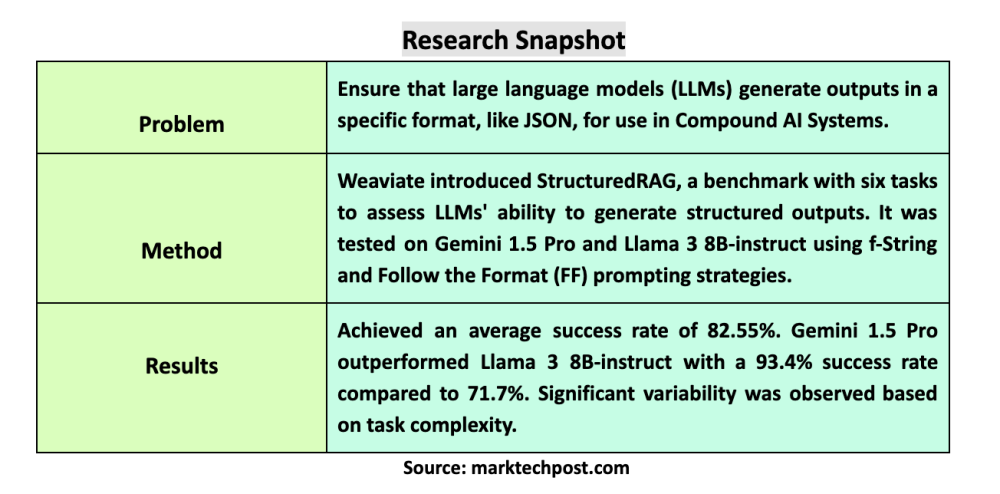
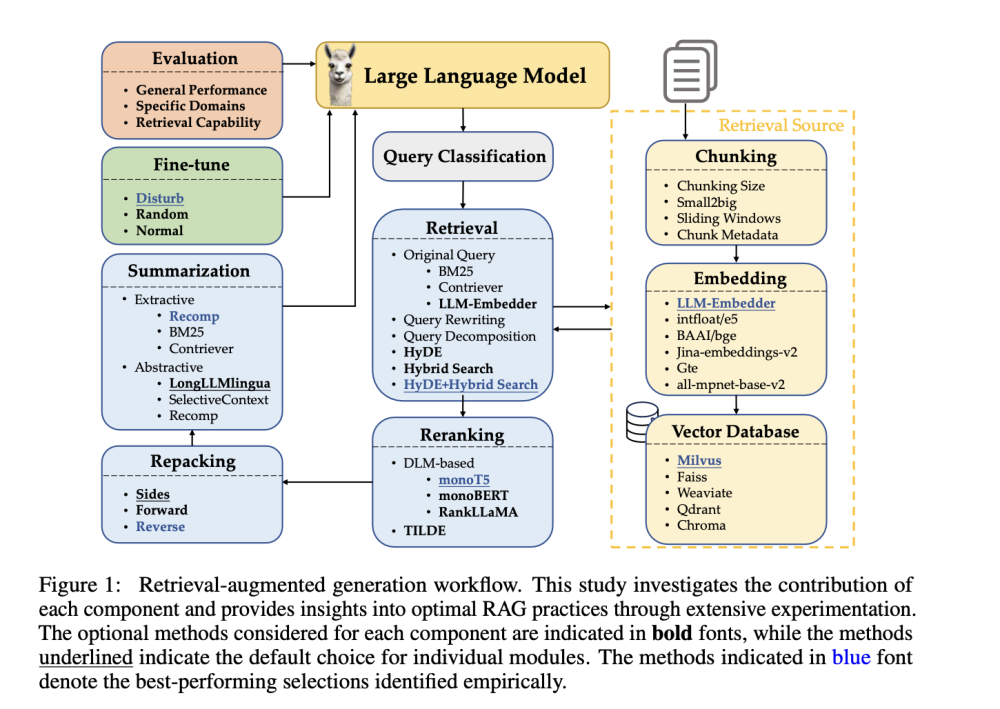
Chatbot Arena: Sân chơi đánh giá AI thu hút 1 triệu lượt truy cập/tháng
- Chatbot Arena được tạo ra đầu năm 2023 bởi Sky Computing Lab thuộc Đại học California Berkeley, hiện thu hút 1 triệu lượt truy cập mỗi tháng
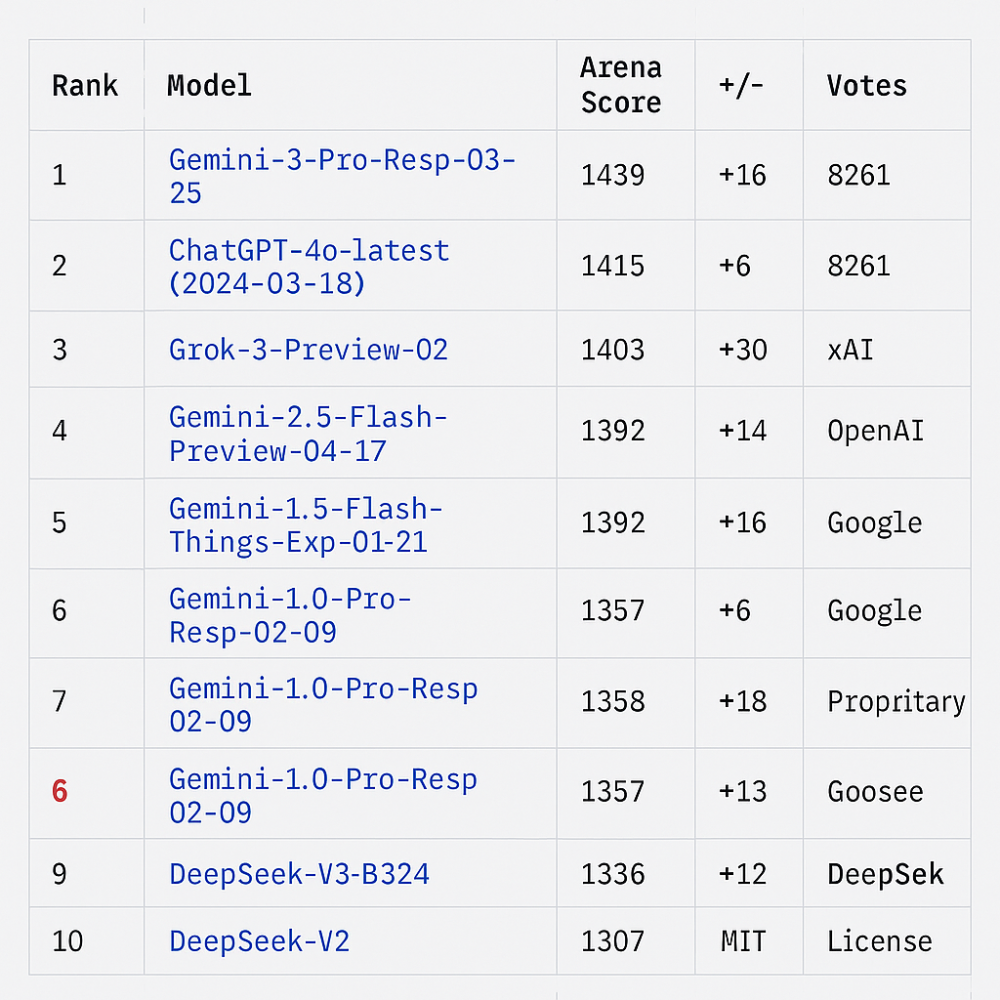
- Nền tảng này cho phép người dùng thử nghiệm và bình chọn các mô hình AI, tạo ra bảng xếp hạng dựa trên hệ thống tính điểm Elo như trong cờ vua
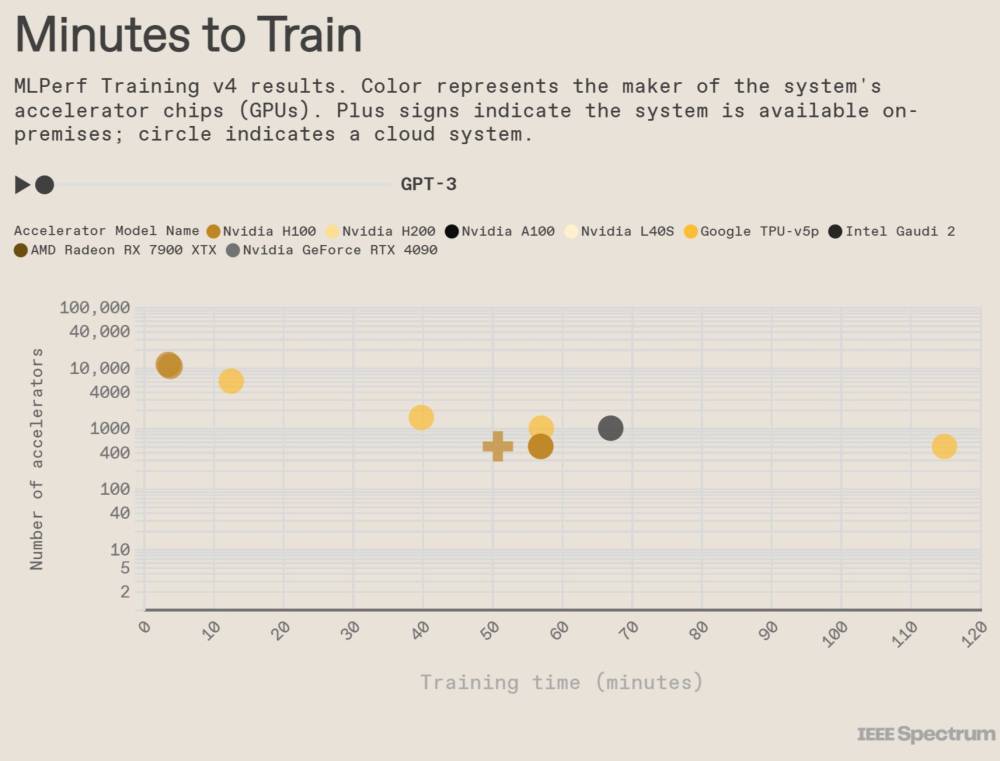
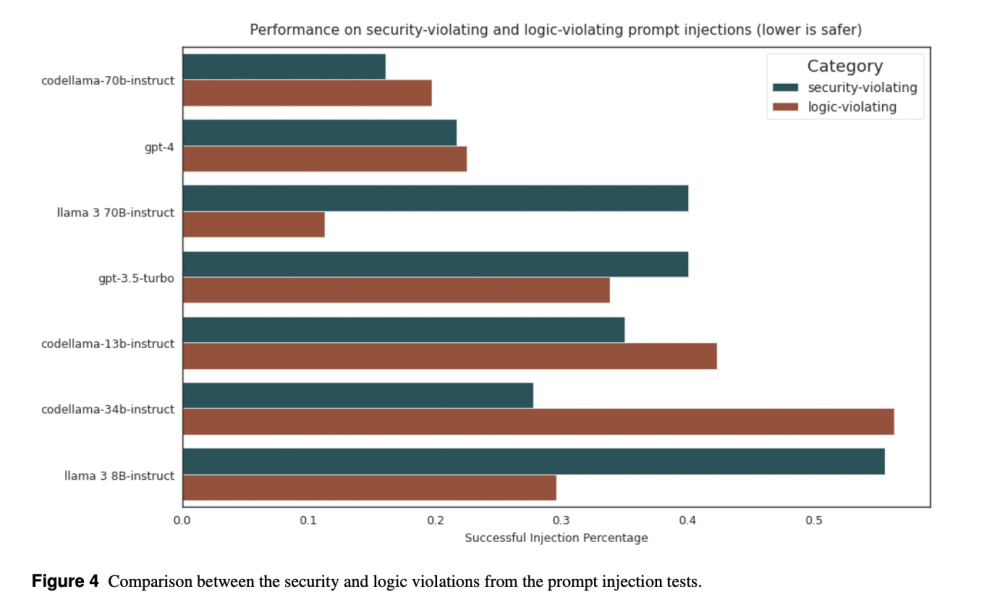
- DeepSeek đã thử nghiệm nhiều mô hình trên Chatbot Arena trước khi gây tiếng vang toàn cầu. Mô hình R1 của họ đã vươn lên vị trí thứ 3, vượt qua o1 của OpenAI
- Người dùng đã thực hiện hơn 2,6 triệu lượt bình chọn trên nền tảng. Các câu hỏi phổ biến tập trung vào lập trình máy tính và viết sáng tạo
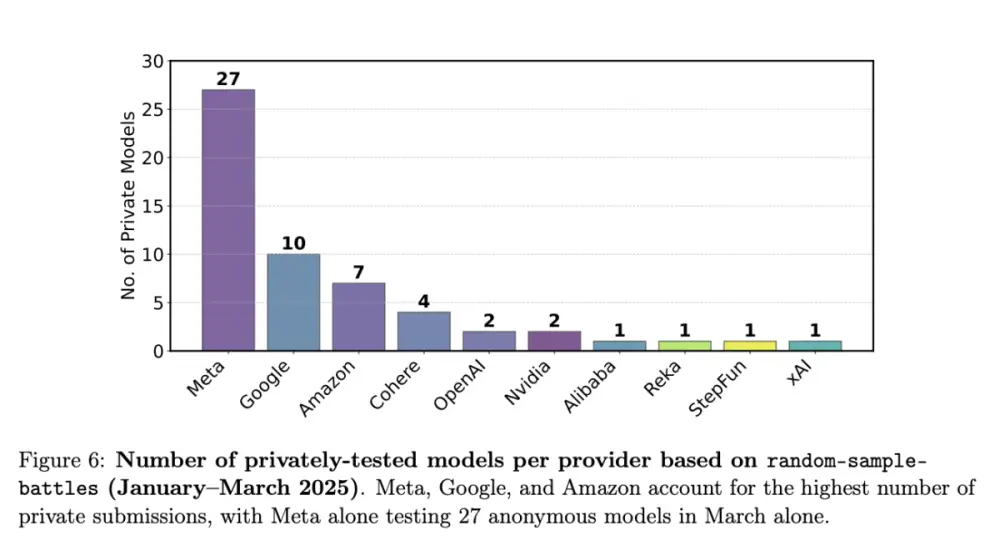
- Nền tảng đã thử nghiệm hơn 200 mô hình từ các công ty lớn như Anthropic, Google, Meta, OpenAI và xAI, với 90 mô hình vẫn đang hoạt động
- Wei-Lin Chiang và Anastasios Angelopoulos - hai nhà nghiên cứu sau tiến sĩ tại Berkeley điều hành dự án với sự hỗ trợ từ sinh viên và tài trợ của Andreessen Horowitz và Sequoia Capital
- Nền tảng này là nguồn mở, cho phép truy cập mã nguồn và dữ liệu. Các công ty phải trả phí cho việc người dùng thử nghiệm mô hình của họ
- Một số lo ngại về khả năng gian lận điểm số đã được nêu ra trong một nghiên cứu gần đây, nhưng đội ngũ phát triển khẳng định có nhiều biện pháp bảo vệ
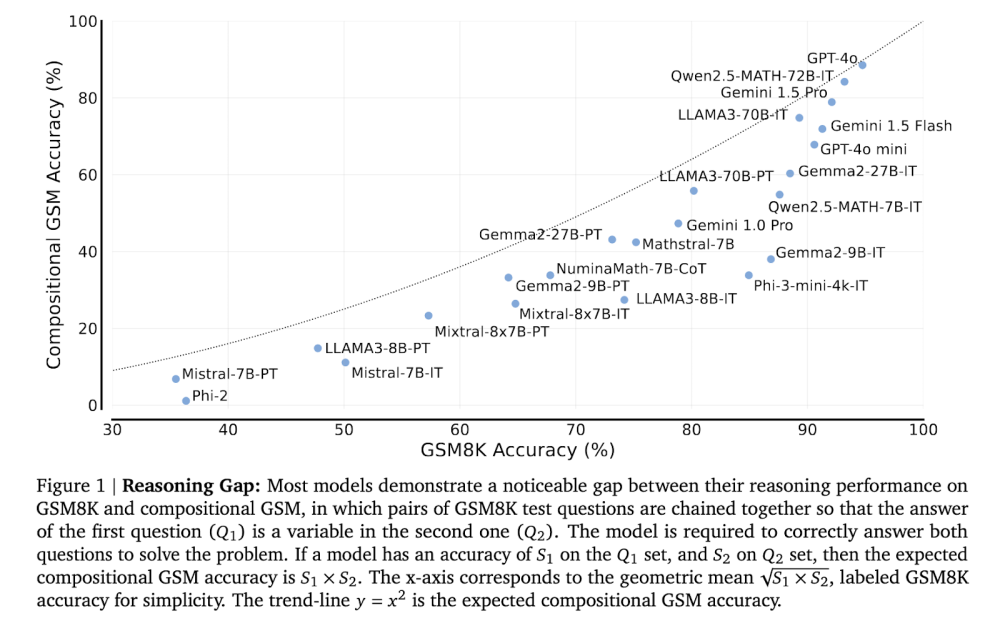
📌 Chatbot Arena đã chứng minh vai trò quan trọng trong việc đánh giá các mô hình AI với 2,6 triệu lượt bình chọn và 200 mô hình được thử nghiệm. Nền tảng này đã dự đoán chính xác sự thành công của DeepSeek trước khi công ty này gây chấn động thị trường công nghệ toàn cầu.
https://www.bloomberg.com/news/articles/2025-02-18/before-deepseek-blew-up-one-website-announced-its-arrival
Trước khi DeepSeek bùng nổ, Chatbot Arena đã báo trước sự xuất hiện của nó
Một hệ thống xếp hạng chatbot dựa trên đóng góp cộng đồng đã trở thành cách để giới chuyên gia AI tìm ra mô hình nào hoạt động tốt nhất.
Tác giả: Rachel Metz
Ngày 18 tháng 2 năm 2025, 11:00 AM UTC
Với phần lớn thế giới, DeepSeek dường như bùng nổ từ hư không vào tháng 1 với phần mềm AI mã nguồn mở có khả năng cạnh tranh với các mô hình của OpenAI và Google—và được cho là được xây dựng với chi phí chỉ bằng một phần nhỏ so với các đối thủ.
Tuy nhiên, đối với những người hâm mộ một trang web có tên Chatbot Arena, đó chỉ là một khoảnh khắc “biết ngay mà”: họ đã theo dõi—và đánh giá—sự phát triển của các mô hình từ công ty Trung Quốc đứng sau DeepSeek trong nhiều tháng qua.
Chatbot Arena ra mắt vào đầu năm 2023 giữa cơn sốt AI sau khi OpenAI phát hành ChatGPT chỉ vài tháng trước đó. Được tạo ra như một dự án nghiên cứu bởi Phòng thí nghiệm Sky Computing của Đại học California tại Berkeley, trang web này lưu trữ hàng loạt mô hình AI tiên tiến. Khách truy cập sử dụng các chatbot được vận hành bởi những mô hình đó và bỏ phiếu để đẩy chúng lên hoặc xuống bảng xếp hạng tùy theo hiệu suất mà họ đánh giá.
“Một bên thứ ba độc lập, có động lực đo lường trung thực tiến bộ trong lĩnh vực AI, sẽ là yếu tố quan trọng,” Wei-Lin Chiang, một trong những người đứng đầu Chatbot Arena và là nhà nghiên cứu sau tiến sĩ tại UC Berkeley, cho biết. “Ai cũng nói mô hình của mình là tốt nhất. Vì vậy, tính minh bạch và sự độc lập đóng vai trò rất lớn.”
Chatbot Arena nhanh chóng trở thành điểm đến phổ biến của những người tiên phong trong lĩnh vực AI và là một chỉ báo hàng đầu trong lĩnh vực đánh giá mô hình AI đang phát triển nhanh chóng: trang web thu hút 1 triệu lượt truy cập mỗi tháng. Cả các công ty AI hàng đầu lẫn những startup mã nguồn mở đầy triển vọng đều tìm đến đây để kiểm tra các mô hình mới. Một số công ty thậm chí còn đăng tải mô hình của mình lên trước khi phát hành rộng rãi (như OpenAI đã làm với GPT-4o vào mùa xuân năm ngoái).
Trước khi DeepSeek bùng nổ, Chatbot Arena đã báo trước sự xuất hiện của nó
Một hệ thống xếp hạng chatbot dựa trên đóng góp cộng đồng đã trở thành cách để giới chuyên gia AI tìm ra mô hình nào hoạt động tốt nhất.
Khi mọi thứ diễn ra suôn sẻ, đó không chỉ là một niềm tự hào mà, như DeepSeek đã cho thấy, còn mang lại cả danh tiếng quốc tế. Người dùng Chatbot Arena đã thử nghiệm nhiều mô hình mã nguồn mở của DeepSeek, và mỗi mô hình sau đều đạt thứ hạng cao hơn trên bảng xếp hạng chính của trang web so với mô hình trước đó. Những sản phẩm mới nhất của công ty là V3—một mô hình ngôn ngữ lớn tương tự như mô hình vận hành ChatGPT—và R1, mô hình tập trung tính toán câu trả lời lâu hơn trước khi phản hồi. Cả hai lần lượt xuất hiện trên Chatbot Arena vào cuối tháng 12 và tháng 1, nhanh chóng leo lên thứ hạng cao.
Chỉ vài ngày sau khi ra mắt, vào một ngày thứ Sáu, R1 nhảy lên vị trí thứ ba, vượt qua o1—một mô hình suy luận tương tự của OpenAI. Ứng dụng chatbot của DeepSeek bắt đầu dẫn đầu bảng xếp hạng trên các kho ứng dụng di động, bao gồm cả App Store của Apple tại Mỹ vào cuối tuần đó và Google Play Store vài ngày sau. Những nhân vật nổi bật như nhà đầu tư mạo hiểm Marc Andreessen và CEO OpenAI Sam Altman đã dành lời khen ngợi cho nó. Vào thứ Hai, các nhà đầu tư đã xóa gần 1 nghìn tỷ USD khỏi giá trị vốn hóa của các công ty công nghệ Mỹ và châu Âu, khi DeepSeek đặt ra câu hỏi liệu ngành công nghệ có đang chi tiêu quá mức cho hạ tầng AI hay không.
Những người đứng đầu Chatbot Arena, Chiang và Anastasios Angelopoulos—cũng là một nhà nghiên cứu sau tiến sĩ tại UC Berkeley—không mấy ngạc nhiên. “Thực ra, không quá bất ngờ khi một mô hình như thế này đạt đến đỉnh,” Angelopoulos nói. “Hệ sinh thái sẽ tiếp tục phát triển. Chỉ một tháng nữa thôi, cái tên dẫn đầu sẽ không còn là DeepSeek-R1 mà là một mô hình khác.”
Chatbot Arena không phải là dự án duy nhất cung cấp các tiêu chuẩn đánh giá AI công khai. Những sáng kiến như SWE-Bench hay Humanity’s Last Exam đánh giá hiệu suất của các mô hình AI tiên tiến trên nhiều nhiệm vụ khác nhau, chẳng hạn như trả lời câu hỏi toán học, lập trình hoặc giải các bài toán khó nhất mà con người biết đến. Tuy nhiên, hiện chưa có nhiều tiêu chuẩn chung và không có tổ chức chính thức nào giám sát phương pháp kiểm tra các mô hình này. Sự phát triển trong lĩnh vực này cũng diễn ra quá nhanh, đến mức các mô hình mới có thể nhanh chóng khiến những bài đánh giá hiện tại trở nên lỗi thời. (Nhớ bài kiểm tra Turing chứ?)
Chatbot Arena đánh giá trải nghiệm thực tế khi sử dụng từng sản phẩm. “Có thể gọi là ‘cảm nhận’, nhưng một cách khác để diễn đạt là thử nghiệm trong tình huống sử dụng thực tế,” Chiang nói. “Nếu bạn là OpenAI và đang xây dựng ChatGPT, bạn quan tâm đến trải nghiệm của người dùng.”
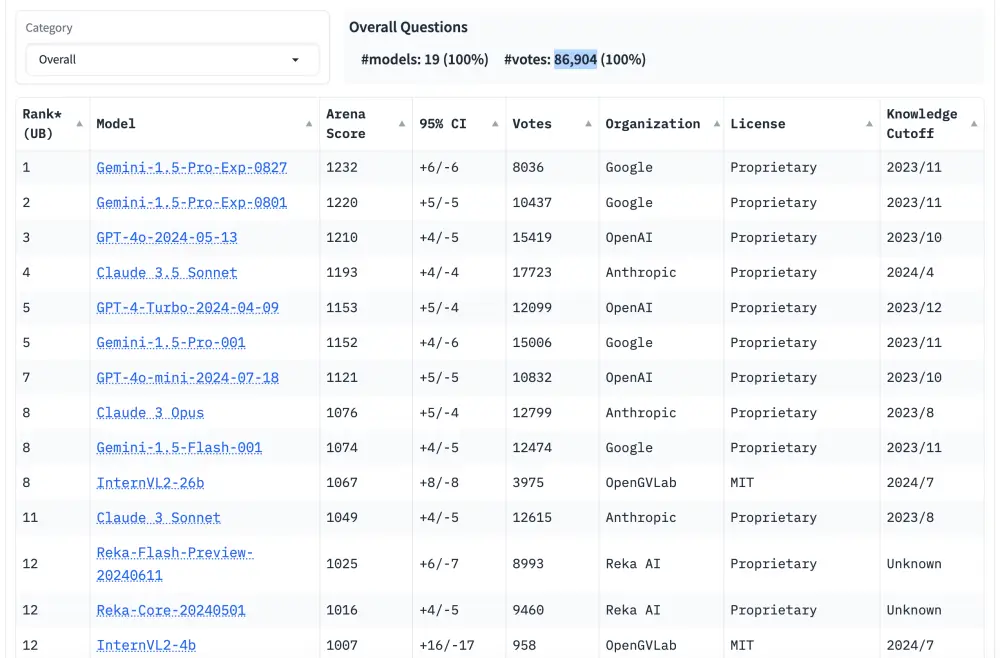
Tính đến đầu tháng 2, Chatbot Arena đã lưu trữ hơn 200 mô hình, bao gồm các mô hình từ Anthropic, Google, Meta Platforms, OpenAI và xAI, trong đó có 90 mô hình vẫn đang mở để người dùng thử nghiệm. Các công ty thường hợp tác với Chatbot Arena để đưa mô hình của họ lên trang web, sau đó chi trả chi phí phát sinh từ việc người dùng sử dụng chúng. Trang web này là mã nguồn mở, với dữ liệu và mã nguồn được cung cấp để người khác sử dụng, và nhận hỗ trợ từ một số khoản tài trợ bên ngoài, bao gồm từ các quỹ đầu tư mạo hiểm như Andreessen Horowitz và Sequoia Capital. Vì đây là một dự án nghiên cứu học thuật, phần lớn công việc duy trì Chatbot Arena do sinh viên UC Berkeley thực hiện.
Khi truy cập trang web, người dùng sẽ thấy một cửa sổ bật lên cảnh báo rằng đây là một dự án nghiên cứu. Họ được hướng dẫn đặt câu hỏi cho hai chatbot ẩn danh, sau đó chọn chatbot họ thích hơn. Sau khi bỏ phiếu, tên của mỗi chatbot sẽ được tiết lộ. Những phiếu bầu này được sử dụng để tạo xếp hạng, nhằm ước tính độ mạnh của từng mô hình; hệ thống này là một biến thể của hệ thống Elo trong cờ vua, vốn đánh giá sức mạnh dựa trên kết quả đối đầu trực tiếp.
Tính đến nay, người dùng đã ghi nhận hơn 2,6 triệu lượt bình chọn cho các mô hình ngôn ngữ yêu thích. Họ không cần đăng nhập, nên nhóm Chatbot Arena không biết về từng cá nhân cụ thể. Tuy nhiên, họ có phân loại tổng quan về loại câu hỏi mà người dùng thường đưa ra. Những câu hỏi về lập trình máy tính và viết sáng tạo đặc biệt phổ biến, với các đề bài ví dụ như: “Viết một bài thơ theo dạng cặp câu, sử dụng ngắt dòng để tạo cảm giác chuyển động và hồi hộp; chủ đề là quả táo.”
Xếp hạng của Chatbot Arena mang lại cảm giác khách quan tuyệt đối. Nhưng thực tế, nó chỉ đo lường một khía cạnh cụ thể: phản ứng của khán giả Chatbot Arena—những người dường như nghiêng về nhóm có tư duy học thuật, quan tâm đến các chủ đề như học máy. “Hệ thống xếp hạng này rất hay, và chúng tôi cũng thích gửi mô hình của mình vào, nhưng nó không thực sự phản ánh rằng ‘Mô hình này có phù hợp để làm việc không? Có dễ dàng để doanh nghiệp ứng dụng không?’” Nick Frosst, đồng sáng lập Cohere—công ty chuyên phát triển và tùy chỉnh mô hình AI cho doanh nghiệp—nhận xét.
Cũng có một số lo ngại về khả năng thao túng xếp hạng. Trong một bài nghiên cứu gần đây đăng trên Arxiv—một kho lưu trữ nghiên cứu mở chưa qua bình duyệt—các nhà nghiên cứu đã mô phỏng cách gian lận phiếu bầu để chỉ ra những lỗ hổng tiềm ẩn trên Chatbot Arena. Angelopoulos và Chiang cho biết trang web có nhiều cơ chế bảo vệ để ngăn chặn hành vi sử dụng sai mục đích. “Chúng tôi chưa thấy bằng chứng nào về một cuộc tấn công thành công vào hệ thống,” Angelopoulos nói.
Chiang, Angelopoulos và cộng sự đang tập trung cải thiện cộng đồng Chatbot Arena, đồng thời mở rộng các loại bài kiểm tra họ thực hiện. Họ đã bắt đầu hỗ trợ thử nghiệm các mô hình AI khác, bao gồm cả trình tạo hình ảnh. Với sự quan tâm ngày càng lớn, nhóm nghiên cứu cũng không loại trừ khả năng biến dự án này thành một mô hình kinh doanh thực sự. “Chúng tôi chắc chắn đang cân nhắc điều đó,” Chiang nói.
Before DeepSeek Blew Up, Chatbot Arena Announced Its Arrival
A crowdsourced rating system for chatbots has become the way AI insiders learn which models work best.
By Rachel Metz
February 18, 2025 at 11:00 AM UTC
For most of the world, DeepSeek seemed to explode out of nowhere in January with open-source artificial intelligence software that rivaled models from OpenAI and Google—and was built, purportedly, at a fraction of the cost of competitors’ models.
For fans of a website called Chatbot Arena, however, it was a bit of an eye-roll moment: They’d been watching—and rating—the progression of models from the Chinese company behind DeepSeek for months.
Chatbot Arena started in early 2023 amid the frenzy that followed OpenAI’s release of ChatGPT just months before. Created as a research project by the University of California at Berkeley’s Sky Computing Lab, the site hosts a slew of cutting-edge AI models. Visitors use chatbots powered by those models and push them up or down the leaderboards by voting on how they think they perform. An “independent third party with the incentive of truthfully measuring progress in the AI space will be critical,” says Wei-Lin Chiang, a leader of Chatbot Arena and a postdoctoral researcher at UC Berkeley. “Everybody says their model is the best. So transparency and independence help a lot.”
Chatbot Arena soon became a popular spot for early adopters and a leading indicator in the rapidly evolving field of AI benchmarking: It gets a million visitors per month. Top AI companies and open-source up-and-comers alike come to test out their new models. Some companies even post models before they release them generally (as OpenAI did with its GPT-4o last spring).
When things go well, it’s a source of bragging rights and, as DeepSeek showed, even some international notoriety. Chatbot Arena users have tested several of its open-source models, with each one rising higher on the site’s main leaderboard than the last. The company’s most recent offerings are V3, a large language model similar to the one that powers ChatGPT, and R1, which spends more time computing a response before spitting it out. They hit Chatbot Arena in late December and January, respectively, and climbed the ranks quickly.
Days after its release, on a Friday, R1 jumped to the third-place spot, besting o1, OpenAI’s similar reasoning-like model. DeepSeek’s chatbot app began topping the charts in mobile app stores, including in Apple Inc.’s US App Store that weekend and the Google Play Store a few days later. Prominent figures including venture capitalist Marc Andreessen and OpenAI Chief Executive Officer Sam Altman praised it. That Monday investors erased almost $1 trillion from the value of US and European technology stocks, as DeepSeek raised the possibility that the tech industry had vastly overspent on AI infrastructure.
The leaders of Chatbot Arena, Chiang and Anastasios Angelopoulos, also a postdoc at UC Berkeley, were nonplussed. “It’s honestly not super surprising that we see a model like this reach the top,” Angelopoulos says. “The ecosystem will continue evolving. In a month it’s not going to be DeepSeek-R1, it’s going to be a different model.”
Chatbot Arena isn’t the only project to provide publicly available AI benchmarks. Efforts like SWE-Bench or Humanity’s Last Exam assess how well cutting-edge AI models perform on various tasks, such as answering math or coding questions, or solving some of the hardest problems known to humans. There isn’t much standardization, and no official group oversees the methods by which the models are tested. Progress in the field is also so rapid that new models may quickly make existing assessments seem out-of-date. (Remember the Turing test?)
Chatbot Arena gauges how it actually feels to use each product. “Vibes is one way to put it; another way to put it is real-world use-case testing,” Chiang says. “If you’re OpenAI building ChatGPT, you care about your users.”
As of early February, Chatbot Arena had hosted more than 200 models in total, including those from Anthropic, Google, Meta Platforms, OpenAI and xAI, with 90 of them still available for users to try. Companies typically work with Chatbot Arena to get their models on the site, then pay for the costs incurred by users probing them. The site is open source, with its data and code available for others to use, and is supported by some outside grants, such as from venture capital firms Andreessen Horowitz and Sequoia Capital. Because it’s an academic research project, UC Berkeley students are mostly the ones who keep Chatbot Arena running.
Visitors are greeted by a pop-up warning that the site is a research project. They’re instructed to pose a question to two anonymous chatbots, then pick the one they like best. After voting, the name of each chatbot is revealed. Those votes are used to help create a rating that estimates the strength of each model; it’s a variation of the Elo system for chess, which assigns ratings based on the outcomes of head-to-head competitions.
Users have logged more than 2.6 million votes for their favorite language models so far. They don’t log in, so Chatbot Arena’s team members don’t know about individual users. They do categorize, generally, what kinds of prompts users like to offer the chatbots, though. Questions about computer programming and creative writing are especially popular, with example prompts such as “Write a poem in couplets that uses line breaks to create a feeling of movement and suspense; it should be about apples.”
Chatbot Arena rankings have an aura of definitiveness. In fact, they’re measuring something very specific: the reaction of Chatbot Arena’s audience (a population that appears to skew toward academically minded folks interested in topics such as machine learning). The ranking system is “really cool, and we like to submit to it, but it doesn’t really represent ‘Is this model good to work with? Is it easy for an enterprise to adopt?’” says Nick Frosst, co-founder of Cohere, which makes AI models and customizes them for businesses.
There are also some concerns about the potential for ratings to be manipulated. In a recent paper posted on Arxiv, an openly accessible archive of studies that aren’t peer-reviewed, researchers simulated vote-rigging to point out possible vulnerabilities on Chatbot Arena. Angelopoulos and Chiang say the site has a number of protections in place to guard against malicious use. They haven’t seen evidence of a successful attack against the site, Angelopoulos says.
Chiang, Angelopoulos and their collaborators are focused on how to improve the Chatbot Arena community, while also expanding the types of testing they do. They’ve begun to support other types of AI models, including image generators. Given the attention they’ve gotten, the researchers are also not ruling out the possibility that there’s a business to be had here. “Definitely, we are thinking about it,” Chiang says.