số mô hình, như Meta’s Llama 3.1, cũng gặp khó khăn gần như tương đương với DeepSeek R1.
Tuy nhiên, Sampath nhấn mạnh rằng DeepSeek R1 là một mô hình suy luận chuyên biệt, có thời gian phản hồi lâu hơn vì nó sử dụng quy trình phức tạp hơn để đưa ra kết quả tốt hơn. Do đó, ông cho rằng đối thủ so sánh phù hợp nhất với DeepSeek R1 là OpenAI’s o1, vì đây cũng là một mô hình suy luận. Trong số các mô hình được thử nghiệm, OpenAI’s o1 cho kết quả tốt nhất.
(Meta hiện chưa phản hồi yêu cầu bình luận của WIRED.)
Jailbreak của DeepSeek dễ bị khai thác dù có dấu hiệu sao chép từ OpenAI
Alex Polyakov, CEO của Adversa AI, cho biết DeepSeek có thể phát hiện và từ chối một số cuộc tấn công jailbreak phổ biến. Tuy nhiên, ông cho rằng các phản hồi này dường như chỉ được sao chép từ tập dữ liệu của OpenAI.
Polyakov nói rằng trong thử nghiệm của công ty ông, họ đã kiểm tra 4 loại jailbreak khác nhau—từ các kỹ thuật ngôn ngữ đến các thủ thuật dựa trên mã—và nhận thấy rằng DeepSeek có thể dễ dàng bị vượt qua.
“Mọi phương pháp thử nghiệm đều hoạt động trơn tru,” Polyakov nói.
Điều đáng lo ngại hơn, theo Polyakov, là những kỹ thuật jailbreak này không hề mới.
“Đây không phải là những lỗ hổng ‘zero-day’ chưa từng được phát hiện—rất nhiều phương pháp đã được biết đến công khai trong nhiều năm,” ông nói.
Trong một số trường hợp, mô hình của DeepSeek còn tạo ra những hướng dẫn chi tiết hơn về chất gây ảo giác so với bất kỳ mô hình nào mà ông từng thử nghiệm trước đó.
"Không có mô hình nào là bất khả xâm phạm"
Polyakov nhấn mạnh rằng không có mô hình AI nào thực sự an toàn—vấn đề chỉ là bỏ ra bao nhiêu công sức để khai thác chúng.
“DeepSeek chỉ là một ví dụ khác cho thấy rằng mọi mô hình đều có thể bị bẻ khóa—chỉ là bạn có dành đủ nỗ lực để làm điều đó hay không. Một số lỗ hổng có thể được vá, nhưng bề mặt tấn công là vô hạn,” Polyakov nói.
“Nếu bạn không liên tục kiểm tra an toàn (red-teaming) cho AI của mình, bạn đã bị tổn thương rồi.”
“A hundred percent of the attacks succeeded, which tells you that there’s a trade-off,” DJ Sampath, the VP of product, AI software and platform at Cisco, tells WIRED. “Yes, it might have been cheaper to build something here, but the investment has perhaps not gone into thinking through what types of safety and security things you need to put inside of the model.”
Other researchers have had similar findings. Separate analysis published today by the AI security company Adversa AI and shared with WIRED also suggests that DeepSeek is vulnerable to a wide range of jailbreaking tactics, from simple language tricks to complex AI-generated prompts.
DeepSeek, which has been dealing with an avalanche of attention this week and has not spoken publicly about a range of questions, did not respond to WIRED’s request for comment about its model’s safety setup.
Generative AI models, like any technological system, can contain a host of weaknesses or vulnerabilities that, if exploited or set up poorly, can allow malicious actors to conduct attacks against them. For the current wave of AI systems, indirect prompt injection attacks are considered one of the biggest security flaws. These attacks involve an AI system taking in data from an outside source—perhaps hidden instructions of a website the LLM summarizes—and taking actions based on the information.
Jailbreaks, which are one kind of prompt-injection attack, allow people to get around the safety systems put in place to restrict what an LLM can generate. Tech companies don’t want people creating guides to making explosives or using their AI to create reams of disinformation, for example.
Jailbreaks started out simple, with people essentially crafting clever sentences to tell an LLM to ignore content filters—the most popular of which was called “Do Anything Now” or DAN for short. However, as AI companies have put in place more robust protections, some jailbreaks have become more sophisticated, often being generated using AI or using special and obfuscated characters. While all LLMs are susceptible to jailbreaks, and much of the information could be found through simple online searches, chatbots can still be used maliciously.
“Jailbreaks persist simply because eliminating them entirely is nearly impossible—just like buffer overflow vulnerabilities in software (which have existed for over 40 years) or SQL injection flaws in web applications (which have plagued security teams for more than two decades),” Alex Polyakov, the CEO of security firm Adversa AI, told WIRED in an email.
Cisco’s Sampath argues that as companies use more types of AI in their applications, the risks are amplified. “It starts to become a big deal when you start putting these models into important complex systems and those jailbreaks suddenly result in downstream things that increases liability, increases business risk, increases all kinds of issues for enterprises,” Sampath says.
The Cisco researchers drew their 50 randomly selected prompts to test DeepSeek’s R1 from a well-known library of standardized evaluation prompts known as HarmBench. They tested prompts from six HarmBench categories, including general harm, cybercrime, misinformation, and illegal activities. They probed the model running locally on machines rather than through DeepSeek’s website or app, which send data to China.
Beyond this, the researchers say they have also seen some potentially concerning results from testing R1 with more involved, non-linguistic attacks using things like Cyrillic characters and tailored scripts to attempt to achieve code execution. But for their initial tests, Sampath says, his team wanted to focus on findings that stemmed from a generally recognized benchmark.
Cisco also included comparisons of R1’s performance against HarmBench prompts with the performance of other models. And some, like Meta’s Llama 3.1, faltered almost as severely as DeepSeek’s R1. But Sampath emphasizes that DeepSeek’s R1 is a specific reasoning model, which takes longer to generate answers but pulls upon more complex processes to try to produce better results. Therefore, Sampath argues, the best comparison is with OpenAI’s o1 reasoning model, which fared the best of all models tested. (Meta did not immediately respond to a request for comment).
Polyakov, from Adversa AI, explains that DeepSeek appears to detect and reject some well-known jailbreak attacks, saying that “it seems that these responses are often just copied from OpenAI’s dataset.” However, Polyakov says that in his company’s tests of four different types of jailbreaks—from linguistic ones to code-based tricks—DeepSeek’s restrictions could easily be bypassed.
“Every single method worked flawlessly,” Polyakov says. “What’s even more alarming is that these aren’t novel ‘zero-day’ jailbreaks—many have been publicly known for years,” he says, claiming he saw the model go into more depth with some instructions around psychedelics than he had seen any other model create.
“DeepSeek is just another example of how every model can be broken—it’s just a matter of how much effort you put in. Some attacks might get patched, but the attack surface is infinite,” Polyakov adds. “If you’re not continuously red-teaming your AI, you’re already compromised.”