Allen Institute for AI phát hành bộ Tulu 2.5: Mô hình AI tiên tiến với DPO và PPO
- Bộ Tulu 2.5 của Allen Institute for AI đánh dấu bước tiến quan trọng trong huấn luyện mô hình sử dụng Direct Preference Optimization (DPO) và Proximal Policy Optimization (PPO).
- Bộ bao gồm các mô hình đa dạng được huấn luyện trên nhiều bộ dữ liệu để cải thiện mô hình phần thưởng và giá trị, nhằm nâng cao hiệu suất của mô hình ngôn ngữ trong tạo văn bản, tuân thủ hướng dẫn và lập luận.
- Các biến thể nổi bật: Tulu 2.5 PPO 13B UF Mean 70B UF RM (mô hình tốt nhất), Tulu 2.5 PPO 13B Chatbot Arena 2023 (cải thiện khả năng chatbot), Tulu 2.5 DPO 13B StackExchange 60K (sử dụng 60.000 mẫu từ StackExchange), Tulu 2.5 DPO 13B Nectar 60K (sử dụng dữ liệu tổng hợp chất lượng cao), Tulu 2.5 PPO 13B HH-RLHF 60K (sử dụng phản hồi chi tiết từ con người), Tulu 2.5 DPO 13B PRM Phase 2 (cải thiện lập luận toán học), Tulu 2.5 DPO 13B HelpSteer (cải thiện tính hữu ích và rõ ràng).
- Thành phần chính và phương pháp huấn luyện: Dữ liệu ưu tiên (prompt, phản hồi, xếp hạng), DPO (tối ưu hóa trực tiếp trên dữ liệu ưu tiên), PPO (huấn luyện mô hình phần thưởng rồi tối ưu hóa chính sách), mô hình phần thưởng và giá trị.
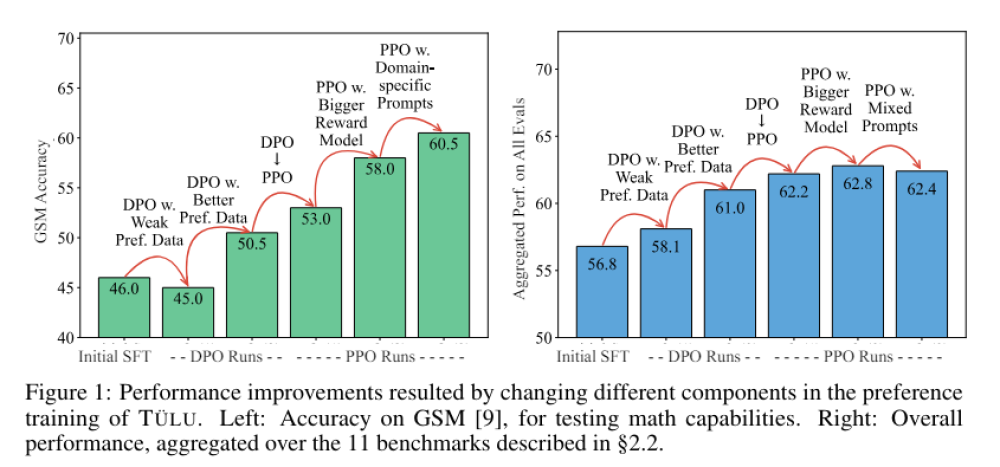
- Đánh giá hiệu suất trên nhiều tiêu chuẩn: tính xác thực, lập luận, mã hóa, tuân thủ hướng dẫn, an toàn. Mô hình PPO vượt trội hơn DPO.
- Cải tiến đáng chú ý: Tuân thủ hướng dẫn và tính trung thực tốt hơn, khả năng mở rộng với mô hình phần thưởng lên tới 70 tỷ tham số, dữ liệu tổng hợp như UltraFeedback rất hiệu quả.
📌 Bộ Tulu 2.5 của Allen Institute for AI đại diện cho bước tiến đáng kể trong học tập dựa trên sở thích cho các mô hình ngôn ngữ. Với các phương pháp huấn luyện tiên tiến và sử dụng các bộ dữ liệu chất lượng cao, bộ này thiết lập tiêu chuẩn mới cho hiệu suất và độ tin cậy của mô hình AI, mở ra tiềm năng ứng dụng rộng rãi trong tạo văn bản, lập luận, mã hóa và nhiều lĩnh vực khác.
https://www.marktechpost.com/2024/06/16/allen-institute-for-ai-releases-tulu-2-5-suite-on-hugging-face-advanced-ai-models-trained-with-dpo-and-ppo-featuring-reward-and-value-models/



Thảo luận
Follow Us
Tin phổ biến
