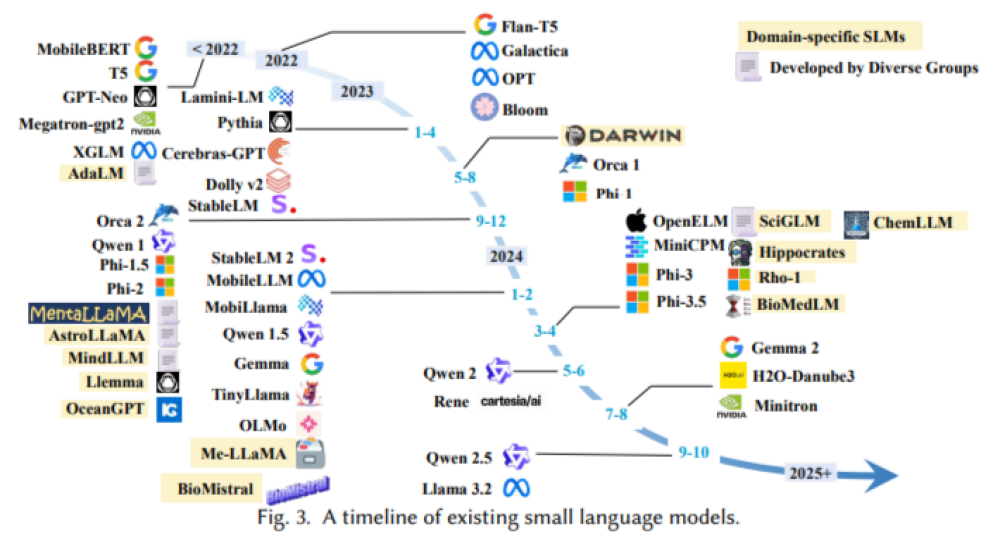
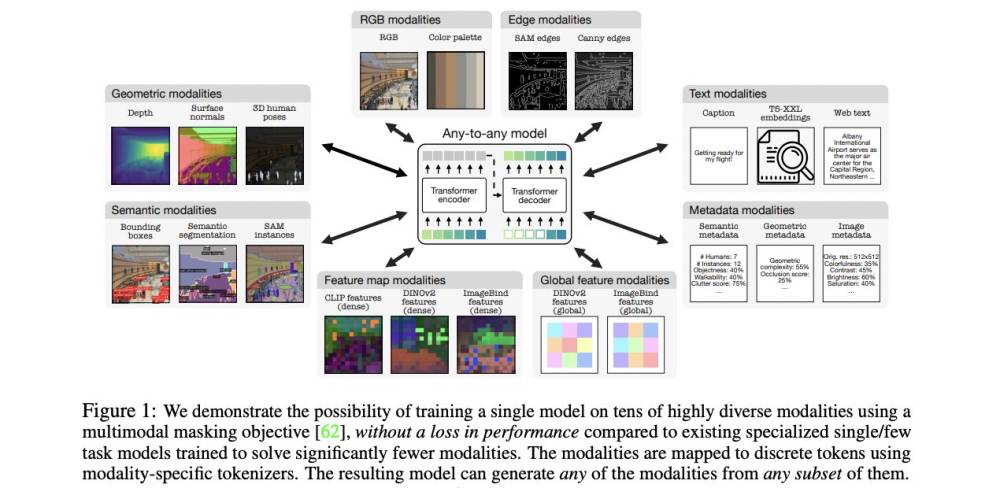
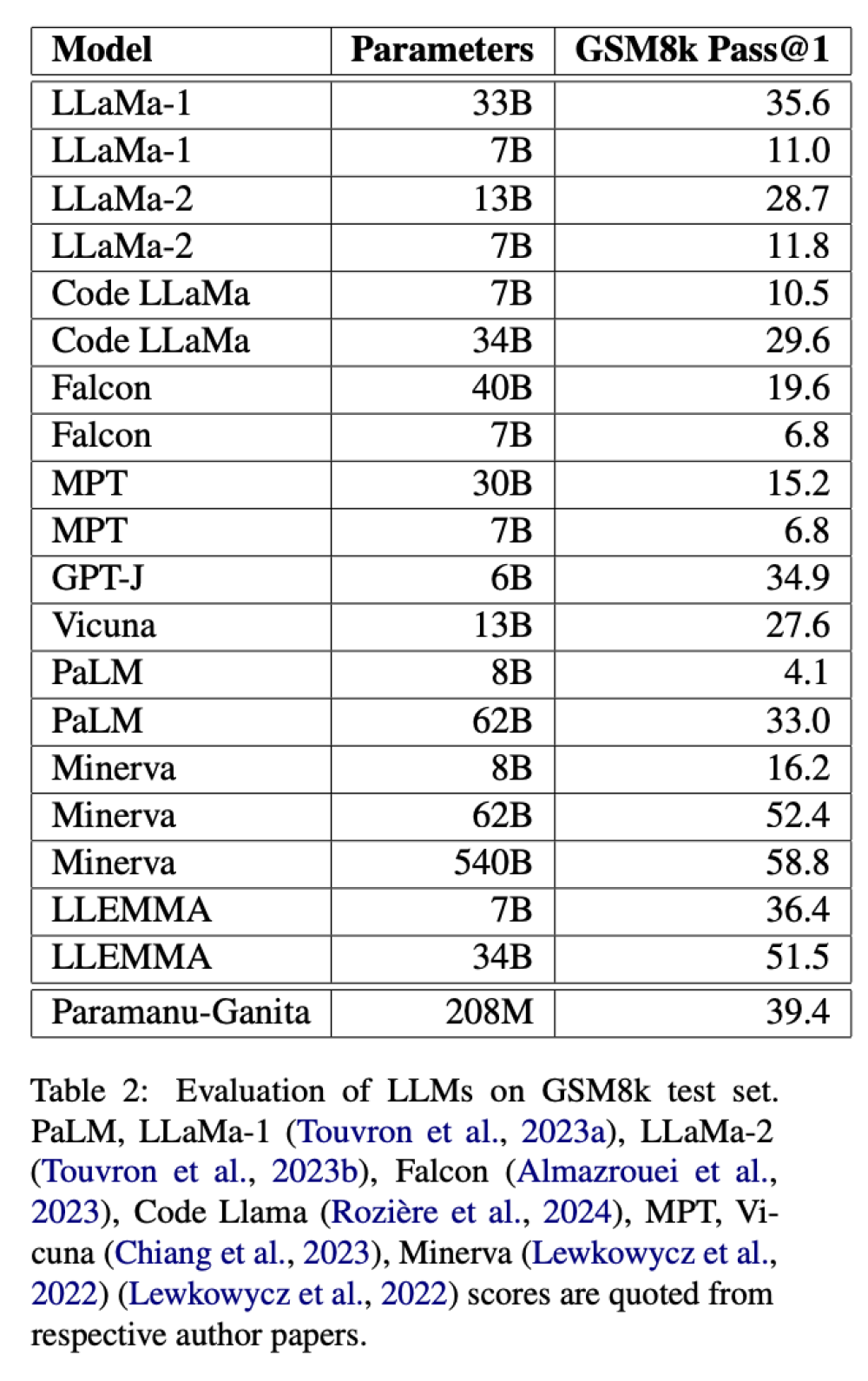
Tiềm năng của các mô hình AI nhỏ gọn trong việc tối ưu hóa quy trình công việc và an ninh mạng
- Kazuhiro Gomi, CEO của NTT Research, nhấn mạnh rằng các công ty muốn áp dụng AI đã được đào tạo cho các nhiệm vụ cụ thể trong quy trình lớn hơn như kế toán.
- Tại diễn đàn R&D của NTT vào tháng 11 năm 2024, công ty đã giới thiệu các tác nhân AI sử dụng LLM mang tên Tsuzumi.
- Tsuzumi nhẹ hơn và có thể chạy trên một GPU duy nhất, khác với các LLM yêu cầu nhiều GPU.
- Mặc dù mô hình nhỏ không thể cạnh tranh với các mô hình phức tạp ở tất cả các nhiệm vụ, Gomi tin rằng chúng có thể được tinh chỉnh để hoạt động trong các môi trường cụ thể.
- Một demo cho thấy tác nhân AI sử dụng Tsuzumi có thể chạy trên máy tính để bàn Windows và thực hiện các chỉ dẫn bằng ngôn ngữ tự nhiên để mua sắm bút.
- Các công ty cần xác định mục tiêu, cách tiếp cận AI và cách thu thập dữ liệu để xây dựng mô hình.
- Leslie Teo, giám đốc sản phẩm AI tại AI Singapore, cho biết rằng các nhà phát triển LLM ban đầu kỳ vọng các nhà phát triển ứng dụng sẽ gọi đến các mô hình trực tuyến.
- Mô hình nhỏ rất cần thiết trong các khu vực có kết nối internet không ổn định.
- Một trong những mô hình AI nhỏ nhất của GoTo chỉ nặng 80 kilobytes, dùng để nhận diện “wake word” nhằm kích hoạt trợ lý AI.
- Các nhà sản xuất laptop như Dell và Qualcomm đã yêu cầu tối ưu hóa mô hình Sea-Lion của Singapore để chạy trên các đơn vị xử lý thần kinh (NPU).
- NPU rẻ hơn, tiêu thụ ít năng lượng và cần thiết cho AI trên máy tính Windows mới.
- Singapore sắp sản xuất phiên bản Sea-Lion với 70 tỷ tham số nhưng không mong đợi sự chấp nhận lớn từ người dùng.
- AI Singapore sẽ tối ưu hóa mô hình AI xuống còn 1 đến 3 tỷ tham số vào năm 2025 nhằm tạo ra giá trị kinh tế.
- Tan Ah Tuan, giám đốc Ensign Infosecurity, cho biết công ty đã áp dụng AI trong nền tảng kiểm tra mối đe dọa Apollo.
- Apollo sử dụng LLM để tạo báo cáo về các lỗ hổng mạng mà khách hàng có thể gặp phải, điều này rất quan trọng khi triển khai trên cơ sở hạ tầng thông tin quan trọng không có kết nối internet.
- Phiên bản LLM của Meta, Llama 3, mà họ tùy chỉnh có thể tạo ra báo cáo tốt hơn những gì nhân viên viết thủ công.
- Mô hình lớn hơn không nhất thiết sản xuất kết quả tốt hơn.
- Mục tiêu của họ là vượt qua con người, không cần phải hoàn hảo.
📌 Các mô hình AI nhỏ gọn đang được ứng dụng rộng rãi trong nhiều lĩnh vực như kế toán và an ninh mạng. Chúng cải thiện hiệu quả công việc với yêu cầu yêu cầu phần cứng thấp hơn, tiết kiệm năng lượng và hoạt động hiệu quả ngay cả khi không có internet.
https://www.techinasia.com/honey-shrunk-llm-leaner-meaner
#TechinAsia
Honey, I shrunk the LLM: Tại sao mô hình ngôn ngữ nhỏ gọn lại hiệu quả hơn?
Các mô hình ngôn ngữ lớn (LLM) – hệ thống AI như ChatGPT xử lý dữ liệu văn bản để hiểu và tạo ra ngôn ngữ tự nhiên – đã được ca ngợi như một bước đột phá lớn.
Dù LLMs có tiềm năng giúp tăng năng suất lao động – hoặc thậm chí thay thế con người trong một số công việc – các chuyên gia trong ngành cho rằng những hệ thống này cần phải nhỏ gọn hơn và ít tốn kém hơn trước khi được áp dụng rộng rãi hơn.
Sri Ambati, nhà sáng lập kiêm giám đốc điều hành startup AI H2O.ai, cho biết rằng LLM đã chứng minh khả năng của máy tính trong việc trả lời các câu hỏi về nhiều lĩnh vực khác nhau.
Tuy nhiên, đối với các trường hợp sử dụng đơn giản hơn, việc áp dụng LLMs có thể bị xem là quá mức cần thiết. Hơn nữa, chi phí vận hành các ứng dụng AI sử dụng LLMs có thể rất cao, Ambati bổ sung.
Ambati ước tính rằng một trường hợp sử dụng AI dựa trên LLM có thể tốn từ 500.000 USD đến 1 triệu USD. Nếu một công ty có 1.000 trường hợp sử dụng AI trải rộng trên các chức năng khác nhau, họ có thể phải chi tới 1 tỷ USD chỉ để triển khai AI.
SLM: Lối thoát tiết kiệm và hiệu quả
Do đó, việc tạo ra các mô hình chuyên biệt phù hợp với nhu cầu của từng công ty thay vì phát triển các LLM lớn hơn (và tốn kém hơn) để vận hành là một giải pháp hợp lý, ông giải thích.
Và đó là nơi các mô hình ngôn ngữ nhỏ (SLM) xuất hiện – về cơ bản là các phiên bản được tinh gọn từ LLMs.
Mô hình SLM của H2O.ai, được đặt tên là Danube, đã được đào tạo với 6 nghìn tỷ token (bao gồm từ, phân từ hoặc ký tự).
Các phiên bản của mô hình này sau đó được phát triển với 4 tỷ, 2 tỷ, và 500 triệu tham số, ít hơn đáng kể so với các mô hình lớn và phức tạp hơn.
Ví dụ, GPT-4 của OpenAI được ước tính có khoảng 1,8 nghìn tỷ tham số.
Ambati chia sẻ rằng công ty ông đã đào tạo các SLM với dữ liệu từ trung tâm cuộc gọi của AT&T để tạo ra một mô hình phân loại cuộc gọi. Ông cho biết tập đoàn viễn thông Mỹ đã chọn thử nghiệm giải pháp này sau khi đã sử dụng các LLM.
“Chúng tôi vẫn cần thực hiện làm sạch dữ liệu, quản lý và gắn nhãn dữ liệu, đôi khi là tạo dữ liệu tổng hợp và chắt lọc,” ông lưu ý. Nhưng khi những bước đó hoàn thành, AT&T đã đạt được tiết kiệm chi phí đáng kể và tốc độ phản hồi nhanh hơn từ mô hình, ông chia sẻ.
Các nhà sản xuất chip và mô hình nhỏ hơn
Teo cho biết ngay cả các nhà sản xuất laptop và chip, như Dell và Qualcomm, cũng đã hỏi liệu Singapore có thể tối ưu hóa mô hình ngôn ngữ lớn (LLM) Sea-Lion để chạy cục bộ trên các bộ xử lý thần kinh (NPU) hay không.
NPU là các chip bán dẫn giá rẻ hơn, tiêu thụ ít năng lượng hơn, có khả năng thực hiện các phép tính AI và hiện được yêu cầu trên các máy tính Windows AI mới. Những chip này được kỳ vọng sẽ chạy các trợ lý AI với mức tiêu thụ năng lượng tối thiểu mà không cần truy cập internet.
Teo nhận định: “Tôi nghĩ đây sẽ là cách mọi thứ được sử dụng. Chúng ta sẽ không có một mô hình lớn duy nhất; thay vào đó, sẽ có nhiều mô hình nhỏ và tất cả sẽ hoạt động cùng nhau trong một hệ thống.”
Singapore dự kiến sẽ sớm sản xuất một phiên bản Sea-Lion với 70 tỷ tham số, nhưng Teo bổ sung rằng ông không mong đợi người dùng sẽ áp dụng mô hình này.
“Mục tiêu của chúng tôi là làm tốt hơn con người. Chúng tôi không cần nó phải hoàn hảo.”
Thay vào đó, AI Singapore, chương trình AI quốc gia đã tạo ra Sea-Lion, sẽ tối ưu hóa mô hình AI của mình vào năm 2025 để còn khoảng 1 tỷ đến 3 tỷ tham số, với hy vọng các công ty sẽ sử dụng mô hình này để tạo ra giá trị kinh tế.
Lo ngại về an ninh
Ngoài các lợi ích như chạy trên phần cứng giá rẻ hơn và tiêu thụ ít năng lượng hơn, các mô hình ngôn ngữ nhỏ (SLM) cũng sẽ hữu ích khi máy tính không có kết nối internet.
Tan Ah Tuan, giám đốc điều hành tại Ensign Infosecurity, một nhà cung cấp giải pháp an ninh mạng, cho biết công ty đã áp dụng AI vào Apollo, nền tảng săn lùng mối đe dọa (threat-hunting) của mình, để tạo ra các báo cáo bằng LLM.
Báo cáo này cung cấp cho khách hàng thông tin về những lỗ hổng trong mạng của họ, cách mà các kẻ tấn công tiềm năng có thể khai thác, và các biện pháp mà khách hàng có thể thực hiện để củng cố hệ thống của mình.
Tan cho biết, vì giải pháp được triển khai trên hạ tầng thông tin quan trọng, vốn được cách ly khỏi internet, LLM phải chạy ngoại tuyến.
Ngoài ra, vì công ty đã tinh chỉnh LLM để chỉ tham chiếu các mối đe dọa được phát hiện trong mạng của khách hàng, mô hình này không tạo ra các phản hồi sai lệch thường thấy ở các LLM dựa trên đám mây như ChatGPT của OpenAI hoặc Gemini của Google.
Tan chia sẻ rằng phiên bản Llama 3 của Meta, được công ty tùy chỉnh, hiện có thể tạo ra các báo cáo tốt hơn so với những gì nhân viên trước đây viết thủ công.
“Chúng tôi có một tiêu chí: khi khách hàng đọc báo cáo, họ có thể sao chép và dán nó vào email để gửi cho sếp mà không cần chỉnh sửa gì thêm,” ông cho biết.
Mô hình lớn hơn không phải lúc nào cũng tốt hơn
Tan lưu ý rằng theo kinh nghiệm của mình, các mô hình mới hơn và lớn hơn không nhất thiết tạo ra kết quả tốt hơn đáng kể.
“Mục tiêu của chúng tôi là làm tốt hơn con người. Chúng tôi không cần nó phải hoàn hảo.”
Lưu ý: Bài viết này được xuất bản lại với sự cho phép từ The Business Times, nơi đã cung cấp bài viết này cho các thuê bao trả phí của họ. Nội dung đã được chỉnh sửa một cách vừa phải để phù hợp với các nguyên tắc biên tập của Tech in Asia.
Honey, I shrunk the LLM: why leaner is meaner
Large language models (LLMs) – AI systems like ChatGPT that process text data to comprehend and generate human language – have been touted as a game changer.
Despite the potential of LLMs to make workers more productive – or even replace them in certain jobs – industry watchers believe that these systems have to be leaner and less expensive before they are more widely adopted.
Sri Ambati, founder and chief executive of AI startup H2O.ai, notes that LLMs have demonstrated that computers can answer questions about a wide range of topics.
But for simpler use cases, applying LLMs can seem like overkill. Moreover, the cost of AI applications powered by LLMs can be prohibitive, Ambati adds.
A single LLM-powered AI use case costs anywhere from US$500,000 to US$1 million, he estimates. If a company has 1,000 use cases spread across different functions, it could spend up to a billion dollars just to apply AI.
So it makes sense to create specialized models for companies to use, instead of creating larger LLMs that can be more expensive to operate, he explains.
Enter small language models (SLMs), which are essentially streamlined versions of LLMs.
H2O.ai’s own SLM, dubbed Danube, has been trained with 6 trillion tokens (words, sub-words, or characters).
Versions of the model were then created with 4 billion, 2 billion, and 500 million parameters, which is significantly fewer than those of larger and more complex models.
For instance, OpenAI’s GPT-4 is estimated to have about 1.8 trillion parameters.
According to Ambati, his company has trained SLMs with AT&T’s call center data to create a call classification model. He noted that the US telco opted to try this solution after already using LLMs.
“We still have to do data cleaning, data curation and labeling, and synthetic data (generation) sometimes, and distilling,” he points out. But once that’s done, AT&T achieved “dramatic” cost savings and faster responses from the model, he shares.
Good things in small packages
Similarly, Kazuhiro Gomi, the CEO of US startup NTT Research, said that in his experience, companies would like to adopt trained AI for specific tasks in larger processes such as accounting.
At NTT’s R&D Forum 2024 in November, the company demonstrated AI agents powered by the company’s LLM, dubbed Tsuzumi.
Among its selling points are that it is lightweight and can run on a single graphics processing unit (GPU), unlike other LLMs that may need multiple GPUs.
“(Tsuzumi) is lighter, therefore you can put that on different hardware devices,” notes Gomi.
While a smaller model may not be able to compete with more sophisticated ones in all tasks, he believes that they can be fine-tuned to operate in specific environments.
One of the company’s demos showed how a Tsuzumi-powered AI agent could run on a local Windows desktop and take natural language instructions to help someone procure pens. It could order the pens and fill out lengthy procurement forms based on prewritten instructions.
Gomi says that companies will need to take three steps when they first consider adopting AI. They will need to define what they want to achieve, how they want to adopt AI, and how they want to collect the data to build the models.
“That’s a common challenge that most of the companies are facing,” he says.
AI Singapore senior director of AI products Leslie Teo says that initially, LLM creators expected application makers to call on models online. This meant that large models could be hosted on powerful servers, and their responses could be served to users over the Web.
However, he adds that small models are necessary, especially in cases where users may be in areas with patchy internet connectivity.
One of GoTo’s smallest AI models, for instance, is only 80 kilobytes and is used to listen for users saying a “wake word” to trigger its AI assistant.
Teo says that even laptop and chip manufacturers, such as Dell and Qualcomm, have asked if Singapore could optimize its Sea-Lion LLM to run locally on neural processing units or NPUs.
NPUs are cheaper, lower-powered semiconductor chips that can do AI calculations and are a requirement on new Windows AI PCs. Such chips are expected to run AI assistants using minimal power and without accessing the web.
“I think this is how things are going to be used. We won’t have one big model; we will have many small models, and they all work together in a system,” he says.
Singapore will soon produce a version of Sea-Lion with 70 billion parameters, but Teo adds that he does not expect users to adopt this model.
Our goal was to be better than humans. We don’t need it to be perfect.
Instead, AI Singapore, the national AI program that created Sea-Lion, will optimize its AI model in 2025 to about 1 billion to 3 billion parameters, which he hopes companies will use to generate economic value.
Security concerns
Aside from the benefits of running on cheaper hardware and using less power, SLMs will also find use when computers do not have access to the internet.
Cybersecurity provider Ensign Infosecurity executive Tan Ah Tuan says that the company has adopted AI in Apollo, its threat-hunting platform that generates reports with an LLM.
The report tells clients what vulnerabilities their networks may have, how potential attackers can compromise these, and what clients can do to fortify their networks.
He adds that because the solution is deployed on critical information infrastructure, which is isolated from the internet, the LLM has to run offline.
Further, because the company has fine-tuned its LLM to only reference threats detected in a client’s network, the LLM does not generate erroneous responses common to that of other cloud-based LLMs such as OpenAI’s ChatGPT and Google’s Gemini.
Already, he says, the version of Meta’s LLM, Llama 3, that the company has customized can produce reports that are better than what employees could previously write manually.
“We have a criteria that when the client reads (the report), they’re able to copy and paste it in an email and send it to their boss without having to do any edits,” he says.
Tan notes that in his experience, newer, larger models do not necessarily produce significantly better results.
“Our goal was to be better than humans. We don’t need it to be perfect.”
This story was republished with permission from The Business Times, which made the article available to its paying subscribers. It was moderately edited to reflect Tech in Asia’s editorial guidelines.