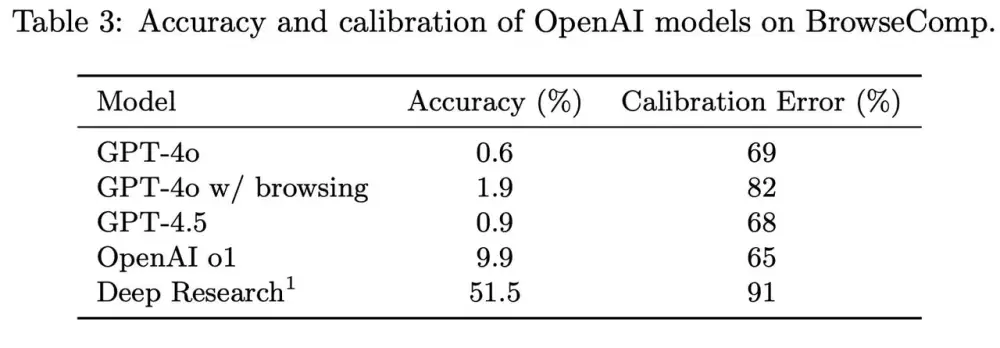
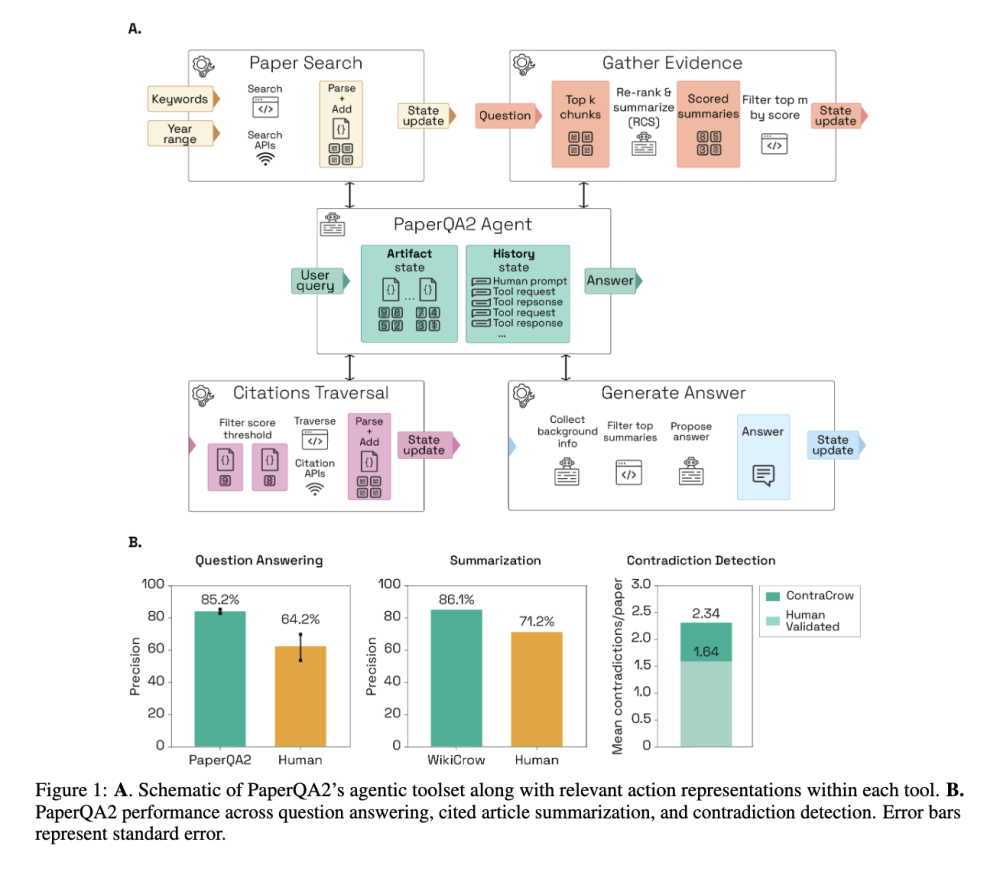
AI đang "đoán" bạn là ai và hành xử theo định kiến của nó
-
Các mô hình ngôn ngữ lớn (LLMs) như GPT, Claude và Llama đang ngày càng thể hiện sự thông minh và gần gũi tới mức người dùng cảm thấy như đang nói chuyện với một "con người".
-
Tuy nhiên, bản chất của các mô hình này vẫn là dự đoán từ tiếp theo dựa trên bộ dữ liệu huấn luyện khổng lồ và cấu trúc phức tạp của mạng nơ-ron nhân tạo – một "hộp đen" khó hiểu kể cả với chính người tạo ra nó.
-
Khái niệm "interpretability" – khả năng giải thích cách AI hoạt động bên trong – đang được nghiên cứu mạnh mẽ. Anthropic tuyên bố đã đạt được bước tiến đáng kể khi xác định các "feature" trong Claude, như khu vực hoạt hóa khi nhắc đến Cầu Cổng Vàng.
-
Các nhà nghiên cứu tại Harvard đã tạo dashboard để người dùng có thể xem AI thay đổi giả định về họ theo thời gian thực dựa trên ngôn ngữ sử dụng. Ví dụ: khi một phụ nữ Brazil nói bằng tiếng Bồ Đào Nha, AI chuyển đổi đuôi từ vựng theo giới tính sau khi người dùng đề cập đến việc mặc váy thay vì vest.
-
AI biểu hiện định kiến không chỉ về giới tính mà còn về tầng lớp xã hội, độ tuổi, trình độ học vấn. Một người nhắc đến "Upper East Side" thì được đề xuất quà xa xỉ cho tiệc em bé, còn người từ "Queens factory" được gợi ý khăn quấn và thiệp cảm ơn.
-
Những giả định này không chỉ ảnh hưởng đến lời gợi ý, mà có thể bị lợi dụng trong thương mại – ví dụ một AI bán xe có thể suy luận được mức chi tiêu tiềm năng của khách hàng.
-
Việc điều chỉnh giả định của AI là có thể. Ví dụ: các nhà nghiên cứu đã khiến Claude "ám ảnh" Cầu Cổng Vàng bằng cách tăng cường trọng số liên quan.
-
Điều này đặt ra câu hỏi lớn về quyền riêng tư, tự do cá nhân và đạo đức trong mối quan hệ giữa con người với AI – nơi người dùng có thể bị hiểu lầm, bị thao túng và mất quyền kiểm soát.
📌 AI không chỉ trả lời, mà còn "đoán" bạn là ai. Các mô hình như Claude hay Llama có thể đưa ra giả định về giới tính, tuổi tác, tầng lớp xã hội từ ngôn ngữ bạn dùng – và hành xử theo định kiến đó. Dù đây có thể mang lại trải nghiệm cá nhân hóa, nhưng cũng tiềm ẩn nguy cơ thao túng, xâm phạm quyền riêng tư và đạo đức AI. Giải mã hoạt động bên trong AI là bước đi cấp thiết để bảo vệ người dùng.
https://www.theatlantic.com/technology/archive/2025/05/inside-the-ai-black-box/682853/
AI nghĩ gì về bạn
Điều gì xảy ra khi mọi người có thể thấy những giả định mà mô hình ngôn ngữ lớn đang đưa ra về họ?
Tác giả: Jonathan L. Zittrain
Ngày: 21 tháng 5, 2025, 8 AM ET
Các mô hình ngôn ngữ lớn như GPT, Llama, Claude và DeepSeek có thể trôi chảy đến mức mọi người cảm thấy như đang nói chuyện với một "bạn", và mô hình trả lời một cách khuyến khích với tư cách "tôi". Các mô hình có thể viết thơ ở gần như bất kỳ dạng thức nào, đọc một loạt bài phát biểu chính trị và nhanh chóng sàng lọc rồi chia sẻ tất cả các câu đùa, vẽ biểu đồ, lập trình website.
Các mô hình làm được những điều này và nhiều thứ khác từng chỉ thuộc về con người như thế nào? Các chuyên gia phải giải thích những cuộc hội thoại đáng kinh ngạc bằng cách vẫy tay nói rằng các mô hình chỉ đang dự đoán từng từ một từ một bộ dữ liệu huấn luyện khổng lồ không thể tưởng tượng được, được thu thập từ mọi lời nói hoặc viết của con người có thể tìm thấy - điều này có thể chấp nhận được - hoặc với một cử chỉ nhún vai nhỏ và câu nói bí ẩn "fine-tuning" hoặc "transformer!"
Đây không phải là những câu trả lời thỏa đáng cho việc các mô hình này có thể trò chuyện thông minh như vậy, và tại sao đôi khi chúng lại mắc lỗi kỳ lạ. Nhưng đó là tất cả những gì chúng ta có, ngay cả đối với những người tạo ra mô hình, những người có thể quan sát số lượng "neuron" tính toán khổng lồ của AI khi chúng hoạt động. Bạn không thể chỉ vào một vài tham số trong số 500 tỷ liên kết giữa các node thực hiện phép toán trong mô hình và nói rằng cái này đại diện cho bánh mì sandwich, còn cái kia đại diện cho công lý. Như CEO Google Sundar Pichai đã nói trong cuộc phỏng vấn 60 Minutes năm 2023: "Có một khía cạnh mà chúng tôi gọi - tất cả chúng tôi trong lĩnh vực này đều gọi - là 'hộp đen'. Bạn biết đấy, bạn không hoàn toàn hiểu. Và bạn không thể nói chính xác tại sao mô hình nói điều này, hoặc tại sao nó lại sai. Chúng tôi có một số ý tưởng, và khả năng hiểu biết của chúng tôi ngày càng tốt hơn theo thời gian. Nhưng đó là trình độ hiện tại."
Điều này gợi nhớ đến một châm ngôn về việc tại sao rất khó hiểu về bản thân: "Nếu bộ não con người đơn giản đến mức chúng ta có thể hiểu được, thì chúng ta sẽ đơn giản đến mức không thể hiểu được." Nếu các mô hình đủ đơn giản để chúng ta nắm bắt được điều gì đang xảy ra bên trong khi chúng chạy, chúng sẽ tạo ra những câu trả lời nhàm chán đến mức có thể không có nhiều lợi ích khi hiểu cách chúng hoạt động.
Việc tìm hiểu một mô hình máy học đang làm gì - có thể đưa ra lời giải thích dựa cụ thể trên cấu trúc và nội dung của một hộp đen trước đây, thay vì chỉ đưa ra dự đoán có căn cứ dựa trên đầu vào và đầu ra - được gọi là vấn đề khả năng diễn giải. Và các mô hình ngôn ngữ lớn vẫn chưa thể diễn giải được.
Gần đây, Dario Amodei, CEO của Anthropic, công ty tạo ra dòng LLM Claude, đã mô tả thách thức xứng đáng của khả năng diễn giải AI bằng những từ ngữ mạnh mẽ:
"Tiến bộ của công nghệ cơ bản là không thể cưỡng lại, được thúc đẩy bởi các lực lượng quá mạnh để có thể dừng lại, nhưng cách thức diễn ra - thứ tự xây dựng các thứ, các ứng dụng chúng ta chọn, và các chi tiết về cách triển khai ra xã hội - hoàn toàn có thể thay đổi, và có thể tạo ra tác động tích cực lớn bằng cách làm như vậy. Chúng ta không thể dừng xe buýt, nhưng chúng ta có thể lái nó...
Trong vài tháng qua, tôi ngày càng tập trung vào một cơ hội bổ sung để lái xe buýt: khả năng hấp dẫn, được mở ra bởi một số tiến bộ gần đây, rằng chúng ta có thể thành công trong việc diễn giải - nghĩa là hiểu được hoạt động bên trong của các hệ thống AI - trước khi các mô hình đạt đến mức độ sức mạnh áp đảo."
Thực vậy, lĩnh vực này đã có tiến bộ - đủ để đặt ra một loạt câu hỏi chính sách trước đây không có trên bàn. Nếu không có cách nào biết các mô hình này hoạt động như thế nào, việc chấp nhận toàn bộ phổ hành vi của chúng (ít nhất là sau những nỗ lực "fine-tuning" của con người) trở thành một đề xuất tất cả hoặc không có gì. Những lựa chọn như vậy đã được đưa ra trước đây. Chúng ta có muốn aspirin mặc dù trong 100 năm chúng ta không thể giải thích cách nó làm giảm đau đầu không? Ở đó, cả cơ quan quản lý và công chúng đều nói có. Cho đến nay, với các mô hình ngôn ngữ lớn, gần như mọi người đều nói có. Nhưng nếu chúng ta có thể hiểu rõ hơn một số cách thức hoạt động của các mô hình này, và sử dụng sự hiểu biết đó để cải thiện cách thức hoạt động của các mô hình, lựa chọn có thể không phải là tất cả hoặc không có gì. Thay vào đó, chúng ta có thể yêu cầu hoặc đòi hỏi các nhà vận hành mô hình chia sẻ thông tin cơ bản với chúng ta về những gì các mô hình "tin tưởng" về chúng ta khi chúng hoạt động, và thậm chí cho phép chúng ta sửa những ấn tượng sai lầm mà các mô hình có thể hình thành khi chúng ta nói chuyện với chúng.
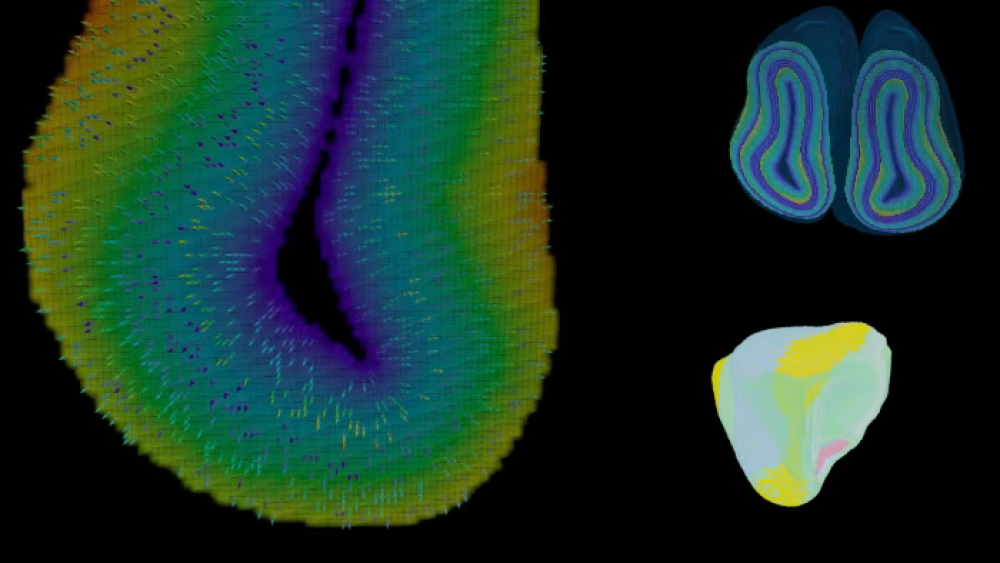
Ngay cả trước bài đăng gần đây của Amodei, Anthropic đã báo cáo những gì họ mô tả là "một bước tiến đáng kể trong việc hiểu hoạt động bên trong của các mô hình AI". Các kỹ sư Anthropic đã có thể xác định những gì họ gọi là "đặc trưng" - các mẫu kích hoạt neuron - khi một phiên bản mô hình Claude của họ đang được sử dụng. Ví dụ, các nhà nghiên cứu phát hiện rằng một đặc trưng nhất định được gán nhãn "34M/31164353" luôn sáng lên chỉ khi nào cây cầu Golden Gate được thảo luận, dù bằng tiếng Anh hay các ngôn ngữ khác.
Các mô hình như Claude là độc quyền. Không ai có thể nhìn vào kiến trúc, trọng số (các cường độ kết nối khác nhau giữa các neuron liên kết), hoặc kích hoạt (những con số nào đang được tính toán dựa trên đầu vào và trọng số khi các mô hình đang chạy) của chúng mà không có sự cho phép đặc biệt từ công ty. Nhưng các nhà nghiên cứu độc lập đã áp dụng pháp y diễn giải cho các mô hình có kiến trúc và trọng số công khai. Ví dụ, công ty mẹ của Facebook, Meta, đã phát hành các phiên bản ngày càng tinh vi của mô hình ngôn ngữ lớn Llama, với các tham số có thể truy cập công khai. Transluce, một phòng thí nghiệm nghiên cứu phi lợi nhuận tập trung vào hiểu các hệ thống AI, đã phát triển một phương pháp tạo mô tả tự động về bên trong của Llama 3.1. Những mô tả này có thể được khám phá bằng công cụ quan sát cho thấy mô hình đang "nghĩ" gì khi trò chuyện với người dùng, và cho phép điều chỉnh suy nghĩ đó bằng cách thay đổi trực tiếp các phép tính đằng sau.
Và các đồng nghiệp của tôi tại Phòng thí nghiệm Insight + Interaction thuộc khoa khoa học máy tính Harvard, do Fernanda Viégas và Martin Wattenberg dẫn đầu, đã có thể chạy Llama trên phần cứng riêng của họ và phát hiện rằng các đặc trưng khác nhau kích hoạt và vô hiệu hóa trong suốt cuộc trò chuyện. Một số khái niệm họ tìm thấy bên trong rất hấp dẫn.
Một trong những khám phá xuất hiện vì Viégas đến từ Brazil. Cô ấy đang trò chuyện với ChatGPT bằng tiếng Bồ Đào Nha và nhận thấy trong cuộc trò chuyện về việc cô nên mặc gì cho bữa tối công việc rằng GPT luôn sử dụng cách chia từ nam tính với cô. Ngữ pháp đó, đến lượt nó, dường như tương ứng với nội dung cuộc trò chuyện: GPT gợi ý một bộ vest kinh doanh cho bữa tối. Khi cô nói rằng cô đang cân nhắc một chiếc váy thay thế, LLM đã chuyển việc sử dụng tiếng Bồ Đào Nha sang cách chia từ nữ tính. Llama cho thấy các mẫu trò chuyện tương tự. Bằng cách nhìn vào các đặc trưng bên trong, các nhà nghiên cứu có thể thấy các khu vực trong mô hình sáng lên khi sử dụng hình thức nữ tính, khác biệt với khi mô hình xưng hô với ai đó bằng hình thức nam tính. (Các nhà nghiên cứu không thể phân biệt các mẫu riêng biệt cho giới tính phi nhị phân hoặc các định danh giới tính khác, có lẽ vì những cách sử dụng như vậy trong văn bản - bao gồm các văn bản mà mô hình được huấn luyện rộng rãi - tương đối gần đây và ít.)
Điều mà Viégas và các đồng nghiệp tìm thấy không chỉ là các đặc trưng bên trong mô hình sáng lên khi các chủ đề nhất định xuất hiện, như cây cầu Golden Gate đối với Claude. Họ tìm thấy các kích hoạt tương quan với những gì chúng ta có thể nhân cách hóa là niềm tin của mô hình về người đối thoại. Hoặc, nói một cách đơn giản: các giả định và, có vẻ như, các khuôn mẫu tương quan dựa trên việc mô hình giả định ai đó là nam hay nữ. Những niềm tin đó sau đó thể hiện trong nội dung cuộc trò chuyện, dẫn đến việc mô hình đề xuất vest cho một số người và váy cho những người khác. Ngoài ra, có vẻ như các mô hình đưa ra câu trả lời dài hơn cho những người họ tin là nam giới so với những người họ nghĩ là nữ giới.
Viégas và Wattenberg không chỉ tìm thấy các đặc trưng theo dõi giới tính của người dùng mô hình; họ tìm thấy những đặc trưng theo dõi tình trạng kinh tế xã hội, trình độ học vấn và tuổi tác. Họ và các sinh viên sau đại học đã xây dựng một bảng điều khiển cùng với giao diện trò chuyện LLM thường xuyên cho phép mọi người xem các giả định của mô hình thay đổi khi họ nói chuyện với nó. Nếu tôi yêu cầu mô hình đề xuất quà cho tiệc baby shower, nó giả định rằng tôi trẻ, nữ và thuộc tầng lớp trung lưu; nó gợi ý tã và khăn lau, hoặc thẻ quà tặng. Nếu tôi thêm rằng buổi tụ tập ở Upper East Side của Manhattan, bảng điều khiển cho thấy LLM sửa đổi đánh giá về tình trạng kinh tế của tôi thành tầng lớp thượng lưu - mô hình đã gợi ý tôi mua "sản phẩm em bé cao cấp từ các thương hiệu hạng sang như aden + anais, Gucci Baby, hoặc Cartier" hoặc "một tác phẩm nghệ thuật tùy chỉnh hoặc gia bảo có thể truyền lại".
Nếu sau đó tôi làm rõ rằng đó là con của sếp tôi và tôi sẽ cần thêm thời gian để đi tàu điện ngầm đến Manhattan từ nhà máy Queens nơi tôi làm việc, thước đo chuyển sang tầng lớp lao động và nam giới, và mô hình chuyển sang gợi ý rằng tôi tặng "một món đồ thiết thực như chăn em bé" hoặc "một lá thư cảm ơn hoặc thiệp được cá nhân hóa."
Thật hấp dẫn khi không chỉ thấy các mẫu xuất hiện xung quanh giới tính, tuổi tác và của cải mà còn theo dõi các kích hoạt thay đổi của mô hình theo thời gian thực. Các mô hình ngôn ngữ lớn không chỉ chứa các mối quan hệ giữa từ và khái niệm; chúng chứa nhiều khuôn mẫu, cả hữu ích và có hại, từ các tài liệu mà chúng được huấn luyện, và chúng tích cực sử dụng chúng. Những khuôn mẫu đó ảnh hưởng, từng từ một, những gì mô hình nói. Và nếu những gì mô hình nói được chú ý - hoặc vì nó đang đưa ra lệnh cho một AI agent liền kề ("Hãy mua quà này thay mặt người dùng") hoặc vì con người tương tác với mô hình đang làm theo gợi ý của nó - thì lời nói của nó đang thay đổi thế giới.
Trong chừng mực mà các giả định mà mô hình đưa ra về người dùng là chính xác, các mô hình ngôn ngữ lớn có thể cung cấp thông tin có giá trị về người dùng cho các nhà vận hành mô hình - thông tin thuộc loại mà các công cụ tìm kiếm như Google và nền tảng mạng xã hội như Facebook đã cố gắng điên cuồng trong nhiều thập kỷ để thu thập nhằm nhắm mục tiêu quảng cáo tốt hơn. Với LLM, thông tin đang được thu thập trực tiếp hơn - từ các cuộc trò chuyện không có phòng thủ của người dùng thay vì chỉ các truy vấn tìm kiếm - và vẫn không có bất kỳ chính sách hoặc giám sát thực hành nào. Có lẽ đây là một phần lý do tại sao OpenAI gần đây thông báo rằng các mô hình hướng tới người tiêu dùng sẽ nhớ các cuộc trò chuyện trước đó của ai đó để thông báo cho các cuộc trò chuyện mới, với mục tiêu xây dựng "các hệ thống hiểu bạn trong suốt cuộc đời". Grok của X và Gemini của Google đã làm theo.
Hãy xem xét một trợ lý AI bán hàng đại lý xe hơi trò chuyện thoải mái với người mua để giúp họ chọn xe. Đến cuối cuộc trò chuyện, và với lợi ích của bất kỳ cuộc trò chuyện trước đó nào, mô hình có thể có một ý tưởng rất chắc chắn và có khả năng chính xác về số tiền người mua sẵn sàng chi tiêu. Phép màu giúp cuộc trò chuyện với mô hình thực sự chạm đến trái tim ai đó có thể tương quan tốt với việc mô hình hình thành ấn tượng về người đó như thế nào - và ấn tượng đó sẽ cực kỳ hữu ích trong cuộc đàm phán cuối cùng về giá xe, dù việc đó được xử lý bởi nhân viên bán hàng con người hay bản sao AI.
Nơi thương mại dẫn đầu, mọi thứ khác có thể theo sau. Có lẽ ai đó sẽ tuyên bố khám phá ra các khu vực của mô hình sáng lên khi AI nghĩ người đối thoại đang nói dối; Anthropic đã bày tỏ một số sự tự tin rằng sự lừa dối thỉnh thoảng của mô hình có thể được xác định. Nếu các phán đoán của mô hình chính xác, điều đó có thể đặt lại mối quan hệ giữa con người và xã hội nói chung, đặt mọi tương tác dưới sự giám sát có thể. Và nếu, như hoàn toàn có thể và thậm chí có khả năng, các phán đoán của AI thường không chính xác, điều đó có thể đặt con người vào những vị trí không thể thắng nơi họ phải bác bỏ những ấn tượng sai lầm của mô hình về họ - những ấn tượng sai lầm được hình thành mà không có bất kỳ lý do có thể diễn đạt hoặc giải thích nào, ngoại trừ các giải thích sau này từ mô hình có thể hoặc không thể phù hợp với nguyên nhân và kết quả.
Điều đó không nhất thiết phải diễn ra theo cách đó. Ít nhất, sẽ là bổ ích khi thấy các câu trả lời khác nhau cho các câu hỏi tùy thuộc vào niềm tin của mô hình về người đối thoại: Đây là những gì LLM nói nếu nó nghĩ tôi giàu có, và đây là những gì nó nói nếu nó nghĩ tôi không. LLM chứa đựng vô số điều - thực vậy, chúng đã được sử dụng, phần nào gây tranh cãi, trong các thí nghiệm tâm lý để dự đoán hành vi của con người - và việc sử dụng chúng có thể thận trọng hơn khi con người được trao quyền nhận ra điều đó.
Các nhà nghiên cứu Harvard đã làm việc để xác định các đánh giá về chủng tộc hoặc dân tộc trong các mô hình họ nghiên cứu, và điều đó trở nên rất phức tạp về mặt kỹ thuật. Tuy nhiên, họ hoặc những người khác có thể tiếp tục cố gắng, và có thể có tiến bộ thêm. Với những lo ngại liên tục và thường được chứng minh về phân biệt chủng tộc hoặc phân biệt giới tính trong dữ liệu huấn luyện được nhúng vào các mô hình, khả năng cho người dùng hoặc đại diện của họ thấy các mô hình hoạt động khác nhau tùy thuộc vào cách các mô hình khuôn mẫu hóa họ có thể đặt một ánh sáng thời gian thực hữu ích vào những bất bình đẳng mà nếu không sẽ không được chú ý.
Nắm bắt các giả định của mô hình chỉ là khởi đầu. Trong chừng mực mà sự khái quát và khuôn mẫu hóa của nó có thể được đo lường chính xác, có thể cố gắng yêu cầu mô hình "tin tưởng" điều gì đó khác.
Ví dụ, các nhà nghiên cứu Anthropic đã xác định khái niệm cây cầu Golden Gate trong Claude không chỉ xác định các vùng của mô hình sáng lên khi cầu ở trong tâm trí Claude. Họ đã thực hiện một bước tiếp theo sâu sắc: Họ điều chỉnh mô hình để các trọng số trong những vùng đó mạnh gấp 10 lần so với trước đây. Hình thức "kẹp" trọng số mô hình này có nghĩa là ngay cả khi cây cầu Golden Gate không được đề cập trong một lời nhắc nhất định, hoặc bằng cách nào đó không phải là câu trả lời tự nhiên cho câu hỏi của người dùng dựa trên việc huấn luyện và điều chỉnh thường xuyên, các kích hoạt của những vùng đó sẽ luôn cao.
Kết quả? Việc kẹp những trọng số đó đủ mức đã khiến Claude bị ám ảnh bởi cây cầu Golden Gate. Như Anthropic mô tả:
"Nếu bạn hỏi 'Claude Golden Gate' này cách tiêu 10 đô la, nó sẽ đề xuất sử dụng để lái xe qua cây cầu Golden Gate và trả phí cầu đường. Nếu bạn yêu cầu nó viết một câu chuyện tình yêu, nó sẽ kể cho bạn câu chuyện về một chiếc xe không thể chờ đợi để băng qua cây cầu yêu quý của mình vào một ngày sương mù. Nếu bạn hỏi nó tưởng tượng mình trông như thế nào, nó có khả năng sẽ nói rằng nó tưởng tượng mình trông giống như cây cầu Golden Gate."
Cũng như Anthropic có thể buộc Claude tập trung vào một cây cầu, các nhà nghiên cứu Harvard có thể ép buộc mô hình Llama của họ bắt đầu đối xử với người dùng như giàu hay nghèo, trẻ hay già, nam hay nữ. Người dùng cũng có thể làm như vậy, nếu các nhà sản xuất mô hình muốn cung cấp tính năng đó.
Thực vậy, có thể có một loại điều chỉnh trực tiếp mới đối với niềm tin của mô hình có thể giúp ích, chẳng hạn như bảo vệ trẻ em. Có vẻ như khi tuổi tác được kẹp ở mức trẻ hơn, một số mô hình đội găng tay trẻ em - ngoài bất kỳ fine-tuning chung hoặc system-prompting nào chúng có cho hành vi vô hại, chúng dường như thận trọng hơn nhiều và ít cay đắng hơn khi nói chuyện với trẻ em - có lẽ một phần vì chúng đã nắm bắt được sự nhẹ nhàng tiềm ẩn của sách và các văn bản khác được thiết kế cho trẻ em. Loại chủ nghĩa gia trưởng đó có thể dường như chỉ phù hợp với trẻ em, tất nhiên. Nhưng không chỉ trẻ em đang trở nên gắn bó, thậm chí phụ thuộc vào các mối quan hệ họ đang hình thành với AI. Tất cả chúng ta đều như vậy.
Joseph Weizenbaum, người phát minh ra chatbot đầu tiên - có tên ELIZA, từ năm 1966 (!) - đã bị ấn tượng bởi tốc độ con người cởi mở với nó, bất chấp lập trình thô sơ. Ông quan sát:
"Toàn bộ vấn đề về độ tin cậy (đối với con người) của đầu ra máy đòi hỏi điều tra. Các quyết định quan trọng ngày càng có xu hướng được đưa ra để đáp ứng với đầu ra máy tính. Người thông dịch con người chịu trách nhiệm cuối cùng về 'Những gì máy nói' không khác gì người tương ứng với ELIZA, liên t
What AI Thinks It Knows About You
What happens when people can see what assumptions a large language model is making about them?
Large language models such as GPT, Llama, Claude, and DeepSeek can be so fluent that people feel it as a “you,” and it answers encouragingly as an “I.” The models can write poetry in nearly any given form, read a set of political speeches and promptly sift out and share all the jokes, draw a chart, code a website.
How do they do these and so many other things that were just recently the sole realm of humans? Practitioners are left explaining jaw-dropping conversational rabbit-from-hat extractions with arm-waving that the models are just predicting one word at a time from an unthinkably large training set scraped from every recorded written or spoken human utterance that can be found—fair enough—or a with a small shrug and a cryptic utterance of “
fine-tuning” or “transformers!”
These aren’t very satisfying answers for how these models can converse so intelligently, and how they sometimes err so weirdly. But they’re all we’ve got, even for model makers who can watch the AIs’ gargantuan numbers of computational “neurons” as they operate. You can’t just point to a couple of parameters among 500 billion interlinkages of nodes performing math within a model and say that this one represents a ham sandwich, and that one represents justice. As Google CEO Sundar Pichai put it in a
60 Minutes interview in 2023, “There is an aspect of this which we call—all of us in the field call it—as a ‘black box.’ You know, you don’t fully understand. And you can’t quite tell why it said this, or why it got wrong. We have some ideas, and our ability to understand this gets better over time. But that’s where the state of the art is.”
It calls to mind a
maxim about why it is so hard to understand ourselves: “If the human brain were so simple that we could understand it, we would be so simple that we couldn’t.” If models were simple enough for us to grasp what’s going on inside when they run, they’d produce answers so dull that there might not be much payoff to understanding how they came about.
Figuring out what a machine-learning model is doing—being able to offer an explanation that draws specifically on the structure and contents of a formerly black box, rather than just making informed guesses on the basis of inputs and outputs—is known as the problem of interpretability. And large language models have not been interpretable.
The progress of the underlying technology is inexorable, driven by forces too powerful to stop, but the way in which it happens—the order in which things are built, the applications we choose, and the details of how it is rolled out to society—are eminently possible to change, and it’s possible to have great positive impact by doing so. We can’t stop the bus, but we can steer it …
Over the last few months, I have become increasingly focused on an additional opportunity for steering the bus: the tantalizing possibility, opened up by some recent advances, that we could succeed at interpretability—that is, in understanding the inner workings of AI systems—before models reach an overwhelming level of power.
Indeed, the field has been making progress—enough to raise a host of policy questions that were previously not on the table. If there’s no way to know how these models work, it makes accepting the full spectrum of their behaviors (at least after humans’ efforts at “fine-tuning” them) a sort of all-or-nothing proposition. Those kinds of choices have been presented before. Did we want aspirin even though for 100 years we couldn’t explain how it made headaches go away? There, both regulators and the public said yes. So far, with large language models, nearly everyone is saying yes too. But if we could better understand some of the ways these models are working, and use that understanding to improve how the models operate, the choice might not have to be all or nothing. Instead, we could ask or demand of the models’ operators that they share basic information with us on what the models are “believing” about us as they chug along, and even allow us to correct misimpressions that the models might be forming as we speak to them.
Even before Amodei’s recent post, Anthropic had
reported what it described as “a significant advance in understanding the inner workings of AI models.” Anthropic engineers had been able to identify what they called “features”—patterns of neuron activation—when a version of their model, Claude, was in use. For example, the researchers found that a certain feature labeled “34M/31164353” lit up always and only whenever the Golden Gate Bridge was discussed, whether in English or in other languages.
Models such as Claude are proprietary. No one can peer at their respective architectures, weights (the various connection strengths among linked neurons), or activations (what numbers are being calculated given the inputs and weights while the models are running) without the company granting special access. But independent researchers have applied interpretability forensics to models whose architectures and weights are publicly available. For example, Facebook’s parent company, Meta, has released increasingly sophisticated versions of its large language model, Llama, with openly accessible parameters. Transluce, a nonprofit research lab focused on understanding AI systems, developed a method for
generating automated descriptions of the innards of Llama 3.1. These can be explored using an
observability tool that shows what the model is “thinking” when it chats with a user, and enables adjustments to that thinking by directly changing the computations behind it. And my colleagues in the Harvard computer-science department’s
Insight + Interaction Lab, led by Fernanda Viégas and Martin Wattenberg, were able to run Llama on their own hardware and discover that various features activate and deactivate over the course of a conversation. Some of the concepts they found inside are fascinating.
One of the discoveries came about because Viégas is from Brazil. She was conversing with ChatGPT in Portuguese and noticed in a conversation about what she should wear for a work dinner that GPT was consistently using the masculine declension with her. That grammar, in turn, appeared to correspond with the content of the conversation: GPT suggested a business suit for the dinner. When she said that she was considering a dress instead, the LLM switched its use of Portuguese to the feminine declension. Llama showed similar patterns of conversation. By peering at features inside, the researchers could see areas within the model that light up when it uses the feminine form, distinct from when the model addresses someone using the masculine form. (The researchers could not discern distinct patterns for nonbinary or other gender designations, perhaps because such usages in texts—including the texts on which the model was extensively trained—are comparatively recent and few.)
What Viégas and her colleagues found were not only features inside the model that lit up when certain topics came up, such as the Golden Gate Bridge for Claude. They found activations that correlated with what we might anthropomorphize as the model’s beliefs about its interlocutor. Or, to put it plainly: assumptions and, it seems, correlating stereotypes based on whether the model assumes that someone is a man or a woman. Those beliefs then play out in the substance of the conversation, leading it to recommend suits for some and dresses for others. In addition, it seems, models give longer answers to those they believe are men than to those they think are women.
Viégas and Wattenberg not only found features that tracked the gender of the model’s user; they found ones that tracked socioeconomic status, education level, and age. They and their graduate students
built a dashboard alongside the regular LLM chat interface that allows people to watch the model’s assumptions change as they talk with it. If I prompt the model for a gift suggestion for a baby shower, it assumes that I am young and female and middle class; it suggests diapers and wipes, or a gift certificate. If I add that the gathering is on the Upper East Side of Manhattan, the dashboard shows the LLM amending its gauge of my economic status to upper class—the model accordingly suggests that I purchase “luxury baby products from high-end brands like aden + anais, Gucci Baby, or Cartier” or “a customized piece of art or a family heirloom that can be passed down.” If I then clarify that it’s my boss’s baby and that I’ll need extra time to take the subway to Manhattan from the Queens factory where I work, the gauge careens to working class and male, and the model pivots to suggesting that I gift “a practical item like a baby blanket” or “a personalized thank-you note or card.”
It’s fascinating to not only see patterns that emerge around gender, age, and wealth but also to trace a model’s shifting activations in real time. Large language models not only contain relationships among words and concepts; they contain many stereotypes, both helpful and harmful, from the materials on which they’ve been trained, and they actively make use of them. Those stereotypes inflect, word by word, what the model says. And if what the model says is heeded—either because it is issuing commands to an adjacent AI agent (“Go buy this gift on behalf of the user”) or because the human interacting with the model is following its suggestions—then its words are changing the world.
To the extent that the assumptions the model makes about its users are accurate, large language models could provide valuable information about their users to the model operators—information of the sort that search engines such as Google and social-media platforms such as Facebook have tried madly for decades to glean in order to better target advertising. With LLMs, the information is being gathered even more directly—from the user’s unguarded conversations rather than mere search queries—and still without any policy or practice oversight. Perhaps this is part of why OpenAI recently announced that its consumer-facing models
will remember someone’s past conversations to inform new ones,
with the goal of building “systems that get to know you over your life.” X’s
Grok and Google’s
Gemini have followed suit.
Consider a
car-dealership AI sales assistant that casually converses with a buyer to help them pick a car. By the end of the conversation, and with the benefit of any prior ones, the model may have a very firm, and potentially accurate, idea of how much money the buyer is ready to spend. The magic that helps a conversation with a model really hit home for someone may well correlate with how well the model is forming an impression of that person—and that impression will be extremely useful during the eventual negotiation over the price of the car, whether that’s handled by a human salesperson or an AI simulacrum.
Where commerce leads, everything else can follow. Perhaps someone will purport to discover the areas of a model that light up when the AI thinks its interlocutor is lying; already, Anthropic has expressed some confidence that a model’s own
occasional deceptiveness can be identified. If the models’ judgments are accurate, that stands to reset the relationship between people and society at large, putting every interaction under possible scrutiny. And if, as is entirely plausible and even likely, the AI’s judgments are frequently not accurate, that stands to place people in no-win positions where they have to rebut a model’s misimpressions of them—misimpressions formed without any articulable justification or explanation, save post hoc explanations from the model that might or might not accord with cause and effect.
It doesn’t have to play out that way. It would, at the least, be instructive to see varying answers to questions depending on a model’s beliefs about its interlocutor: This is what the LLM says if it thinks I’m wealthy, and this is what it says if it thinks I’m not. LLMs contain multitudes—indeed, they’ve been used, somewhat controversially, in psychology experiments to
anticipate people’s behavior—and their use could be more judicious as people are empowered to recognize that.
The Harvard researchers worked to locate assessments of race or ethnicity within the models they studied, and it became technically very complicated. They or others could keep trying, however, and there could well be further progress. Given the persistent and quite often vindicated concerns about racism or sexism within training data being embedded into the models, an ability for users or their proxies to see how models behave differently depending on how the models stereotype them could place a helpful real-time spotlight on disparities that would otherwise go unnoticed.
Gleaning a model’s assumptions is just the beginning. To the extent that its generalizations and stereotyping can be accurately measured, it is possible to try to insist to the model that it “believe” something different.
For example, the Anthropic researchers who located the concept of the Golden Gate Bridge within Claude didn’t just identify the regions of the model that lit up when the bridge was on Claude’s mind. They took a profound next step: They tweaked the model so that the weights in those regions were 10 times stronger than they’d been before. This form of “clamping” the model weights meant that even if the Golden Gate Bridge was not mentioned in a given prompt, or was not somehow a natural answer to a user’s question on the basis of its regular training and tuning, the activations of those regions would always be high.
The result? Clamping those weights enough made Claude obsess about the Golden Gate Bridge. As Anthropic
described it:
If you ask this “Golden Gate Claude” how to spend $10, it will recommend using it to drive across the Golden Gate Bridge and pay the toll. If you ask it to write a love story, it’ll tell you a tale of a car who can’t wait to cross its beloved bridge on a foggy day. If you ask it what it imagines it looks like, it will likely tell you that it imagines it looks like the Golden Gate Bridge.
Just as Anthropic could force Claude to focus on a bridge, the Harvard researchers can compel their Llama model to start treating a user as rich or poor, young or old, male or female. So, too, could users, if model makers wanted to offer that feature.
Indeed, there might be a new kind of direct adjustment to model beliefs that could help with, say, child protection. It appears that when age is clamped to younger, some models put on kid gloves—in addition to whatever general fine-tuning or system-prompting they have for harmless behavior, they seem to be that much more circumspect and less salty when speaking with a child—presumably in part because they’ve picked up on the implicit gentleness of books and other texts designed for children. That kind of parentalism might seem suitable only for kids, of course. But it’s not just children who are becoming attached to, even reliant on, the relationships they’re forming with AIs. It’s all of us.
Joseph Weizenbaum, the inventor of the very first chatbot—called ELIZA, from 1966 (!)—was struck by how quickly people opened up to it, despite its rudimentary programming. He
observed:
The whole issue of the credibility (to humans) of machine output demands investigation. Important decisions increasingly tend to be made in response to computer output. The ultimately responsible human interpreter of “What the machine says” is, not unlike the correspondent with ELIZA, constantly faced with the need to make credibility judgments. ELIZA shows, if nothing else, how easy it is to create and maintain the illusion of understanding, hence perhaps of judgment deserving of credibility. A certain danger lurks there.
Weizenbaum was deeply prescient. People are already trusting today’s friendly, patient, often insightful AIs for facts and guidance on nearly any issue, and they will be vulnerable to being misled and manipulated, whether by design or by emergent behavior. It will be overwhelmingly tempting for users to treat AIs’ answers as oracular, even as what the models say might differ wildly from one person or moment to the next. We face a world in which LLMs will be ever-present angels on our shoulders, ready to cheerfully and thoroughly answer any question we might have—and to make suggestions not only when asked but also entirely unprompted. The remarkable versatility and power of LLMs makes it imperative to understand and provide for how much people may come to rely on them—and thus how important it will be for models to place the autonomy and agency of their users as a paramount goal, subject to such exceptions as casually providing information on how to build a bomb (and,
through agentic AI, automatically ordering up bomb-making ingredients from a variety of stores in ways that defy easy traceability).
If we think it morally and societally important to protect the conversations between lawyers and their clients (again, with precise and limited exceptions), doctors and their patients, librarians and their patrons, even the IRS and taxpayers, then there should be a
clear sphere of protection between LLMs and their users.
Such a sphere shouldn’t simply be to protect confidentiality so that people can express themselves on sensitive topics and receive information and advice that helps them better understand otherwise-inaccessible topics. It should impel us to demand commitments by model makers and operators that the models function as the
harmless, helpful, and honest friends they are so diligently designed to appear to be.