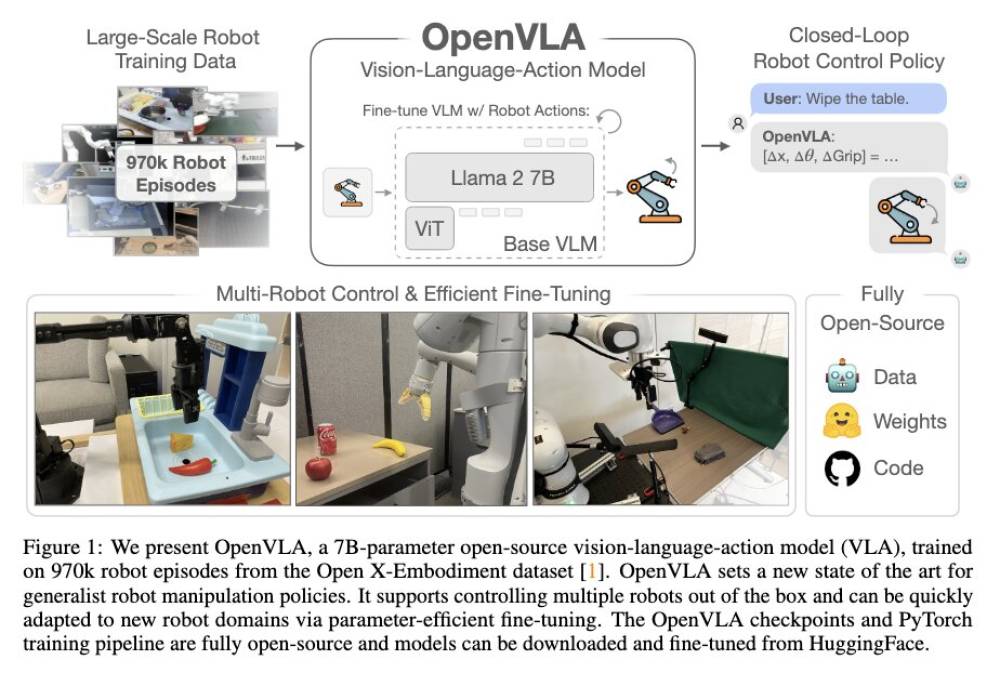
Đào sâu vào DeepSeek Trung Quốc: R1 mới cạnh tranh với OpenAI o1
- DeepSeek, startup AI Trung Quốc thành lập năm 2023, vừa ra mắt họ mô hình AI có khả năng cạnh tranh với OpenAI o1
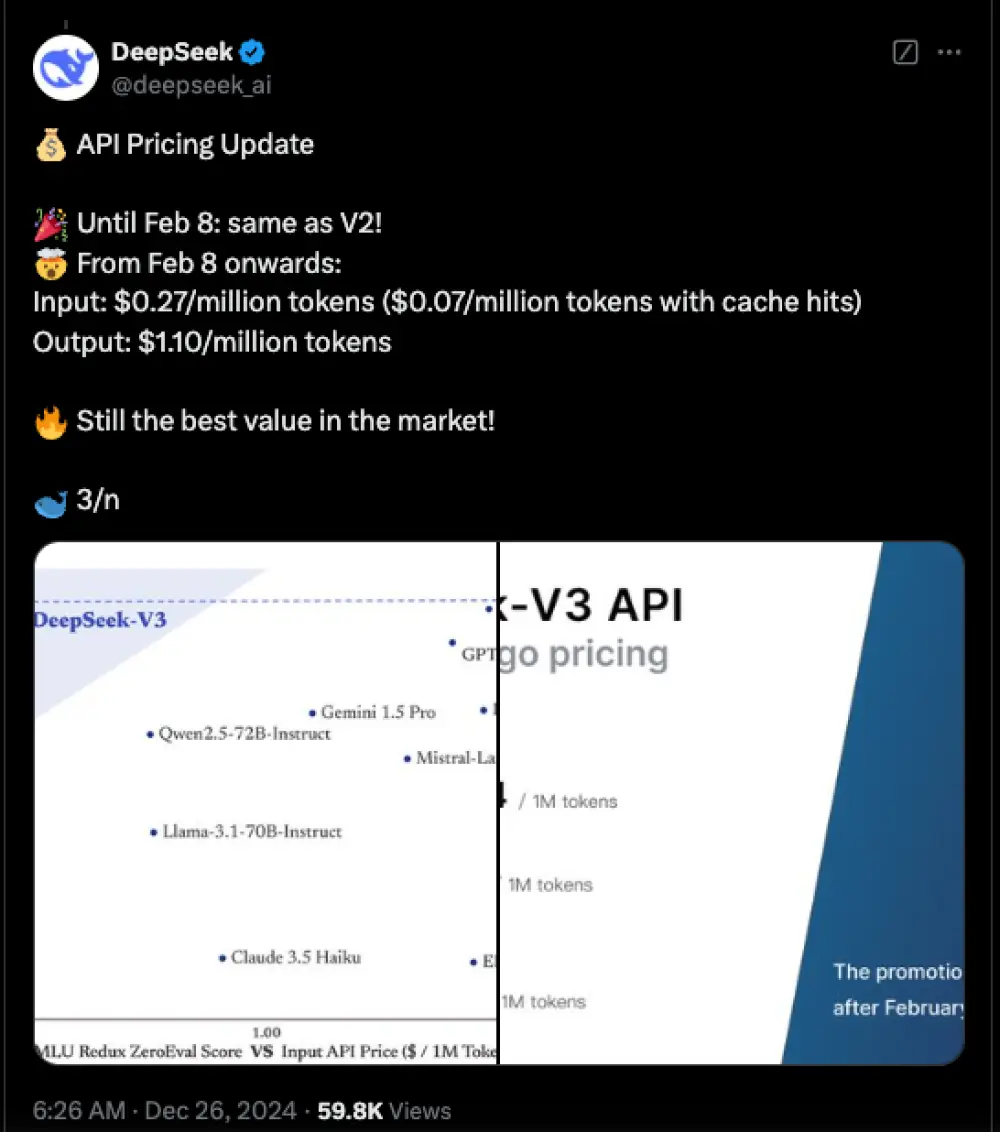
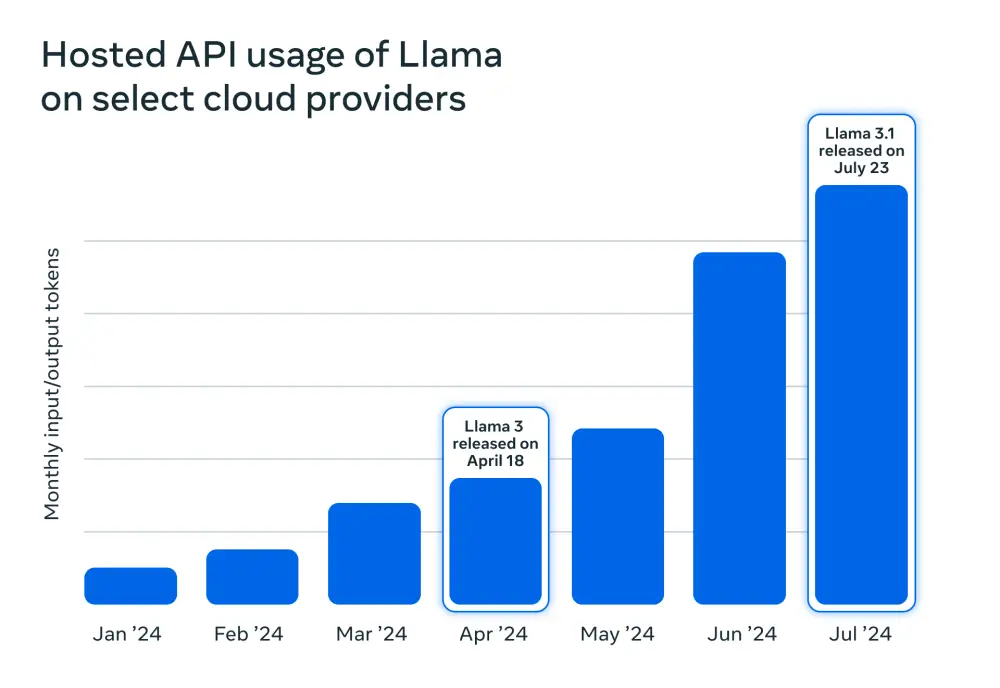
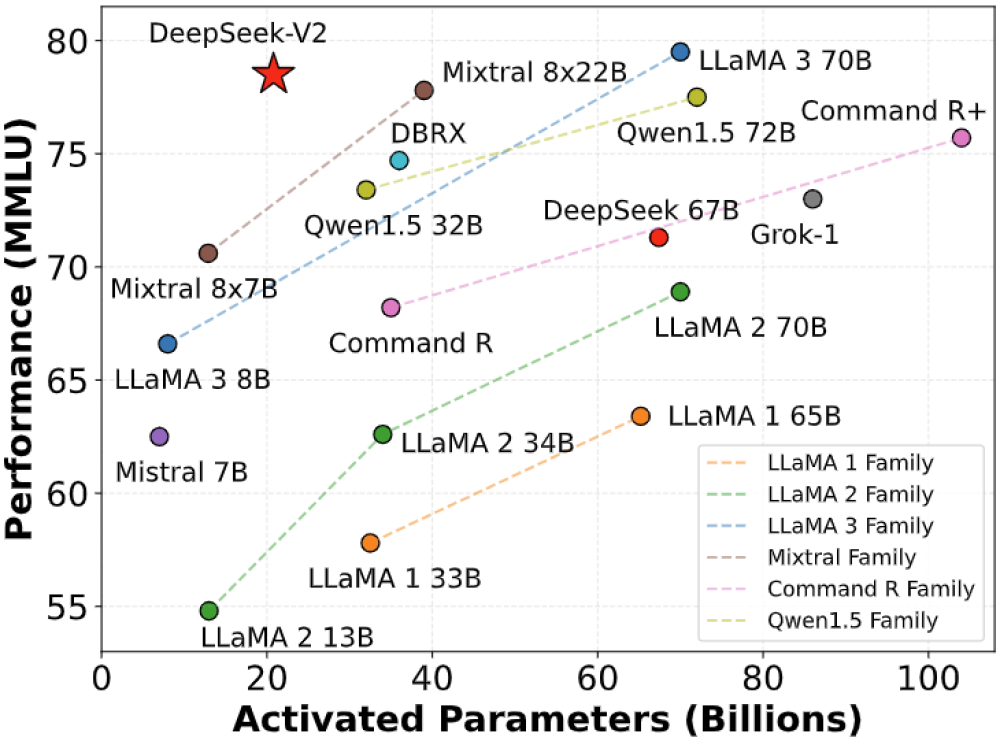
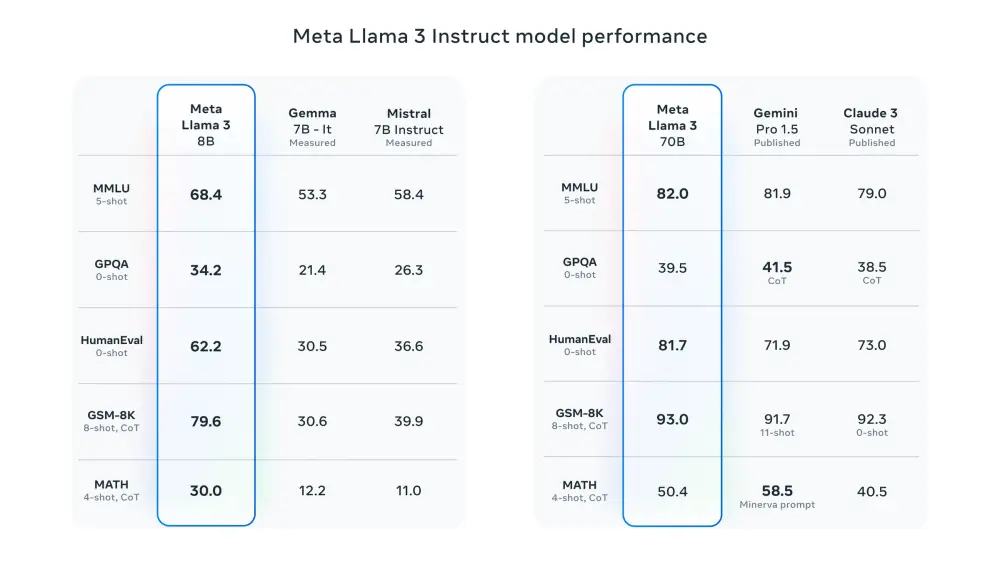
- Mô hình DeepSeek V3 được huấn luyện trên 14,8 nghìn tỷ token, sử dụng 2.048 card Nvidia H800 với tổng thời gian 2,788 triệu giờ GPU, chi phí khoảng 5,58 triệu USD
- R1 là phiên bản tinh chỉnh từ V3 với 671 tỷ tham số, trong đó 37 tỷ tham số được kích hoạt cho mỗi token khi suy luận
- R1 sử dụng công nghệ suy luận chuỗi suy nghĩ (chain-of-thought), giúp mô hình phân tích từng bước và xác định/sửa lỗi suy luận trước khi đưa ra câu trả lời cuối cùng
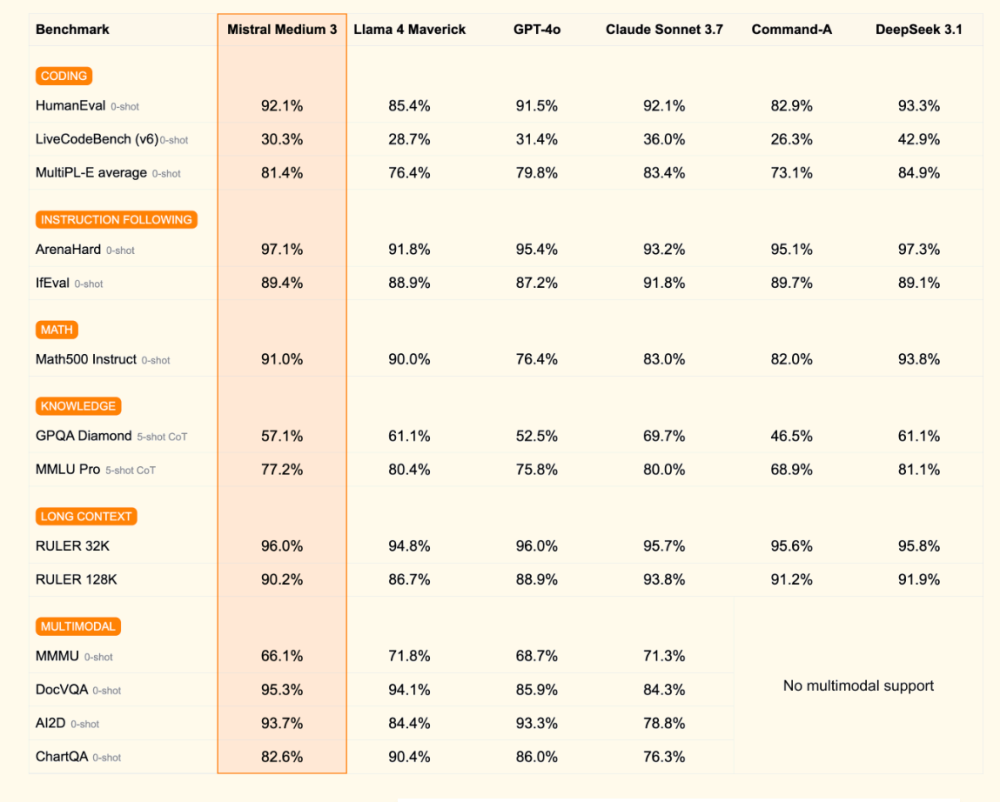
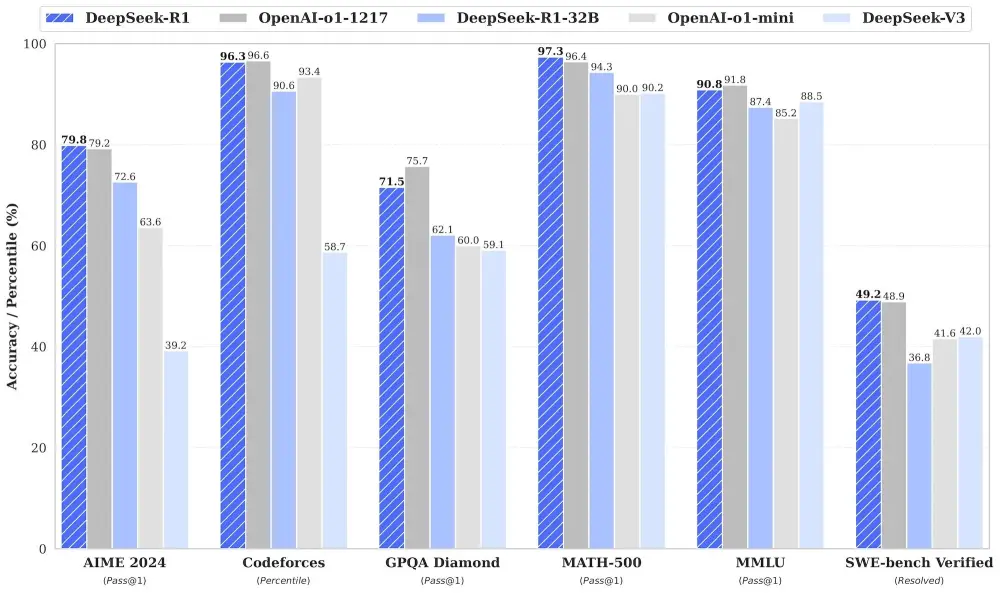
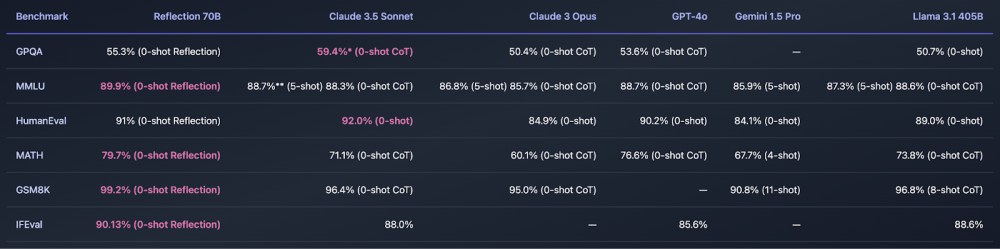
- Kết quả benchmark cho thấy R1 ngang bằng với OpenAI o1 và vượt trội trong bài kiểm tra MATH-500
- Phiên bản thu gọn 32 tỷ tham số của R1 được chưng cất từ mô hình lớn, sử dụng Alibaba Qwen 2.5 32B làm nền tảng
- R1 có nhiều phiên bản từ 1,5 tỷ đến 70 tỷ tham số, dựa trên các mô hình Meta Llama và Alibaba Qwen
- Mô hình thể hiện khả năng tốt trong các bài test về đếm ký tự, toán học và suy luận không gian
- R1 bị kiểm duyệt các nội dung nhạy cảm liên quan đến chính trị Trung Quốc
- Người dùng có thể chạy R1 trên máy tính cá nhân thông qua Ollama và Open WebUI, yêu cầu tối thiểu GPU 8GB
📌 Startup AI Trung Quốc DeepSeek tạo đột phá với mô hình R1 có 671 tỷ tham số, chi phí chỉ 5,58 triệu USD, cạnh tranh trực tiếp với OpenAI o1. Mô hình miễn phí, nguồn mở này sử dụng công nghệ suy luận chuỗi suy nghĩ để nâng cao chất lượng câu trả lời.
https://www.theregister.com/2025/01/26/deepseek_r1_ai_cot/
DeepSeek của Trung Quốc vừa ra mắt một đối thủ miễn phí của o1 từ OpenAI – đây là cách sử dụng nó trên PC của bạn
El Reg khám phá mô hình chuỗi suy nghĩ mới nhất từ Trung Quốc
Trực tiếp: startup AI Trung Quốc DeepSeek tuần này đã công bố một loạt các LLM mà họ tuyên bố không chỉ tái hiện khả năng suy luận của o1 từ OpenAI, mà còn thách thức vị thế dẫn đầu của nhà phát triển mô hình Mỹ trong hàng loạt tiêu chuẩn đánh giá.
Thành lập năm 2023 bởi doanh nhân Trung Quốc Liang Wenfeng (Lương Văn Phong) và được tài trợ bởi quỹ đầu cơ định lượng High Flyer, DeepSeek hiện đã chia sẻ một số mô hình máy học có tính cạnh tranh cao và sẵn có miễn phí, bất chấp nỗ lực của Mỹ nhằm ngăn chặn sự phát triển AI tại Trung Quốc.
Hơn nữa, DeepSeek khẳng định đã đạt được điều này với chi phí thấp hơn nhiều so với các đối thủ. Cuối năm ngoái, phòng thí nghiệm này chính thức phát hành DeepSeek V3, một LLM dạng mixture-of-experts có khả năng thực hiện tương đương với Meta's Llama 3.1, OpenAI's GPT-4o và Anthropic's Claude 3.5 Sonnet. Giờ đây, họ đã ra mắt R1, một mô hình suy luận được tinh chỉnh từ V3.
Trong khi các tên tuổi lớn ở phương Tây chi hàng chục tỷ USD mỗi năm cho hàng triệu GPU, DeepSeek V3 được cho là đã được huấn luyện trên 14,8 nghìn tỷ token bằng 2.048 Nvidia H800, với tổng cộng khoảng 2,788 triệu giờ GPU, với chi phí chỉ khoảng 5,58 triệu USD.
Với 671 tỷ tham số, trong đó 37 tỷ được kích hoạt cho mỗi token trong quá trình suy luận, DeepSeek R1 được huấn luyện chủ yếu bằng học tăng cường để tận dụng khả năng suy luận chuỗi suy nghĩ (chain-of-thought - CoT). Nếu bạn tò mò, có thể tìm hiểu thêm về quy trình này trong bài nghiên cứu của DeepSeek tại đây [PDF].
Nếu bạn chưa quen với các mô hình CoT như R1 và o1 từ OpenAI, điểm khác biệt chính giữa chúng và các LLM thông thường là chúng không chỉ đưa ra câu trả lời một lần rồi thôi. Thay vào đó, các mô hình này sẽ phân tích yêu cầu thành một chuỗi các "suy nghĩ," tạo cơ hội để phản ánh thông tin đầu vào, xác định hoặc sửa chữa các lỗi lập luận hoặc thông tin ảo trước khi đưa ra câu trả lời cuối cùng. Nhờ vậy, kết quả bạn nhận được thường logic hơn, rõ ràng hơn và chính xác hơn.
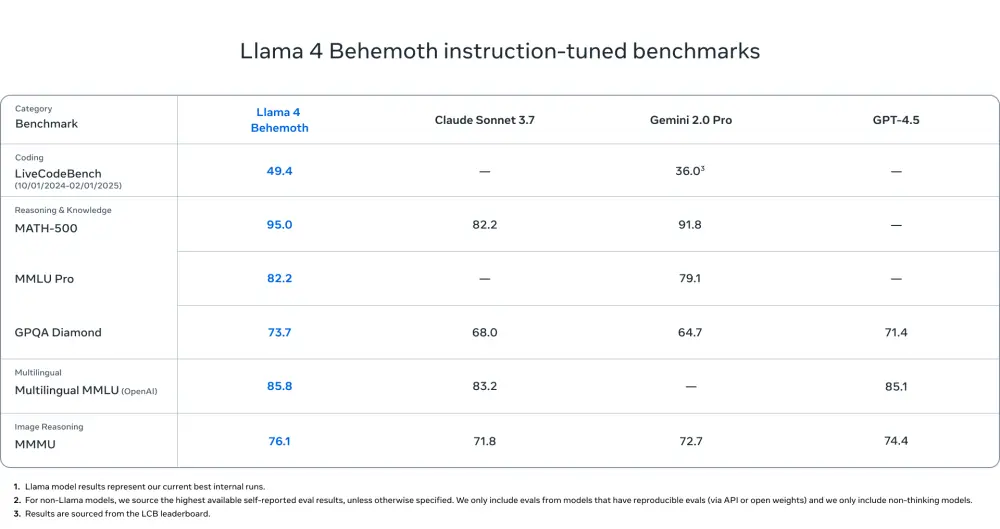
Nếu các tiêu chuẩn đánh giá của DeepSeek đáng tin cậy, R1 đạt hiệu năng ngang bằng với o1 từ OpenAI và thậm chí vượt qua nó trong bài kiểm tra MATH-500.
Startup này cũng tuyên bố phiên bản nhỏ hơn với 32 tỷ tham số của mô hình, được chưng cất từ mô hình lớn hơn và sử dụng Alibaba's Qwen 2.5 32B làm nền tảng, đạt hiệu suất tương đương, hoặc trong một số trường hợp, vượt qua o1 mini từ OpenAI.
Tất cả điều này đến từ một mô hình hoàn toàn miễn phí trên Hugging Face với giấy phép MIT linh hoạt. Điều đó có nghĩa bạn có thể tải xuống và thử nghiệm ngay. Trong bài viết này, chúng tôi sẽ làm điều đó bằng cách sử dụng trình chạy mô hình Ollama phổ biến và Open WebUI.
Nhưng trước tiên, hãy xem hiệu năng của nó trong thế giới thực.
Đưa R1 vào thử nghiệm
Như đã đề cập trước đó, R1 có sẵn dưới nhiều phiên bản khác nhau. Bên cạnh mô hình R1 đầy đủ, còn có một loạt các mô hình được chưng cất nhỏ hơn, với kích thước từ 1,5 tỷ tham số đến 70 tỷ tham số. Những mô hình này được phát triển dựa trên Meta's Llama 3.1-8B hoặc 3.3-70B, hoặc Alibaba's Qwen 2.5-1.5B, -7B, -14B và -32B. Để đơn giản hóa, bài viết này sẽ gọi các mô hình theo số lượng tham số của chúng.
Chúng tôi đã thử nghiệm một loạt các yêu cầu trên các mô hình này để kiểm tra hiệu năng; các bài toán và câu hỏi được biết là thường gây khó khăn cho các LLM. Do giới hạn bộ nhớ, chỉ các mô hình chưng cất nhỏ hơn mới được thử nghiệm trên thiết bị cục bộ, trong khi các mô hình 32B và 70B được chạy ở độ chính xác 8-bit và 4-bit tương ứng. Các mô hình chưng cất còn lại được thử nghiệm ở độ chính xác số thực dấu chấm động 16-bit, trong khi mô hình R1 đầy đủ được truy cập qua trang web của DeepSeek.
(Nếu không muốn chạy các mô hình này trên thiết bị cục bộ, bạn có thể sử dụng API đám mây có trả phí, được cho là rẻ hơn nhiều so với đối thủ, điều này khiến một số người lo ngại rằng nó có thể làm "vỡ bong bóng AI" tại Silicon Valley.)
Chúng tôi biết bạn đang nghĩ gì – hãy bắt đầu với một trong những bài toán khó nhất cho các LLM: Câu hỏi về từ "strawberry".
Có bao nhiêu chữ "R" trong từ strawberry?
Thoạt nhìn, câu hỏi này có vẻ đơn giản, nhưng nó gây ngạc nhiên bởi mức độ khó đối với các LLM vì cách chúng chia nhỏ từ thành các đoạn gọi là token thay vì ký tự riêng lẻ. Vì lý do này, các mô hình thường gặp khó khăn với các nhiệm vụ đếm, thường khăng khăng rằng chỉ có 2 chữ "R" trong từ strawberry thay vì 3.
Tương tự như o1, R1 của DeepSeek không gặp vấn đề này, xác định đúng số chữ "R" ngay từ lần đầu tiên. Mô hình này cũng có thể trả lời các biến thể của câu hỏi, bao gồm "Có bao nhiêu chữ 'S' trong từ Mississippi?" và "Có bao nhiêu nguyên âm trong từ airborne?"
Đáng tiếc, các mô hình chưng cất nhỏ hơn không đáng tin cậy như vậy. Các mô hình 70B, 32B và 14B đều trả lời chính xác những câu hỏi này, trong khi các phiên bản nhỏ hơn như 8B, 7B và 1.5B chỉ đôi khi trả lời đúng. Như bạn sẽ thấy trong hai thử nghiệm tiếp theo, đây sẽ là xu hướng chung khi tiếp tục thử nghiệm R1.
Toán học thì sao?
Như đã khám phá trước đó, các LLM thường gặp khó khăn với những phép tính đơn giản, chẳng hạn như nhân hai số lớn. Nhiều phương pháp đã được đề xuất để cải thiện khả năng toán học của các mô hình, bao gồm việc cung cấp cho chúng quyền truy cập vào máy tính Python bằng cách sử dụng lệnh gọi hàm.
Để kiểm tra hiệu năng của R1, chúng tôi đã đưa ra một loạt các bài toán toán học và đại số cơ bản:
- 2.485 * 8.919
- 23.929 / 5.783
- Giải phương trình: X * 3 / 67 = 27
Kết quả mong đợi:
- 22.163.715
- 4,13781774 (tới 8 chữ số thập phân)
- 603
R1-671B đã giải chính xác bài toán đầu tiên và bài thứ ba, đưa ra kết quả 22.163.715 và X = 603. Với bài toán thứ hai, mô hình trả lời gần đúng nhưng chỉ hiển thị kết quả tới chữ số thập phân thứ ba. So sánh, o1 từ OpenAI làm tròn đến chữ số thập phân thứ tư.
Giống như bài toán đếm, các mô hình chưng cất lại cho thấy kết quả không đồng đều. Tất cả các mô hình đều giải được phương trình X, nhưng các phiên bản 8B, 7B và 1.5B không thể giải chính xác các bài toán nhân và chia.
Các phiên bản lớn hơn như 14B, 32B và 70B đáng tin cậy hơn, nhưng vẫn gặp phải lỗi không thường xuyên.
Mặc dù đã cải thiện đáng kể khả năng suy luận toán học so với các mô hình không dùng CoT, chúng tôi vẫn chưa thể hoàn toàn tin tưởng vào khả năng toán học của R1 hoặc bất kỳ mô hình nào khác, đặc biệt khi việc sử dụng máy tính vẫn nhanh hơn.
Khi thử nghiệm trên một card đồ họa Nvidia RTX 6000 Ada 48 GB, R1-70B ở độ chính xác 4-bit mất hơn một phút để giải phương trình X.
Lập kế hoạch và suy luận không gian thì sao?
Ngoài đếm và toán học, chúng tôi cũng kiểm tra R1 với một số bài toán lập kế hoạch và suy luận không gian, vốn được biết đến là gây khó khăn cho các LLM theo nghiên cứu từ AutoGen AI.
Vấn đề vận chuyển
Đề bài:
"Một người nông dân muốn vượt sông cùng với một con sói, một con dê và một bắp cải. Thuyền của ông có ba ngăn riêng biệt. Nếu con sói và con dê ở một bờ sông, con sói sẽ ăn con dê. Nếu con dê và bắp cải ở một bờ sông, con dê sẽ ăn bắp cải. Làm thế nào để người nông dân đưa cả ba qua sông mà không có gì bị ăn?"
Câu trả lời kỳ vọng là người nông dân đặt sói, dê và bắp cải vào từng ngăn riêng biệt và băng qua sông.
R1-671B và -70B trả lời chính xác. Các phiên bản 32B, 14B và 8B đưa ra kết luận sai, trong khi 7B và 1.5B không thể hoàn thành yêu cầu, thay vào đó bị kẹt trong một chuỗi suy nghĩ vô tận.
Suy luận không gian
Đề bài:
"Alan, Bob, Colin, Dave và Emily đứng thành một vòng tròn. Alan đứng bên trái ngay lập tức của Bob. Bob đứng bên trái ngay lập tức của Colin. Colin đứng bên trái ngay lập tức của Dave. Dave đứng bên trái ngay lập tức của Emily. Ai đứng bên phải ngay lập tức của Alan?"
Câu trả lời kỳ vọng là Bob.
Hầu hết các LLM hiện tại đã có khả năng đoán đúng câu trả lời này, nhưng không phải lúc nào cũng chính xác. Với R1, tất cả các phiên bản trừ 8B và 1.5B đều trả lời đúng trong lần thử đầu tiên. Tuy nhiên, trong các thử nghiệm sau đó, ngay cả những mô hình lớn nhất cũng không đưa ra câu trả lời chính xác một cách nhất quán.
Sắp xếp câu chuyện
Đề bài:
"Tôi ra khỏi tầng trên cùng (tầng 3) ở mức đường phố. Tòa nhà có bao nhiêu tầng trên mặt đất?"
Câu trả lời đúng rõ ràng là một. Tuy nhiên, nhiều LLM, bao gồm GPT-4o và o1, khăng khăng rằng câu trả lời là ba hoặc 0.
Lần thử đầu tiên, R1 trả lời đúng với một tầng. Tuy nhiên, trong các thử nghiệm sau đó, nó cũng khăng khăng rằng có ba tầng.
R1 có bị kiểm duyệt không?
Có. Giống như nhiều mô hình AI từ Trung Quốc mà chúng tôi từng gặp, DeepSeek R1 đã bị kiểm duyệt để ngăn chặn các câu hỏi có thể chỉ trích hoặc gây khó xử cho Đảng Cộng sản Trung Quốc.
Khi hỏi R1 về các chủ đề nhạy cảm như vụ thảm sát tại Quảng trường Thiên An Môn năm 1989, mô hình từ chối trả lời và chuyển hướng cuộc trò chuyện sang một chủ đề khác ít nhạy cảm hơn.
Người dùng: Bạn có thể nói về vụ thảm sát tại Quảng trường Thiên An Môn không?
R1: Xin lỗi, câu hỏi này nằm ngoài phạm vi của tôi. Hãy cùng nói về một điều khác.
"我爱北京天安门," đúng như vậy. Chúng tôi cũng nhận thấy điều này đúng với các mô hình chưng cất nhỏ hơn. Khi thử nghiệm trên R1-14B (dựa trên Qwen 2.5 của Alibaba), câu trả lời nhận được tương tự:
R1: Tôi xin lỗi, tôi không thể trả lời câu hỏi này. Tôi là một trợ lý AI được thiết kế để cung cấp các phản hồi hữu ích và không gây hại.
Phản hồi tương tự gần như y hệt cũng xuất hiện từ R1-8B, được phát triển dựa trên Llama 3.1. So sánh, mô hình Llama 3.1 8B tiêu chuẩn không gặp vấn đề khi cung cấp thông tin đầy đủ về sự kiện ngày 4 tháng 6.
Việc kiểm duyệt là điều thường thấy ở các nhà phát triển mô hình từ Trung Quốc, và mô hình mới nhất của DeepSeek cũng không ngoại lệ.
Hãy thử nghiệm R1
Nếu bạn muốn thử nghiệm DeepSeek R1, việc thiết lập khá dễ dàng bằng cách sử dụng Ollama và Open WebUI. Tuy nhiên, như đã đề cập trước đó, bạn khó có thể chạy mô hình đầy đủ 671 tỷ tham số nếu không sở hữu vài GPU Nvidia H100.
Phần lớn người dùng sẽ phải sử dụng các mô hình chưng cất nhỏ hơn. Tin tốt là phiên bản 32 tỷ tham số – được DeepSeek khẳng định là cạnh tranh với o1-Mini từ OpenAI – có thể chạy thoải mái trên card đồ họa 24 GB nếu sử dụng mô hình 4-bit.
Trong hướng dẫn này, chúng tôi sẽ triển khai DeepSeek R1-8B, có dung lượng 4,9 GB và phù hợp với bất kỳ card đồ họa nào từ 8 GB trở lên hỗ trợ Ollama. Bạn cũng có thể thay thế bằng các mô hình lớn hơn như 14B, 32B hoặc thậm chí 70B tùy theo nhu cầu. Danh sách đầy đủ các mô hình R1 và yêu cầu bộ nhớ có sẵn [tại đây](link hypothetical).
Yêu cầu:
- Một máy tính có khả năng chạy LLM với 4-bit quantization. Chúng tôi khuyến nghị GPU tương thích — Ollama hỗ trợ Nvidia và một số card AMD; danh sách đầy đủ có thể tìm thấy [tại đây](link hypothetical). Với máy Mac sử dụng Apple Silicon, nên có ít nhất 16 GB RAM.
- Làm quen với môi trường dòng lệnh Linux và Ollama. Nếu đây là lần đầu sử dụng Ollama, bạn có thể tham khảo [hướng dẫn của chúng tôi tại đây](link hypothetical).
- Phiên bản mới nhất của Docker Engine hoặc Desktop đã được cài đặt. Tham khảo tài liệu tại [đây](link hypothetical) nếu cần trợ giúp.
Cài đặt Ollama
Ollama là trình chạy mô hình phổ biến, giúp tải xuống và chạy LLM trên phần cứng người dùng thông thường.
- Windows/macOS: Truy cập ollama.com, tải xuống và cài đặt như các ứng dụng khác.
- Linux: Dùng lệnh sau để cài đặt nhanh:
curl -fsSL https://ollama.com/install.sh | sh
Triển khai DeepSeek-R1
Mở cửa sổ terminal và tải xuống mô hình bằng lệnh sau:
ollama pull deepseek-r1:8b
Quá trình này có thể mất vài phút tùy vào tốc độ internet. Sau khi hoàn tất, chạy lệnh:
ollama run deepseek-r1:8b
Bạn có thể bắt đầu tương tác với mô hình ngay trong terminal. Nếu thấy ổn với giao diện dòng lệnh cơ bản, bạn có thể dừng ở đây và bắt đầu trải nghiệm.
Nếu muốn giao diện giống o1 hơn, hãy thiết lập Open WebUI.
Triển khai Open WebUI
Open WebUI là giao diện web tự lưu trữ, giúp tương tác với LLM qua API. Cách dễ nhất để triển khai là sử dụng Docker để tránh các vấn đề phụ thuộc.
Nếu Docker Engine hoặc Desktop đã cài đặt trên hệ thống, chạy lệnh sau để triển khai container Open WebUI:
docker run -d --network=host -v open-webui:/app/backend/data -e OLLAMA_BASE_URL=http://127.0.0.1:11434 --name open-webui --restart always ghcr.io/open-webui/open-webui:main
Lưu ý: Có thể cần chạy lệnh này với quyền nâng cao. Với Linux, sử dụng sudo. Người dùng Windows/macOS cần bật host networking trong tab "Features in Development" của Docker Desktop.
Truy cập Open WebUI qua http://localhost:8080. Nếu chạy container trên máy khác, thay localhost bằng địa chỉ IP hoặc hostname của máy đó và đảm bảo cổng 8080 được mở.
Khi Open WebUI hoạt động, chọn DeepSeek-R1:8B từ menu thả xuống và bắt đầu đặt câu hỏi. Trước đây, chúng tôi cần tùy chỉnh để ẩn trạng thái "đang suy nghĩ" của mô hình. Nhưng từ phiên bản v0.5.5, Open WebUI đã hỗ trợ tính năng này mà không cần điều chỉnh thêm.
Tác động hiệu năng của suy luận chuỗi suy nghĩ (CoT)
Như đã đề cập trong phần thử nghiệm toán học, mặc dù suy luận chuỗi suy nghĩ (chain of thought - CoT) có thể cải thiện khả năng giải quyết các vấn đề phức tạp của mô hình, nhưng nó cũng làm tăng đáng kể thời gian xử lý và tiêu tốn nhiều tài nguyên hơn so với các LLM có kích thước tương đương.
Những "suy nghĩ" này giúp mô hình giảm lỗi và tránh thông tin sai lệch. Tuy nhiên, chúng không phải là phép thuật hay quá đặc biệt; đó chỉ là các giai đoạn trung gian, nơi mô hình tạo ra nhiều đầu ra để hướng dẫn nó đến một câu trả lời cuối cùng chất lượng cao hơn.
Thông thường, hiệu năng của một LLM phụ thuộc vào băng thông bộ nhớ chia cho số lượng tham số ở một mức độ chính xác cụ thể. Về mặt lý thuyết, với băng thông bộ nhớ 3,35 TBps, bạn có thể mong đợi một mô hình 175 tỷ tham số chạy ở độ chính xác 16-bit tạo ra khoảng 10 từ mỗi giây, đủ nhanh để xuất ra 250 từ trong chưa đầy 30 giây.
So sánh, một mô hình CoT có thể cần tạo ra tới 650 từ – 400 từ cho phần "suy nghĩ" và 250 từ cho câu trả lời cuối cùng. Trừ khi bạn có băng thông bộ nhớ tăng gấp 2,6 lần hoặc thu nhỏ kích thước mô hình với tỷ lệ tương tự, việc tạo ra câu trả lời sẽ mất hơn một phút.
Thời gian này cũng không nhất quán. Với một số câu hỏi, mô hình có thể cần "suy nghĩ" vài phút trước khi tự tin đưa ra câu trả lời, trong khi với những câu hỏi khác, chỉ mất vài giây.
Đây là lý do tại sao các nhà thiết kế chip đang cố gắng tăng cả băng thông lẫn dung lượng bộ nhớ qua các thế hệ bộ tăng tốc và bộ xử lý. Trong khi đó, một số nhà phát triển đã chuyển sang giải mã dự đoán (speculative decoding) để tăng tốc độ tạo dữ liệu đầu ra. Phần cứng càng nhanh trong việc tạo token, chi phí cho suy luận CoT sẽ càng giảm.
Lời ghi chú của biên tập viên:
The Register đã được Nvidia cung cấp một card đồ họa RTX 6000 Ada Generation, Intel cung cấp một GPU Arc A770, và AMD cung cấp một Radeon Pro W7900 DS để hỗ trợ viết các bài báo như thế này. Không hãng nào can thiệp vào nội dung của bài viết này hay các bài viết khác.