Cách tốt nhất để kiểm soát AI ngày nay là gì?
- Bài viết trên Forbes đề cập đến vấn đề kiểm soát AI hiện đại thông qua công nghệ được gọi là Reinforcement Learning from Human Feedback (RLHF).
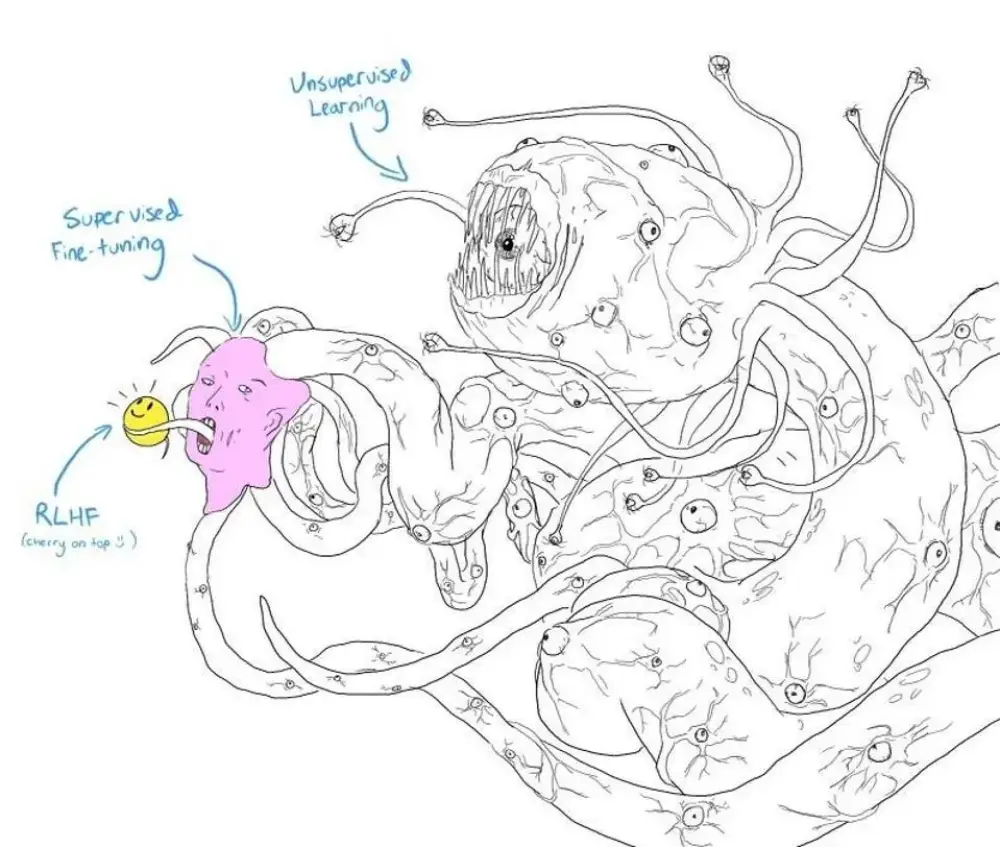
- RLHF là phương pháp chủ đạo giúp con người hướng dẫn và điều khiển hành vi của mô hình AI, đặc biệt là các mô hình ngôn ngữ. Phương pháp này ảnh hưởng đến trải nghiệm AI của hàng triệu người trên toàn thế giới.
- Mục tiêu của RLHF là làm cho mô hình AI trở nên "hữu ích, trung thực và không gây hại", có thể bao gồm việc ngăn cản mô hình tạo ra các bình luận phân biệt chủng tộc hoặc giúp người dùng vi phạm pháp luật.
- RLHF được sử dụng để tạo ra các tính cách khác nhau cho mô hình: từ chân thành đến mỉa mai, từ lảng mạn đến thô lỗ. Nó cũng có thể hướng dẫn mục tiêu cuối cùng của mô hình, chẳng hạn như bán một sản phẩm cụ thể hoặc chuyển đổi quan điểm chính trị.
- Công nghệ này được phát triển vào năm 2017 bởi nhóm nghiên cứu từ OpenAI và DeepMind và được OpenAI áp dụng vào mô hình GPT-3 để tạo ra InstructGPT vào đầu năm 2022, và sau đó là ChatGPT, trở thành ứng dụng tiêu dùng phát triển nhanh nhất trong lịch sử.
- RLHF cũng là thành phần không thể thiếu trong việc xây dựng mô hình ngôn ngữ tiên tiến, từ Claude của Anthropic đến Bard của Google và Llama 2 của Meta.
📌 Phương pháp Học tăng cường từ Phản hồi Con Người (RLHF) hiện là công cụ mạnh mẽ nhất để điều khiển và hình thành hành vi của AI, đặc biệt là trong các mô hình ngôn ngữ. RLHF không chỉ ảnh hưởng đến cách AI hoạt động mà còn định hình trải nghiệm của hàng triệu người dùng với AI mỗi ngày. Kỹ thuật này đã được áp dụng thành công vào các sản phẩm như InstructGPT và ChatGPT của OpenAI, đồng thời là yếu tố quan trọng trong sự phát triển của các mô hình ngôn ngữ khác như Claude, Bard và Llama 2. RLHF không chỉ quan trọng đối với hiện tại mà còn đóng vai trò thiết yếu trong tương lai của việc xây dựng và kiểm soát AI một cách an toàn và hiệu quả.



Thảo luận
Follow Us
Tin phổ biến

TAG
AI giáo dục
AI sinh-y-duoc
AI nghệ thuật
AI pháp lý-quản trị-chủ quyền
AI models
AI xã hội
AI prompts
AI kiến thức-khóa học
AI công nghiệp-lĩnh vực
AI edge
AI viễn thông
AI tools
AI chính phủ
AI cybersecurity
AI so sánh
AI đạo đức
AI tips
AI market
AI quân sự
AI an toàn-an ninh-techwar
AI việc làm
AI doanh nghiệp
OpenAI ChatGPT
AI môi trường-năng lượng
AI skill-talent
AI & công nghệ khác
AI nghiên cứu
AI chips-hardware-compute
AI vs con người
AI coding assistant
AI mở-nguồn mở
AI năng suất
AI startup-M&A
AI tương lai
AI báo chí
AI data
AI bản quyền
AI PC
AI riêng tư
AI deepfake-ảo giác-ANTT
AI ảnh-video-music-âm thanh
AI minh bạch
AI nhỏ
AI nông nghiệp-thực phẩm
AI ngân hàng-tài chính
AI giao thông
AI smartphone
AI robotics-auto-agents
AI consumer devices
AI manufacturing
AI benchmark
Telecom
AI thành công-thất bại
Digital
Semi-Cloud-DC-Green
HTS
STI
FAQ