AI xâm chiếm âm nhạc: Robot có thể sáng tác ca khúc làm bạn rơi nước mắt, ai mới là nghệ sĩ thật sự?
-
Công nghệ AI tạo sinh, đặc biệt là mô hình khuếch tán, nay đã có khả năng tạo ra bài hát hoàn chỉnh chỉ từ một đoạn mô tả, làm thay đổi căn bản khái niệm về sáng tạo và quyền tác giả trong âm nhạc.
-
Mô hình khuếch tán hoạt động bằng cách biến đổi nhiễu ngẫu nhiên thành các mẫu sóng âm có ý nghĩa, cho phép sinh ra nhạc có thể đánh lừa cả những người nghe tinh tường.
-
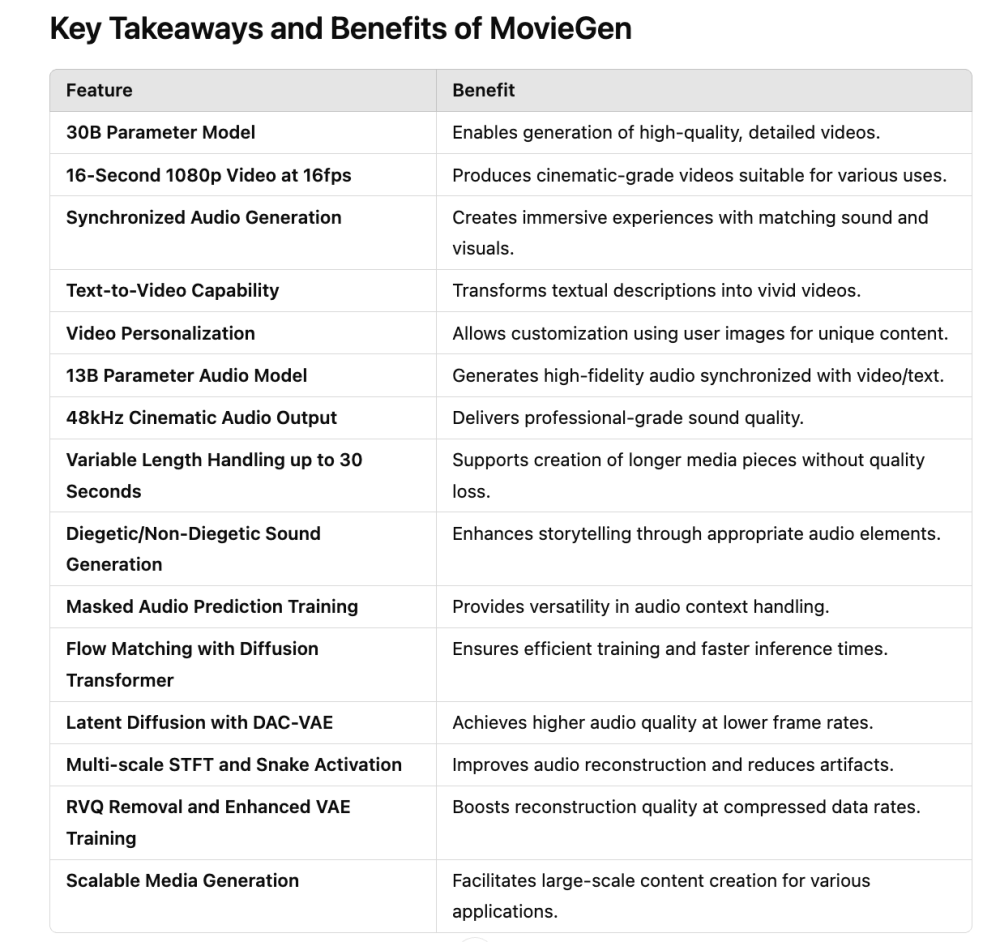
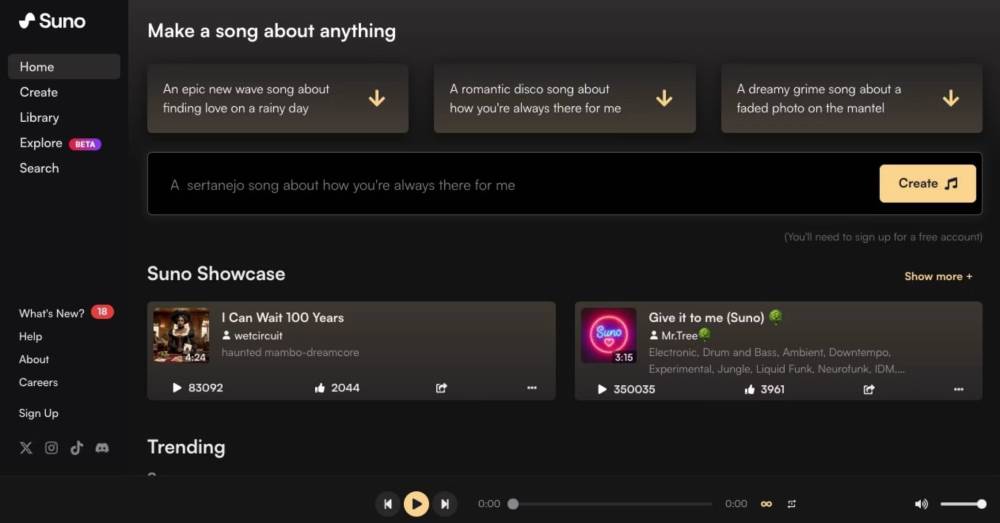
Hai công ty dẫn đầu lĩnh vực này là Suno (12 triệu người dùng, gọi vốn 125 triệu USD vào 05/2024) và Udio (gọi vốn 10 triệu USD vào 04/2024). Nhiều sản phẩm nhạc AI đã được tải lên các nền tảng, với người tạo là các "propmter" chứ không phải nhạc sĩ truyền thống.
-
Các hãng thu âm lớn như Universal và Sony kiện Suno, Udio vào 06/2024, cáo buộc họ sử dụng dữ liệu nhạc có bản quyền trên phạm vi "không tưởng", tạo ra các bản sao gần như thật.
-
Mô hình AI không “sáng tác” tuần tự mà tạo toàn bộ bản nhạc cùng lúc, dựa trên kho dữ liệu khổng lồ gồm hàng triệu đoạn nhạc được gán nhãn chi tiết (thể loại, tâm trạng, kỹ thuật hòa âm...).
-
Luật bản quyền Mỹ tạm thời cho phép tác phẩm AI được công nhận nếu có sự can thiệp đáng kể của con người, mở ra cuộc đua tranh pháp lý giữa sáng tạo thực sự và “sao chép” máy móc.
-
Thử nghiệm thực tế cho thấy người nghe khó phân biệt nhạc AI và nhạc người sáng tác, đặc biệt ở thể loại không lời. Đa số chỉ đúng 46% khi đoán bài hát do AI tạo ra.
-
Dù AI có thể tạo nhạc "rất thật", nhưng thiếu sự bất ngờ, khác thường kiểu nhân loại (ví dụ: cú twist trong giao hưởng của Beethoven). Nghệ sĩ thường “phóng đại điểm dị biệt”, điều mà máy học chủ yếu giảm sai số nên khó đạt được.
-
Các hệ thống AI phải liên tục học từ nhạc do người sáng tạo, nếu không sẽ tụt hậu và thiếu cập nhật.
-
Câu hỏi then chốt: liệu khán giả có còn trân trọng nhạc nếu biết do máy sáng tác? Kết quả thử nghiệm cho thấy nhiều người phản đối, dù cảm xúc vẫn bị nhạc AI chi phối.
📌 AI đang làm mờ ranh giới sáng tạo giữa người và máy trong âm nhạc: Suno và Udio mở rộng quy mô, mô hình khuếch tán tái tạo nhạc khó phân biệt với nhạc con người, gây tranh cãi pháp lý về bản quyền và định nghĩa nghệ sĩ, khi chỉ 46% người nghe phân biệt được nhạc AI.
https://www.technologyreview.com/2025/04/16/1114433/ai-artificial-intelligence-music-diffusion-creativity-songs-writer/
#MIT
AI đang tiến vào lĩnh vực âm nhạc
Các mô hình AI khuếch tán mới tạo ra bài hát từ đầu đang làm phức tạp định nghĩa của chúng ta về quyền tác giả và sáng tạo con người.
Tác giả: James O'Donnellarchive Ngày 16 tháng 4 năm 2025
Trí tuệ nhân tạo hầu như chưa phải là một thuật ngữ vào năm 1956, khi các nhà khoa học hàng đầu từ lĩnh vực điện toán đến Đại học Dartmouth cho một hội nghị mùa hè. Nhà khoa học máy tính John McCarthy đã đặt ra cụm từ này trong đề xuất tài trợ cho sự kiện, một cuộc họp để nghiên cứu cách xây dựng máy móc có thể sử dụng ngôn ngữ, giải quyết vấn đề như con người và tự cải thiện. Đó là một lựa chọn tốt, một cụm từ đã nắm bắt tiền đề nền tảng của người tổ chức: Bất kỳ tính năng nào của trí thông minh con người đều có thể "về nguyên tắc được mô tả chính xác đến mức một cỗ máy có thể được tạo ra để mô phỏng nó."
Trong đề xuất của họ, nhóm đã liệt kê một số "khía cạnh của vấn đề trí tuệ nhân tạo." Mục cuối cùng trong danh sách của họ, và nhìn lại có lẽ là khó khăn nhất, là xây dựng một cỗ máy có thể thể hiện sự sáng tạo và tính nguyên bản.
Vào thời điểm đó, các nhà tâm lý học đang đấu tranh với việc định nghĩa và đo lường sự sáng tạo ở con người. Lý thuyết phổ biến - cho rằng sự sáng tạo là sản phẩm của trí thông minh và chỉ số IQ cao - đang mờ nhạt, nhưng các nhà tâm lý học không chắc chắn nên thay thế nó bằng gì. Những người tổ chức Dartmouth có một ý tưởng riêng. "Sự khác biệt giữa tư duy sáng tạo và tư duy có năng lực kém tưởng tượng nằm ở việc đưa vào một số yếu tố ngẫu nhiên," họ viết, thêm rằng sự ngẫu nhiên đó "phải được dẫn dắt bởi trực giác để có hiệu quả."
Gần 70 năm sau, sau một số chu kỳ bùng nổ và suy thoái trong lĩnh vực này, chúng ta hiện có các mô hình AI ít nhiều tuân theo công thức đó. Trong khi các mô hình ngôn ngữ lớn tạo ra văn bản đã bùng nổ trong ba năm qua, một loại AI khác, dựa trên cái gọi là mô hình khuếch tán, đang có tác động chưa từng có đến các lĩnh vực sáng tạo. Bằng cách biến đổi nhiễu ngẫu nhiên thành các mẫu mạch lạc, các mô hình khuếch tán có thể tạo ra hình ảnh, video hoặc giọng nói mới, được hướng dẫn bởi các gợi ý văn bản hoặc dữ liệu đầu vào khác. Những mô hình tốt nhất có thể tạo ra các đầu ra không thể phân biệt được với công việc của con người, cũng như các kết quả kỳ lạ, siêu thực có cảm giác khác biệt phi nhân loại.
Giờ đây, các mô hình này đang tiến vào một lĩnh vực sáng tạo có lẽ dễ bị gián đoạn hơn bất kỳ lĩnh vực nào khác: âm nhạc. Các tác phẩm sáng tạo do AI tạo ra - từ buổi biểu diễn dàn nhạc đến nhạc heavy metal - sẵn sàng thâm nhập vào cuộc sống của chúng ta triệt để hơn bất kỳ sản phẩm nào khác của AI từng làm trước đây. Các bài hát có khả năng hòa lẫn vào nền tảng phát trực tuyến, danh sách phát cho bữa tiệc và đám cưới, nhạc nền và nhiều thứ khác của chúng ta, cho dù chúng ta có nhận thấy ai (hoặc cái gì) đã tạo ra chúng hay không.
Trong nhiều năm, các mô hình khuếch tán đã khuấy động cuộc tranh luận trong thế giới nghệ thuật thị giác về việc liệu những gì chúng tạo ra có phản ánh sự sáng tạo thực sự hay chỉ đơn thuần là sự sao chép. Giờ đây, cuộc tranh luận này đã đến với âm nhạc, một hình thức nghệ thuật gắn bó sâu sắc với trải nghiệm, ký ức và đời sống xã hội của chúng ta. Các mô hình âm nhạc hiện nay có thể tạo ra những bài hát có khả năng gợi ra những phản ứng cảm xúc thực sự, đưa ra một ví dụ rõ ràng về việc định nghĩa quyền tác giả và tính nguyên bản trong thời đại AI đang trở nên khó khăn như thế nào.
Các tòa án đang tích cực giải quyết lãnh thổ mơ hồ này. Các hãng thu âm lớn đang kiện các công cụ tạo nhạc AI hàng đầu, cáo buộc rằng các mô hình khuếch tán làm ít hơn việc sao chép nghệ thuật của con người mà không bồi thường cho các nghệ sĩ. Các nhà sản xuất mô hình phản bác rằng công cụ của họ được tạo ra để hỗ trợ sáng tạo của con người.
Khi quyết định ai đúng, chúng ta buộc phải suy nghĩ kỹ về sự sáng tạo của chính con người. Sự sáng tạo, dù trong mạng thần kinh nhân tạo hay sinh học, có phải chỉ đơn giản là kết quả của việc học thống kê rộng lớn và các kết nối được rút ra, với một chút ngẫu nhiên? Nếu vậy, thì quyền tác giả là một khái niệm không rõ ràng. Nếu không - nếu có một yếu tố đặc biệt của con người đối với sự sáng tạo - thì đó là gì? Điều gì có nghĩa là bị lay động bởi điều gì đó mà không có người sáng tạo là con người? Tôi đã phải đấu tranh với những câu hỏi này lần đầu tiên khi nghe một bài hát do AI tạo ra thực sự tuyệt vời - thật khó chịu khi biết rằng ai đó chỉ viết một gợi ý và nhấp vào "Tạo". Tình huống khó xử đó sắp đến với bạn.
Tạo kết nối
Sau hội nghị Dartmouth, những người tham gia đã đi theo các hướng nghiên cứu khác nhau để tạo ra các công nghệ nền tảng của AI. Đồng thời, các nhà khoa học nhận thức đang theo dõi lời kêu gọi năm 1950 của J.P. Guilford, chủ tịch Hiệp hội Tâm lý học Hoa Kỳ, để giải quyết câu hỏi về sự sáng tạo ở con người. Họ đã đi đến một định nghĩa, được Morris Stein chính thức hóa lần đầu tiên vào năm 1953 trong Tạp chí Tâm lý học: Các tác phẩm sáng tạo vừa mới lạ, có nghĩa là chúng trình bày điều gì đó mới, vừa hữu ích, có nghĩa là chúng phục vụ một số mục đích cho ai đó. Một số người đã kêu gọi thay thế "hữu ích" bằng "thỏa mãn", và những người khác đã đưa ra một tiêu chí thứ ba: rằng những điều sáng tạo cũng gây bất ngờ.
Sau đó, vào những năm 1990, sự ra đời của chụp cộng hưởng từ chức năng đã làm cho việc nghiên cứu thêm về các cơ chế thần kinh cơ bản của sự sáng tạo trong nhiều lĩnh vực, bao gồm cả âm nhạc, trở nên khả thi. Các phương pháp tính toán trong những năm gần đây cũng giúp dễ dàng hơn trong việc lập bản đồ vai trò mà trí nhớ và tư duy liên tưởng đóng trong các quyết định sáng tạo.
Điều xuất hiện ít là một lý thuyết thống nhất về cách một ý tưởng sáng tạo bắt nguồn và diễn ra trong não, mà là một danh sách các quan sát mạnh mẽ ngày càng tăng. Trước tiên, chúng ta có thể chia quá trình sáng tạo của con người thành các giai đoạn, bao gồm bước đề xuất ý tưởng, sau đó là bước đánh giá và phê bình hơn để tìm ra giá trị trong ý tưởng. Một lý thuyết hàng đầu về những gì hướng dẫn hai giai đoạn này được gọi là lý thuyết liên tưởng về sự sáng tạo, lý thuyết này cho rằng những người sáng tạo nhất có thể hình thành các kết nối mới giữa các khái niệm xa nhau.
"Nó có thể giống như sự hoạt hóa lan truyền," Roger Beaty, một nhà nghiên cứu dẫn đầu Phòng thí nghiệm Khoa học thần kinh nhận thức về Sáng tạo tại Đại học Bang Penn cho biết. "Bạn nghĩ về một điều; nó chỉ kích hoạt các khái niệm liên quan đến bất kỳ khái niệm nào đó."
Những kết nối này thường dựa đặc biệt vào bộ nhớ ngữ nghĩa, lưu trữ các khái niệm và sự kiện, trái ngược với bộ nhớ biểu tượng, lưu trữ ký ức từ một thời gian và địa điểm cụ thể. Gần đây, các mô hình tính toán phức tạp hơn đã được sử dụng để nghiên cứu cách mọi người tạo kết nối giữa các khái niệm trên "khoảng cách ngữ nghĩa" lớn. Ví dụ, từ "tận thế" có liên quan chặt chẽ hơn đến "năng lượng hạt nhân" so với "lễ kỷ niệm". Các nghiên cứu đã chỉ ra rằng những người có tính sáng tạo cao có thể nhận thức các khái niệm rất khác biệt về mặt ngữ nghĩa là gần nhau. Người ta phát hiện ra rằng các nghệ sĩ tạo ra những liên tưởng từ ngữ trên khoảng cách lớn hơn so với những người không phải nghệ sĩ. Nghiên cứu khác đã hỗ trợ ý tưởng rằng những người sáng tạo có sự chú ý "rò rỉ" - nghĩa là họ thường chú ý đến thông tin có thể không đặc biệt liên quan đến nhiệm vụ trước mắt của họ.
Các phương pháp khoa học thần kinh để đánh giá các quá trình này không cho thấy rằng sự sáng tạo diễn ra trong một khu vực cụ thể của não. "Không có gì trong não tạo ra sự sáng tạo giống như một tuyến tiết ra một hormone," Dean Keith Simonton, một nhà lãnh đạo trong nghiên cứu sáng tạo, đã viết trong Sổ tay Cambridge về Khoa học thần kinh của Sáng tạo.
Bằng chứng thay vào đó chỉ ra một vài mạng lưới hoạt động phân tán trong quá trình suy nghĩ sáng tạo, Beaty nói - một để hỗ trợ việc tạo ra ý tưởng ban đầu thông qua tư duy liên tưởng, một khác liên quan đến việc xác định ý tưởng hứa hẹn, và một khác nữa để đánh giá và sửa đổi. Một nghiên cứu mới, do các nhà nghiên cứu tại Trường Y Harvard dẫn đầu và được công bố vào tháng 2, cho thấy rằng sự sáng tạo thậm chí có thể liên quan đến việc ức chế các mạng não cụ thể, như những mạng liên quan đến tự kiểm duyệt.
Cho đến nay, sự sáng tạo của máy - nếu bạn có thể gọi nó như vậy - có vẻ khá khác biệt. Mặc dù vào thời điểm hội nghị Dartmouth, các nhà nghiên cứu AI quan tâm đến máy móc lấy cảm hứng từ não người, trọng tâm đó đã thay đổi vào thời điểm các mô hình khuếch tán được phát minh, khoảng một thập kỷ trước.
Manh mối tốt nhất về cách chúng hoạt động nằm trong tên gọi. Nếu bạn nhúng một cây cọ sơn đầy mực đỏ vào một lọ thủy tinh nước, mực sẽ khuếch tán và xoáy vào nước dường như ngẫu nhiên, cuối cùng tạo ra một chất lỏng màu hồng nhạt. Các mô hình khuếch tán mô phỏng quá trình này ngược lại, tái tạo các hình thức dễ đọc từ sự ngẫu nhiên.
Để hiểu cách điều này hoạt động đối với hình ảnh, hãy tưởng tượng một bức ảnh về một con voi. Để huấn luyện mô hình, bạn tạo một bản sao của bức ảnh, thêm một lớp nhiễu đen trắng ngẫu nhiên lên trên. Tạo bản sao thứ hai và thêm nhiều hơn một chút, và cứ tiếp tục hàng trăm lần cho đến khi hình ảnh cuối cùng là nhiễu thuần túy, không thấy con voi. Đối với mỗi hình ảnh ở giữa, một mô hình thống kê dự đoán bao nhiêu trong hình ảnh là nhiễu và bao nhiêu thực sự là con voi. Nó so sánh những đoán của mình với câu trả lời đúng và học hỏi từ những sai lầm của mình. Qua hàng triệu ví dụ như vậy, mô hình ngày càng giỏi hơn trong việc "khử nhiễu" hình ảnh và kết nối các mẫu này với các mô tả như "voi đực Borneo trên một cánh đồng mở."
Giờ đây khi đã được huấn luyện, việc tạo ra một hình ảnh mới có nghĩa là đảo ngược quy trình này. Nếu bạn đưa cho mô hình một gợi ý, như "một con đười ươi hạnh phúc trong một khu rừng rêu phong", nó tạo ra một hình ảnh nhiễu trắng ngẫu nhiên và làm việc ngược lại, sử dụng mô hình thống kê của nó để loại bỏ các bit nhiễu từng bước một. Lúc đầu, các hình dạng và màu sắc thô xuất hiện. Chi tiết đến sau, và cuối cùng (nếu nó hoạt động) một con đười ươi xuất hiện, tất cả mà không cần mô hình "biết" đười ươi là gì.
Hình ảnh âm nhạc
Cách tiếp cận hoạt động tương tự đối với âm nhạc. Một mô hình khuếch tán không "sáng tác" một bài hát theo cách một ban nhạc có thể, bắt đầu với các hợp âm piano và thêm giọng hát và trống. Thay vào đó, tất cả các yếu tố được tạo ra cùng một lúc. Quá trình này dựa trên thực tế là nhiều phức tạp của một bài hát có thể được mô tả trực quan trong một dạng sóng duy nhất, đại diện cho biên độ của sóng âm được vẽ theo thời gian.
Hãy nghĩ về một máy hát đĩa. Bằng cách di chuyển dọc theo một rãnh trong một miếng vinyl, một cây kim bắt chước đường đi của sóng âm được khắc trong vật liệu và truyền nó thành tín hiệu cho loa. Loa chỉ đơn giản đẩy không khí ra theo những mẫu này, tạo ra sóng âm truyền tải toàn bộ bài hát.
Từ xa, một dạng sóng có thể trông như thể nó chỉ theo dõi âm lượng của một bài hát. Nhưng nếu bạn phóng to đủ gần, bạn có thể thấy các mẫu trong các đỉnh và thung lũng, như 49 sóng mỗi giây cho một cây guitar bass chơi nốt G thấp. Một dạng sóng chứa tổng hợp của tần số của tất cả các nhạc cụ và kết cấu khác nhau. "Bạn thấy một số hình dạng nhất định bắt đầu xuất hiện," David Ding, đồng sáng lập công ty âm nhạc AI Udio, nói, "và điều đó phần nào tương ứng với ý thức giai điệu rộng."
Vì dạng sóng, hoặc các biểu đồ tương tự được gọi là phổ đồ, có thể được coi như hình ảnh, bạn có thể tạo một mô hình khuếch tán từ chúng. Một mô hình được cung cấp hàng triệu đoạn clip của các bài hát hiện có, mỗi bài được gắn nhãn với một mô tả. Để tạo ra một bài hát mới, nó bắt đầu với nhiễu ngẫu nhiên thuần túy và làm việc ngược lại để tạo ra một dạng sóng mới. Con đường nó thực hiện để làm điều này được định hình bởi những từ mà ai đó đưa vào gợi ý.
Ding đã làm việc tại Google DeepMind trong 5 năm với tư cách là kỹ sư nghiên cứu cấp cao về các mô hình khuếch tán cho hình ảnh và video, nhưng anh đã rời đi để thành lập Udio, có trụ sở tại New York, vào năm 2023. Công ty và đối thủ cạnh tranh Suno, có trụ sở tại Cambridge, Massachusetts, hiện đang dẫn đầu cuộc đua cho các mô hình tạo nhạc. Cả hai đều nhằm mục đích xây dựng các công cụ AI cho phép những người không phải nhạc sĩ tạo nhạc. Suno lớn hơn, tuyên bố có hơn 12 triệu người dùng, và huy động được vòng gọi vốn 125 triệu USD vào tháng 5 năm 2024. Công ty đã hợp tác với các nghệ sĩ bao gồm Timbaland. Udio đã huy động được vòng gọi vốn hạt giống 10 triệu USD vào tháng 4 năm 2024 từ các nhà đầu tư nổi tiếng như Andreessen Horowitz cũng như các nhạc sĩ Will.i.am và Common.
Kết quả của Udio và Suno cho đến nay cho thấy có một lượng khán giả đáng kể có thể không quan tâm liệu âm nhạc họ nghe có được làm bởi con người hay máy móc. Suno có các trang nghệ sĩ cho những người sáng tạo, một số có lượng theo dõi lớn, những người tạo ra bài hát hoàn toàn bằng AI, thường đi kèm với hình ảnh nghệ sĩ được tạo ra bởi AI. Những người sáng tạo này không phải là nhạc sĩ theo nghĩa thông thường mà là những người gợi ý có kỹ năng, tạo ra tác phẩm không thể gán cho một nhà soạn nhạc hoặc ca sĩ duy nhất. Trong không gian mới nổi này, các định nghĩa thông thường của chúng ta về quyền tác giả - và ranh giới giữa sáng tạo và sao chép - gần như tan biến.
Ngành công nghiệp âm nhạc đang đẩy lùi. Cả hai công ty đều bị các hãng thu âm lớn kiện vào tháng 6 năm 2024, và các vụ kiện vẫn đang tiếp diễn. Các hãng, bao gồm Universal và Sony, cáo buộc rằng các mô hình AI đã được huấn luyện trên âm nhạc có bản quyền "ở quy mô gần như không thể tưởng tượng được" và tạo ra các bài hát "bắt chước các phẩm chất của bản ghi âm thanh con người thực sự" (vụ kiện chống lại Suno trích dẫn một bài hát gần với ABBA có tên là "Prancing Queen", ví dụ).
Suno không phản hồi yêu cầu bình luận về vụ kiện, nhưng trong một tuyên bố đáp lại vụ việc được đăng trên blog của Suno vào tháng 8, CEO Mikey Shulman nói rằng công ty huấn luyện trên âm nhạc tìm thấy trên internet mở, "thực sự chứa các tài liệu có bản quyền." Nhưng, ông lập luận, "học tập không phải là vi phạm."
Một đại diện từ Udio nói rằng công ty sẽ không bình luận về vụ kiện đang chờ xử lý. Vào thời điểm vụ kiện, Udio đã phát hành một tuyên bố đề cập rằng mô hình của họ có các bộ lọc để đảm bảo rằng nó "không tái tạo các tác phẩm có bản quyền hoặc giọng nói của nghệ sĩ."
Làm phức tạp vấn đề hơn nữa là hướng dẫn từ Văn phòng Bản quyền Hoa Kỳ, được phát hành vào tháng 1, cho biết các tác phẩm do AI tạo ra có thể được cấp bản quyền nếu chúng liên quan đến một lượng đáng kể đầu vào của con người. Một tháng sau, một nghệ sĩ ở New York đã nhận được có thể là bản quyền đầu tiên cho một tác phẩm nghệ thuật thị giác được tạo ra với sự trợ giúp của AI. Bài hát đầu tiên có thể là tiếp theo.
Tính mới lạ và bắt chước
Các vụ kiện pháp lý này lội vào một khu vực xám tương tự với khu vực được khám phá bởi các trận chiến tòa án khác đang diễn ra trong AI. Vấn đề ở đây là liệu việc huấn luyện các mô hình AI trên nội dung có bản quyền có được phép hay không, và liệu các bài hát được tạo ra có sao chép phong cách của một nghệ sĩ con người một cách không công bằng hay không.
Nhưng âm nhạc AI có khả năng sẽ phát triển dưới một số hình thức bất kể các quyết định của tòa án này; YouTube được cho là đã đàm phán với các hãng lớn để cấp phép âm nhạc của họ cho việc huấn luyện AI, và việc mở rộng gần đây các thỏa thuận của Meta với Universal Music Group cho thấy rằng việc cấp phép cho âm nhạc do AI tạo ra có thể nằm trên bàn.
Nếu âm nhạc AI là để tồn tại, liệu bất kỳ bài hát nào trong số đó có tốt không? Hãy xem xét ba yếu tố: dữ liệu huấn luyện, chính mô hình khuếch tán và việc gợi ý. Mô hình chỉ có thể tốt như thư viện âm nhạc mà nó học từ đó và các mô tả về âm nhạc đó, phải phức tạp để nắm bắt nó tốt. Kiến trúc của một mô hình sau đó xác định mức độ tốt của nó có thể sử dụng những gì đã được học để tạo ra bài hát. Và gợi ý bạn đưa vào mô hình - cũng như mức độ mà mô hình "hiểu" ý bạn khi nói "hạ thấp saxophone đó," ví dụ - cũng rất quan trọng.
Liệu kết quả là sự sáng tạo hay đơn giản chỉ là sao chép dữ liệu huấn luyện? Chúng ta có thể đặt câu hỏi tương tự về sự sáng tạo của con người.
Có lẽ vấn đề quan trọng nhất là vấn đề đầu tiên: Dữ liệu huấn luyện rộng rãi và đa dạng như thế nào, và nó được gắn nhãn tốt ra sao? Cả Suno và Udio đều chưa tiết lộ những bài hát nào đã nằm trong tập dữ liệu huấn luyện của họ, mặc dù những chi tiết này có thể sẽ phải được tiết lộ trong quá trình kiện tụng.
Udio cho biết cách những bài hát đó được gắn nhãn là rất quan trọng đối với mô hình. "Một lĩnh vực nghiên cứu tích cực của chúng tôi là: Làm thế nào để chúng tôi có được các mô tả âm nhạc ngày càng tinh chỉnh hơn?" Ding nói. Một mô tả cơ bản sẽ xác định thể loại, nhưng sau đó bạn cũng có thể nói liệu một bài hát có buồn, nâng cao tinh thần, hay bình tĩnh. Các mô tả kỹ thuật hơn có thể đề cập đến tiến trình hợp âm hai-năm-một hoặc một thang âm cụ thể. Udio cho biết họ thực hiện điều này thông qua sự kết hợp của máy móc và gắn nhãn bởi con người.
"Vì chúng tôi muốn nhắm đến một phạm vi rộng của người dùng mục tiêu, điều đó cũng có nghĩa là chúng tôi cần một phạm vi rộng của người chú thích âm nhạc," ông nói. "Không chỉ những người có bằng tiến sĩ âm nhạc, những người có thể mô tả âm nhạc ở mức độ kỹ thuật rất cao, mà còn cả những người yêu thích âm nhạc, những người có vốn từ vựng không chính thức riêng của họ để mô tả âm nhạc."
Các công cụ tạo nhạc AI cạnh tranh cũng phải học hỏi từ nguồn cung cấp liên tục các bài hát mới được tạo ra bởi con người, nếu không thì đầu ra của chúng sẽ bị mắc kẹt trong thời gian, nghe có vẻ cũ kỹ và lỗi thời. Vì điều này, âm nhạc do AI tạo ra ngày nay phụ thuộc vào nghệ thuật do con người tạo ra. Tuy nhiên, trong tương lai, các mô hình âm nhạc AI có thể huấn luyện trên đầu ra của chính chúng, một cách tiếp cận đang được thử nghiệm trong các lĩnh vực AI khác.
Bởi vì các mô hình bắt đầu với một lấy mẫu ngẫu nhiên của nhiễu, chúng không xác định; đưa cùng một gợi ý cho cùng một mô hình AI sẽ dẫn đến một bài hát mới mỗi lần. Đó cũng là vì nhiều nhà sản xuất của các mô hình khuếch tán, bao gồm cả Udio, đưa thêm tính ngẫu nhiên vào quy trình - về cơ bản là lấy dạng sóng được tạo ra ở mỗi bước và làm biến dạng nó một chút với hy vọng thêm vào những khiếm khuyết phục vụ để làm cho đầu ra thú vị hơn hoặc thực tế hơn. Chính những người tổ chức hội nghị Dartmouth đã đề xuất một chiến thuật như vậy trở lại năm 1956.
Theo Andrew Sanchez, đồng sáng lập và giám đốc vận hành của Udio, chính sự ngẫu nhiên vốn có trong các chương trình AI tạo sinh làm cho nhiều người ngạc nhiên. Trong 70 năm qua, máy tính đã thực hiện các chương trình xác định: Đưa cho phần mềm một đầu vào và nhận được cùng một phản hồi mỗi lần.
"Nhiều đối tác nghệ sĩ của chúng tôi sẽ hỏi, 'Tại sao nó làm điều này?'" ông nói. "Chúng tôi trả lời, chà, chúng tôi thực sự không biết." Thời đại tạo sinh đòi hỏi một tư duy mới, ngay cả đối với các công ty tạo ra nó: rằng các chương trình AI có thể lộn xộn và khó hiểu.
Liệu kết quả là sự sáng tạo hay đơn giản chỉ là sao chép dữ liệu huấn luyện? Những người hâm mộ âm nhạc AI nói với tôi rằng chúng ta có thể đặt câu hỏi tương tự về sự sáng tạo của con người. Khi chúng ta nghe nhạc trong suốt thời niên thiếu, các cơ chế thần kinh cho việc học tập được cân nhắc bởi những đầu vào này, và ký ức về những bài hát này ảnh hưởng đến đầu ra sáng tạo của chúng ta. Trong một nghiên cứu gần đây, Anthony Brandt, một nhà soạn nhạc và giáo sư âm nhạc tại Đại học Rice, đã chỉ ra rằng cả con người và các mô hình ngôn ngữ lớn đều sử dụng kinh nghiệm quá khứ để đánh giá các kịch bản tương lai có thể và đưa ra lựa chọn tốt hơn.
Thật vậy, phần lớn nghệ thuật của con người, đặc biệt là trong âm nhạc, đều được vay mượn. Điều này thường dẫn đến kiện tụng, với các nghệ sĩ cáo buộc rằng một bài hát đã được sao chép hoặc lấy mẫu mà không có sự cho phép. Một số nghệ sĩ đề xuất rằng các mô hình khuếch tán nên được làm cho minh bạch hơn, để chúng ta có thể biết rằng nguồn cảm hứng của một bài hát cụ thể là ba phần David Bowie và một phần Lou Reed. Udio cho biết có nghiên cứu đang diễn ra để đạt được điều này, nhưng hiện tại, không ai có thể làm điều đó một cách đáng tin cậy.
Đối với các nghệ sĩ tuyệt vời, "có sự kết hợp giữa tính mới mẻ và ảnh hưởng đang hoạt động," Sanchez nói. "Và tôi nghĩ rằng đó là điều gì đó cũng đang hoạt động trong các công nghệ này."
Nhưng có rất nhiều lĩnh vực mà các nỗ lực để so sánh mạng thần kinh con người với mạng thần kinh nhân tạo nhanh chóng đổ vỡ dưới sự xem xét kỹ lưỡng. Brandt phân định một lĩnh vực mà ông thấy sự sáng tạo của con người rõ ràng vượt trội hơn so với các sản phẩm được máy tạo ra: cái mà ông gọi là "khuếch đại điều bất thường." Các mô hình AI hoạt động trong lĩnh vực của lấy mẫu thống kê. Chúng không hoạt động bằng cách nhấn mạnh điều ngoại lệ mà, ngược lại, bằng cách giảm lỗi và tìm kiếm các mẫu có khả năng. Con người, mặt khác, lại bị thu hút bởi những điều kỳ quặc. "Thay vì được coi là sự kiện lạ lùng hoặc 'đơn lẻ'," Brandt viết, điều kỳ quặc "thấm nhuần sản phẩm sáng tạo."
Ông trích dẫn quyết định của Beethoven thêm một nốt nhạc không hòa âm đột ngột vào chuyển động cuối cùng của Giao hưởng số 8 của ông. "Beethoven có thể đã dừng lại ở đó," Brandt nói. "Nhưng thay vì coi đó là một sự kiện đơn lẻ, Beethoven tiếp tục tham chiếu đến sự kiện không phù hợp này theo nhiều cách khác nhau. Khi làm như vậy, nhà soạn nhạc lấy một sự sai lệch nhất thời và phóng đại tác động của nó." Người ta có thể nhìn vào những điều bất thường tương tự trong việc lấy mẫu vòng lặp ngược của các bản ghi âm Beatles cuối cùng, giọng hát được nâng cao từ Frank Ocean, hoặc việc kết hợp "âm thanh tìm thấy", như bản ghi âm của tín hiệu qua đường hoặc tiếng đóng cửa, được ưa thích bởi các nghệ sĩ như Charlie Puth và nhà sản xuất của Billie Eilish, Finneas O'Connell.
Nếu một đầu ra sáng tạo thực sự được định nghĩa là một đầu ra vừa mới lạ vừa hữu ích, cách diễn giải của Brandt cho thấy rằng các máy móc có thể đã sánh ngang với chúng ta về tiêu chí thứ hai trong khi con người thống trị tối cao về tiêu chí đầu tiên.
Để khám phá liệu điều đó có đúng không, tôi đã dành vài ngày để thử nghiệm với mô hình của Udio. Mất một hoặc hai phút để tạo ra một mẫu 30 giây, nhưng nếu bạn có các phiên bản trả phí của mô hình, bạn có thể tạo ra toàn bộ bài hát. Tôi quyết định chọn 12 thể loại, tạo ra một mẫu bài hát cho mỗi thể loại, và sau đó tìm những bài hát tương tự được tạo ra bởi con người. Tôi đã xây dựng một bài kiểm tra để xem liệu những người trong tòa soạn của chúng tôi có thể phát hiện ra bài hát nào được tạo ra bởi AI.
Điểm trung bình là 46%. Và đối với một số thể loại, đặc biệt là các thể loại nhạc cụ, người nghe thường sai nhiều hơn đúng. Khi tôi xem mọi người làm bài kiểm tra trước mặt tôi, tôi nhận thấy rằng những phẩm chất mà họ tự tin gắn cờ là dấu hiệu của sáng tác bởi AI - một nhạc cụ nghe có vẻ giả, một lời bài hát kỳ lạ - hiếm khi chứng minh họ đúng. Có thể đoán trước được, mọi người thực hiện kém hơn trong các thể loại mà họ ít quen thuộc; một số làm tốt với nhạc country hoặc soul, nhưng nhiều người không có cơ hội chống lại jazz, piano cổ điển, hoặc pop. Beaty, nhà nghiên cứu sáng tạo, đạt điểm 66%, trong khi Brandt, nhà soạn nhạc, kết thúc ở mức 50% (mặc dù ông đã trả lời đúng trong các bài kiểm tra dàn nhạc và sonata piano).
Hãy nhớ rằng mô hình không xứng đáng với tất cả các công lao ở đây; các đầu ra này không thể được tạo ra mà không có công việc của các nghệ sĩ con người có tác phẩm nằm trong dữ liệu huấn luyện. Nhưng chỉ với một vài gợi ý, mô hình đã tạo ra những bài hát mà ít người sẽ nhận ra là do máy tạo ra. Một vài bài có thể dễ dàng được phát tại một buổi tiệc mà không gây ra phản đối, và tôi thấy hai bài mà tôi thực sự yêu thích, ngay cả khi tôi là một nhạc sĩ suốt đời và nói chung là một người khó tính về âm nhạc. Nhưng nghe có vẻ thật không giống như nghe có vẻ nguyên bản. Các bài hát dường như không bị chi phối bởi những điều kỳ quặc hoặc bất thường - chắc chắn không ở mức độ "cú sốc" của Beethoven. Chúng cũng dường như không bẻ cong thể loại hoặc bao gồm những bước nhảy vọt lớn giữa các chủ đề. Trong bài kiểm tra của tôi, mọi người đôi khi khó quyết định liệu một bài hát có được AI tạo ra hay đơn giản là không hay.
Điều này sẽ quan trọng như thế nào trong cuối cùng? Các tòa án sẽ đóng một vai trò trong việc quyết định liệu các mô hình âm nhạc AI phục vụ các bản sao chép hay các sáng tạo mới - và các nghệ sĩ được bồi thường như thế nào trong quá trình này - nhưng chúng ta, với tư cách là người nghe, sẽ quyết định giá trị văn hóa của chúng. Để đánh giá cao một bài hát, chúng ta có cần tưởng tượng một nghệ sĩ con người đứng sau nó - người nào đó có kinh nghiệm, tham vọng, ý kiến? Một bài hát tuyệt vời có còn tuyệt vời nữa không nếu chúng ta phát hiện ra rằng nó là sản phẩm của AI?
Sanchez nói mọi người có thể tự hỏi ai đứng sau âm nhạc. Nhưng "cuối cùng, dù có bao nhiêu thành phần AI, bao nhiêu thành phần con người, nó sẽ là nghệ thuật," ông nói. "Và mọi người sẽ phản ứng với nó dựa trên chất lượng của giá trị thẩm mỹ của nó."
Tuy nhiên, trong thí nghiệm của tôi, tôi thấy rằng câu hỏi thực sự quan trọng đối với mọi người - và một số người quyết liệt phản đối ý tưởng thưởng thức âm nhạc được tạo ra bởi một mô hình máy tính. Khi một trong những người thử nghiệm của tôi bản năng bắt đầu gật đầu theo một bài hát electro-pop trong bài kiểm tra, khuôn mặt cô ấy thể hiện sự nghi ngờ. Gần như nếu cô ấy đang cố gắng hết sức để tưởng tượng một con người chứ không phải một cỗ máy là nhà soạn nhạc của bài hát. "Trời ơi," cô ấy nói, "tôi thực sự hy vọng đây không phải là AI."
Đó là AI.