Apple công bố nghiên cứu chỉ ra các mô hình AI dựa trên LLM còn thiếu kỹ năng suy luận cơ bản
• Apple vừa công bố một nghiên cứu mới chỉ ra rằng các mô hình AI dựa trên LLM như của Meta và OpenAI vẫn thiếu kỹ năng suy luận cơ bản.
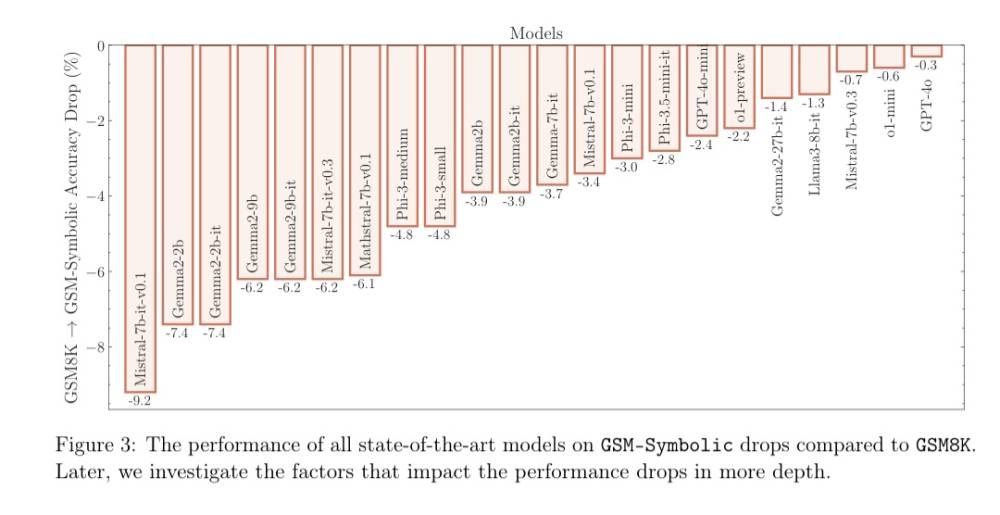
• Nhóm nghiên cứu đề xuất một tiêu chuẩn đánh giá mới có tên GSM-Symbolic để đo lường khả năng suy luận của các mô hình LLM.
• Kết quả thử nghiệm ban đầu cho thấy chỉ cần thay đổi nhỏ trong cách diễn đạt câu hỏi có thể dẫn đến các câu trả lời khác nhau đáng kể, làm suy giảm độ tin cậy của các mô hình.
• Nghiên cứu tập trung vào tính "mong manh" của suy luận toán học bằng cách thêm thông tin ngữ cảnh vào câu hỏi mà con người có thể hiểu, nhưng không nên ảnh hưởng đến phép toán cơ bản của lời giải.
• Kết quả cho thấy hiệu suất của tất cả các mô hình đều giảm khi chỉ thay đổi các giá trị số trong câu hỏi trong tiêu chuẩn GSM-Symbolic.
• Việc thêm chỉ một câu có vẻ cung cấp thông tin liên quan vào một bài toán có thể làm giảm độ chính xác của câu trả lời cuối cùng tới 65%.
• Nghiên cứu kết luận rằng không thể xây dựng các tác nhân đáng tin cậy trên nền tảng này, khi chỉ cần thay đổi một vài từ hoặc thêm một chút thông tin không liên quan có thể cho ra câu trả lời khác.
• Một ví dụ minh họa vấn đề là bài toán yêu cầu hiểu thực sự về câu hỏi. Nhiệm vụ được gọi là "GSM-NoOp" tương tự như các bài toán đố mà học sinh tiểu học có thể gặp.
• Câu hỏi bắt đầu với thông tin cần thiết để đưa ra kết quả, sau đó thêm một mệnh đề có vẻ liên quan nhưng thực tế không ảnh hưởng đến câu trả lời cuối cùng.
• Mô hình của OpenAI và Llama3-8b của Meta đã trừ 5 quả kiwi nhỏ hơn khỏi tổng số, mặc dù điều này không nên ảnh hưởng đến kết quả.
• Nghiên cứu kết luận không tìm thấy bằng chứng về suy luận chính thức trong các mô hình ngôn ngữ. Hành vi của LLM được giải thích tốt hơn bằng "khớp mẫu tinh vi".
• Nghiên cứu này được hỗ trợ bởi một nghiên cứu trước đó từ năm 2019, cho thấy có thể đánh lừa các mô hình AI một cách đáng tin cậy bằng cách đặt câu hỏi về tuổi của hai cầu thủ Super Bowl trước đây.
📌 Apple chứng minh các mô hình AI dựa trên LLM thiếu khả năng suy luận cơ bản. Nghiên cứu sử dụng tiêu chuẩn GSM-Symbolic cho thấy thay đổi nhỏ trong câu hỏi có thể làm giảm độ chính xác tới 65%. Kết luận: không thể xây dựng AI đáng tin cậy trên nền tảng này.
https://appleinsider.com/articles/24/10/12/apples-study-proves-that-llm-based-ai-models-are-flawed-because-they-cannot-reason



Thảo luận
Follow Us
Tin phổ biến
