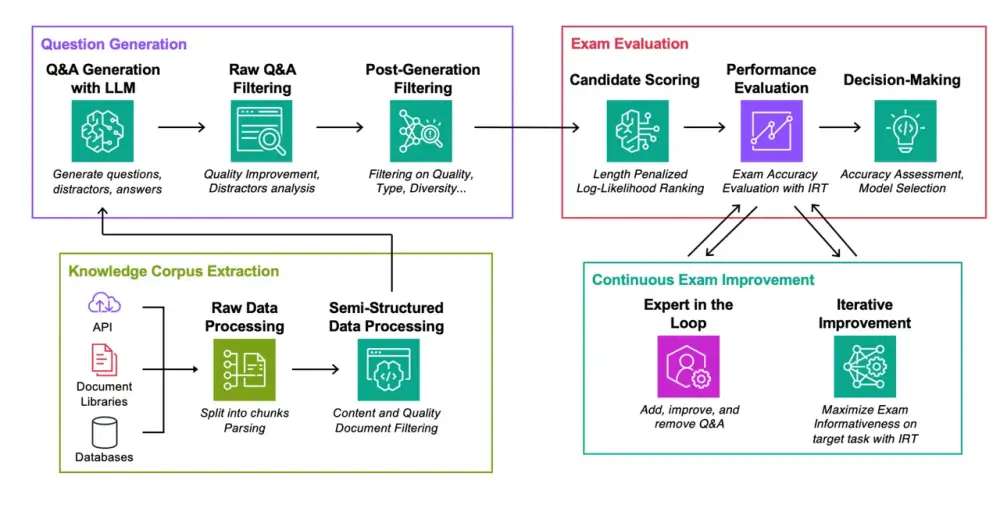
Amazon đề xuất benchmark đánh giá mới cho RAG
• Amazon AWS đề xuất một bộ tiêu chuẩn đánh giá mới cho phương pháp tạo sinh được tăng cường bởi truy xuất dữ liệu ngoài (RAG) trong bài báo "Đánh giá tự động các mô hình ngôn ngữ được tăng cường bởi truy xuất với việc tạo bài kiểm tra theo nhiệm vụ cụ thể".
• RAG là một phương pháp kết nối mô hình ngôn ngữ lớn với cơ sở dữ liệu chứa nội dung chuyên biệt như tài liệu công ty. Nó được kỳ vọng sẽ thúc đẩy việc áp dụng AI tạo sinh trong doanh nghiệp.
• Phương pháp đánh giá mới của Amazon tạo ra các cặp câu hỏi-câu trả lời từ 4 lĩnh vực: tài liệu xử lý sự cố của AWS, tóm tắt bài báo khoa học từ arXiv, câu hỏi trên StackExchange và hồ sơ từ Ủy ban Chứng khoán Mỹ.
• Các nhà nghiên cứu đã thử nghiệm hai họ mô hình nguồn mở là Mistral và Llama trong 3 kịch bản: không truy cập dữ liệu RAG, truy cập chính xác tài liệu gốc, và tìm kiếm trong toàn bộ tập dữ liệu.
• Kết quả cho thấy việc lựa chọn phương pháp truy xuất phù hợp có thể mang lại cải thiện hiệu suất vượt trội so với việc chỉ đơn giản tăng kích thước mô hình ngôn ngữ.
• Tuy nhiên, nếu thuật toán RAG không phù hợp, nó có thể làm giảm hiệu suất của mô hình so với phiên bản không sử dụng RAG.
• Phương pháp đánh giá này được cho là tự động, tiết kiệm chi phí, dễ hiểu và mạnh mẽ để lựa chọn các thành phần tối ưu cho hệ thống RAG.
• Bài báo sẽ được trình bày tại Hội nghị Quốc tế lần thứ 41 về Học máy diễn ra từ ngày 21-27/7 tại Vienna.
📌 Amazon đề xuất tiêu chuẩn đánh giá mới cho RAG, cho thấy lựa chọn thuật toán phù hợp có thể cải thiện hiệu suất AI hơn là tăng kích thước mô hình. Phương pháp này tạo bài kiểm tra từ 4 lĩnh vực, thử nghiệm trên Mistral và Llama, nhấn mạnh tầm quan trọng của việc tối ưu hóa RAG.
https://www.zdnet.com/article/amazon-proposes-a-new-ai-benchmark-to-measure-rag/



Thảo luận
Follow Us
Tin phổ biến
