Cách mở rộng quy mô RAG và xây dựng các mô hình ngôn ngữ lớn chính xác hơn
- Retrieval augmented generation (RAG) nổi lên như một mô hình hàng đầu để giải quyết các vấn đề về tăng độ chính xác của các mô hình ngôn ngữ lớn (LLM).
- Các LLM nền tảng như GPT và Llama thường tạo ra nội dung sai lệch vì dữ liệu huấn luyện chủ yếu từ internet công khai. Chúng cũng không thể tiếp cận dữ liệu nội bộ của doanh nghiệp.
- RAG cho phép các nhóm dữ liệu cung cấp ngữ cảnh cho các lời nhắc bằng dữ liệu cụ thể của công ty, giúp LLM xác định đúng mẫu hình và đưa ra phản hồi chính xác, phù hợp.
- Việc huấn luyện lại LLM trên dữ liệu riêng của công ty rất tốn kém. Fine-tuning mô hình hiện có đòi hỏi chuyên môn cao. RAG là lựa chọn tốt nhất hiện nay.
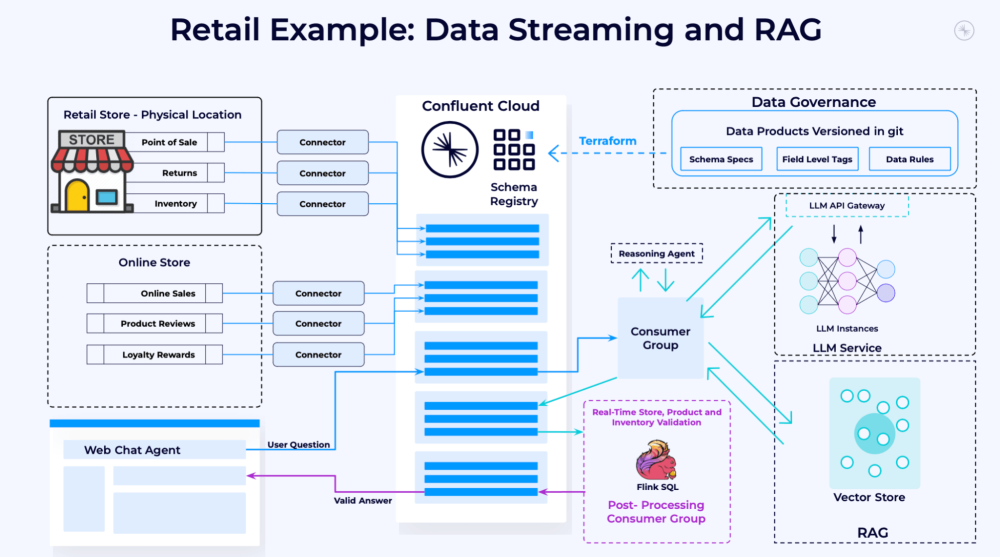
- RAG cần được triển khai theo cách cung cấp thông tin chính xác, cập nhật và có thể mở rộng quy mô. Kiến trúc hướng sự kiện (event-driven) là phù hợp nhất cho điều này.
- Kiến trúc hướng sự kiện giúp tích hợp dữ liệu từ nhiều nguồn khác nhau theo thời gian thực, đảm bảo độ tin cậy. Nó cũng cho phép các nhóm ứng dụng và dữ liệu làm việc độc lập.
- Quy trình RAG gồm các bước: bổ sung dữ liệu, suy luận, quy trình làm việc và hậu xử lý. Nền tảng dữ liệu streaming giúp tách rời các nhóm và công nghệ để mở rộng quy mô độc lập.
- RAG cần có cơ chế cung cấp dữ liệu cho phép xây dựng nhiều ứng dụng AI tạo sinh mà không cần phát minh lại, đáp ứng các tiêu chuẩn quản trị và chất lượng dữ liệu.
📌 Mô hình dữ liệu streaming là cách đơn giản và hiệu quả nhất để đáp ứng các nhu cầu trên, cho phép các nhóm phát huy sức mạnh của LLM để tạo ra giá trị mới. Với mô hình vận hành chung cho các ứng dụng RAG, doanh nghiệp có thể đưa use case đầu tiên ra thị trường nhanh chóng, đồng thời tăng tốc độ cung cấp và giảm chi phí cho các use case tiếp theo.
https://thenewstack.io/how-to-scale-rag-and-build-more-accurate-llms/



Thảo luận
Follow Us
Tin phổ biến
