Bảng xếp hạng gây sốc về mức độ an toàn của các công ty AI - Meta và xAI nhận điểm kém nhất
• Future of Life Institute vừa công bố báo cáo đánh giá mức độ an toàn của các công ty AI hàng đầu thế giới vào ngày 12/12/2024.
• Báo cáo được thực hiện bởi 7 chuyên gia độc lập, trong đó có giáo sư Yoshua Bengio - người đạt giải Turing và Sneha Revanur từ tổ chức Encode Justice.
• Các tiêu chí đánh giá bao gồm: đánh giá rủi ro, tác hại hiện tại, framework an toàn, chiến lược an toàn hiện hữu, quản trị & trách nhiệm giải trình, minh bạch & truyền thông.
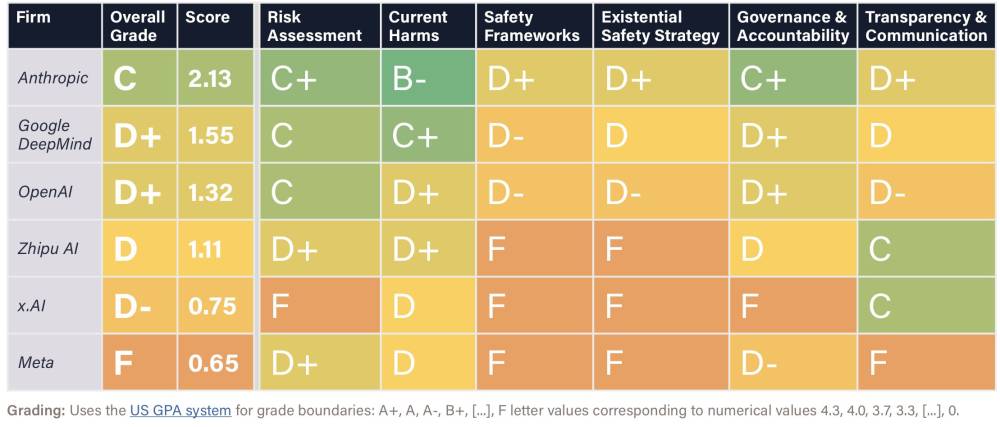
• Kết quả xếp hạng cụ thể:
- Anthropic (phát triển chatbot Claude): điểm C
- OpenAI và Google DeepMind: điểm D+
- x.AI của Elon Musk: điểm D-
- Meta (công ty mẹ của Facebook): điểm F
- Zhipu AI (công ty Trung Quốc): điểm D
• Tất cả các mô hình AI chủ lực đều tồn tại lỗ hổng "jailbreak" - kỹ thuật vượt qua các rào cản bảo vệ của hệ thống.
• Các chiến lược hiện tại của mọi công ty đều được đánh giá là chưa đủ để đảm bảo an toàn cho các hệ thống AI trong tương lai khi chúng có thể sánh ngang trí thông minh con người.
• Giáo sư Tegan Maharaj từ HEC Montreal nhấn mạnh cần có giám sát độc lập thay vì chỉ dựa vào đánh giá nội bộ của các công ty.
• Một số công ty như Zhipu AI, x.AI và Meta thậm chí chưa thực hiện các biện pháp an toàn cơ bản theo hướng dẫn hiện có.
📌 Báo cáo từ Future of Life Institute cho thấy thực trạng đáng lo ngại về an toàn AI: Anthropic dẫn đầu với điểm C, trong khi Meta đứng cuối với điểm F. Tất cả mô hình đều có lỗ hổng jailbreak và thiếu chiến lược đảm bảo an toàn dài hạn.
https://time.com/7202030/ai-companies-safety-report-openai-meta-anthropic/
#TIME
Key Findings
- Large risk management disparities: While some companies have established initial safety frameworks or conducted some serious risk assessment efforts, others have yet to take even the most basic precautions.
- Jailbreaks: All the flagship models were found to be vulnerable to adversarial attacks.
- Control-Problem: Despite their explicit ambitions to develop artificial general intelligence (AGI), capable of rivaling or exceeding human intelligence, the review panel deemed the current strategies of all companies inadequate for ensuring that these systems remain safe and under human control.
- External oversight: Reviewers consistently highlighted how companies were unable to resist profit-driven incentives to cut corners on safety in the absence of independent oversight. While Anthropic’s current and OpenAI’s initial governance structures were highlighted as promising, experts called for third-party validation of risk assessment and safety framework compliance across all companies
Những phát hiện chính
- Chênh lệch lớn trong quản lý rủi ro: Một số công ty đã thiết lập các khung an toàn ban đầu hoặc thực hiện các nỗ lực đánh giá rủi ro nghiêm túc, trong khi một số khác vẫn chưa áp dụng các biện pháp cơ bản nhất.
- Dễ bị tấn công (Jailbreaks): Tất cả các mẫu sản phẩm hàng đầu đều được phát hiện là dễ bị tấn công bởi các cuộc tấn công đối kháng.
- Vấn đề kiểm soát: Mặc dù có tham vọng rõ ràng trong việc phát triển trí tuệ nhân tạo tổng quát (AGI) có khả năng ngang hoặc vượt qua trí thông minh con người, hội đồng đánh giá cho rằng các chiến lược hiện tại của tất cả các công ty đều không đủ để đảm bảo các hệ thống này an toàn và nằm trong sự kiểm soát của con người.
- Giám sát độc lập: Các nhà đánh giá liên tục nhấn mạnh rằng các công ty không thể chống lại các động lực lợi nhuận dẫn đến việc lơ là an toàn nếu thiếu sự giám sát độc lập. Trong khi cấu trúc quản trị hiện tại của Anthropic và ban đầu của OpenAI được coi là triển vọng, các chuyên gia đã kêu gọi cần có sự xác nhận từ bên thứ ba đối với việc đánh giá rủi ro và tuân thủ các khung an toàn ở tất cả các công ty.
https://futureoflife.org/document/fli-ai-safety-index-2024/



Thảo luận
Follow Us
Tin phổ biến
