ChatQA 2: Mô hình AI của Nvidia dựa trên Llama3 với khả năng xử lý ngữ cảnh dài và RAG nâng cao, cạnh tranh với GPT-4-Turbo
• Nvidia giới thiệu ChatQA 2, một mô hình dựa trên Llama3 nhằm cải thiện khả năng xử lý ngữ cảnh dài và tạo sinh được tăng cường bởi truy xuất dữ liệu ngoài (RAG) trong các mô hình ngôn ngữ lớn (LLM).
• ChatQA 2 mở rộng cửa sổ ngữ cảnh từ 8K lên 128K token thông qua quá trình tiền huấn luyện liên tục trên tập dữ liệu SlimPajama với các chuỗi dài được lấy mẫu tăng cường.
• Mô hình sử dụng quy trình huấn luyện theo hướng dẫn 3 giai đoạn, tập trung vào việc tuân theo hướng dẫn, hiệu suất RAG và hiểu ngữ cảnh dài.
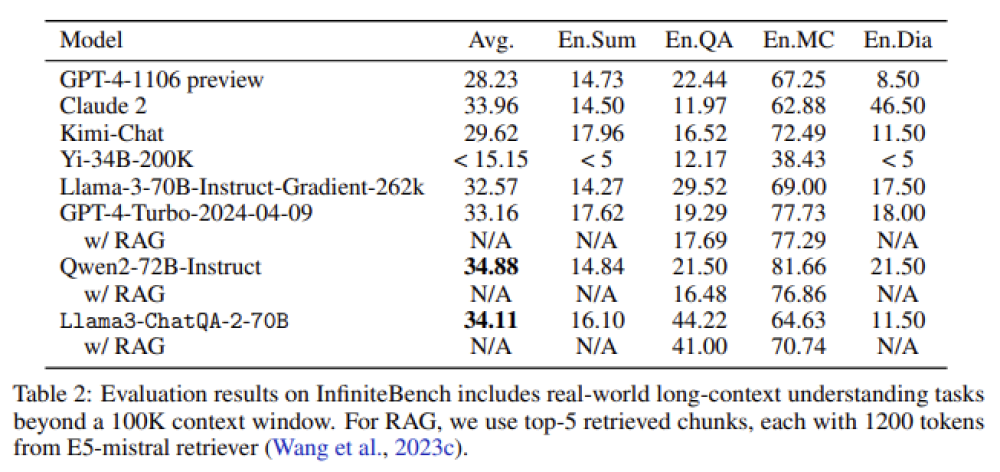
• Trong đánh giá InfiniteBench, ChatQA 2 đạt điểm trung bình 34,11, gần với điểm cao nhất 34,88 của Qwen2-72B-Instruct.
• ChatQA 2 xuất sắc trong các nhiệm vụ ngữ cảnh trung bình-dài (trong 32K token) với điểm 47,37 và các tác vụ ngữ cảnh ngắn (trong 4K token) với điểm trung bình 54,81.
• Mô hình giải quyết các vấn đề trong quy trình RAG như phân mảnh ngữ cảnh và tỷ lệ truy xuất thấp bằng cách sử dụng bộ truy xuất ngữ cảnh dài tiên tiến.
• ChatQA 2 sử dụng mô hình nhúng E5-mistral hỗ trợ tối đa 32K token cho truy xuất, cải thiện đáng kể hiệu suất trên các tác vụ dựa trên truy vấn.
• So sánh giữa RAG và giải pháp ngữ cảnh dài cho thấy ChatQA 2 liên tục thể hiện kết quả vượt trội, đặc biệt trong các chức năng yêu cầu xử lý văn bản mở rộng.
• Mô hình cung cấp giải pháp linh hoạt cho nhiều tác vụ hạ nguồn, cân bằng giữa độ chính xác và hiệu quả thông qua các kỹ thuật ngữ cảnh dài và RAG tiên tiến.
• ChatQA 2 đạt được khả năng ngang tầm GPT-4-Turbo trong hiểu ngữ cảnh dài và hiệu suất RAG, đánh dấu bước tiến quan trọng trong lĩnh vực mô hình ngôn ngữ lớn.
📌 ChatQA 2 của Nvidia mở rộng cửa sổ ngữ cảnh lên 128K token, đạt hiệu suất ngang GPT-4-Turbo trong xử lý ngữ cảnh dài và RAG. Mô hình cải thiện đáng kể khả năng truy xuất thông tin và xử lý văn bản mở rộng, đạt điểm trung bình 34,11 trong InfiniteBench.
https://www.marktechpost.com/2024/07/24/nvidia-ai-proposes-chatqa-2-a-llama3-based-model-for-enhanced-long-context-understanding-and-rag-capabilities/



Thảo luận
Follow Us
Tin phổ biến
