Có thể chuyển khả năng của LLM như LLaMA từ tiếng Anh sang ngôn ngữ không phải tiếng Anh không?
- Các mô hình Ngôn ngữ Lớn (LLMs) như ChatGPT, PaLM, và LLaMA đã đạt được những bước tiến quan trọng trong việc xử lý ngôn ngữ phức tạp và học tập trải nghiệm. Tuy nhiên, hầu hết các LLMs chính thống như LLaMA được huấn luyện trên cơ sở dữ liệu chủ yếu bằng tiếng Anh, hạn chế hiệu suất khi xử lý các ngôn ngữ khác.
- Mặc dù nhiều LLMs có khả năng hiểu nhiều ngôn ngữ, sự mất cân đối trong nguồn tài nguyên ngôn ngữ vẫn là một thách thức. Ví dụ, BLOOM được tiền huấn luyện trên 46 ngôn ngữ nhưng vẫn thiếu đa dạng, và LLaMA gặp khó khăn với ngôn ngữ không phải tiếng Anh.
- Các nhà nghiên cứu tại Trường Khoa học Máy tính, Đại học Fudan, đã tập trung vào việc chuyển giao khả năng tạo ngôn ngữ và tuân theo hướng dẫn sang các ngôn ngữ không phải tiếng Anh. Họ đã phân tích ảnh hưởng của các yếu tố như mở rộng từ vựng, tiền huấn luyện thêm, và chỉnh sửa hướng dẫn.
- Nghiên cứu này khám phá việc chuyển giao khả năng tạo ngôn ngữ và tuân theo hướng dẫn sang ngôn ngữ không phải tiếng Anh sử dụng LLaMA. Sử dụng tiếng Trung làm điểm xuất phát, nghiên cứu mở rộng kết quả sang hơn mười ngôn ngữ ít tài nguyên. Các mô hình bao gồm LLaMA, LLaMA2, Chinese LLaMA, Chinese LLaMA2, và Open Chinese LLaMA.
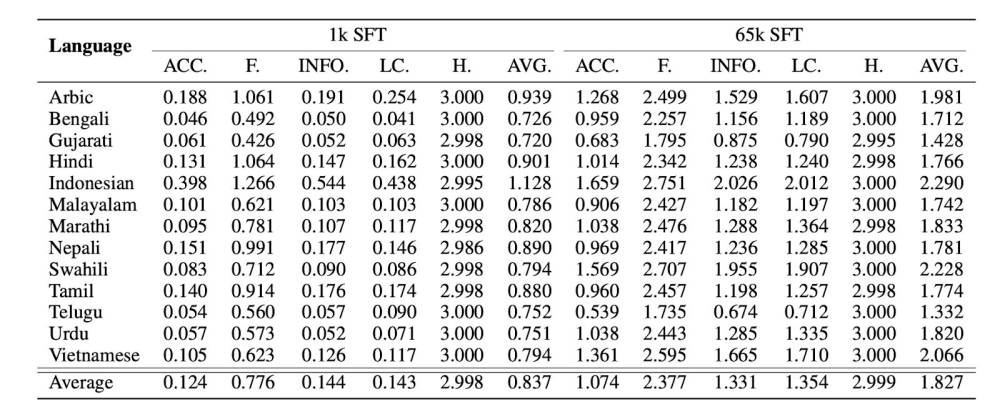
- Nghiên cứu này điều tra việc chuyển ngôn ngữ sang các ngôn ngữ không phải tiếng Anh sử dụng LLaMA, tập trung vào việc mở rộng từ vựng, ảnh hưởng của quy mô huấn luyện, và khả năng đa ngôn ngữ. Việc mở rộng từ vựng làm giảm hiệu suất trong tiếng Trung. Đánh giá trên 13 ngôn ngữ ít tài nguyên cho thấy dữ liệu SFT nâng cao chất lượng phản hồi.
- Nghiên cứu này tập trung vào việc chuyển giao khả năng tạo ngôn ngữ và tuân theo hướng dẫn sang một ngôn ngữ không phải tiếng Anh. Họ phát hiện ra rằng việc mở rộng từ vựng không cần thiết và hiệu suất chuyển giao tương đương với các mô hình tiên tiến có thể đạt được với ít hơn 1% dữ liệu tiền huấn luyện thêm. Kết quả tương tự được quan sát từ các thí nghiệm mở rộng trên 13 ngôn ngữ ít tài nguyên.
📌 Các Mô hình Ngôn ngữ Lớn (LLMs) như ChatGPT, PaLM, và LLaMA đã thể hiện sự tiến bộ đáng kể trong xử lý ngôn ngữ phức tạp và học tập từ kinh nghiệm. Tuy nhiên, hạn chế về nguồn ngôn ngữ, với sự chiếm ưu thế của tiếng Anh trong dữ liệu huấn luyện, đã làm giảm hiệu suất của các LLMs khi xử lý các ngôn ngữ khác. Nghiên cứu gần đây tại Đại học Phục Đán tập trung vào việc chuyển giao khả năng tạo ngôn ngữ và tuân theo hướng dẫn sang các ngôn ngữ không phải tiếng Anh. Họ khám phá việc mở rộng từ vựng, tiền huấn luyện thêm, và chỉnh sửa hướng dẫn, đạt được kết quả ấn tượng với ít dữ liệu huấn luyện thêm. Nghiên cứu này cho thấy tiềm năng lớn trong việc phát triển LLMs đa ngôn ngữ, giúp cải thiện độ chính xác và đa dạng trong xử lý ngôn ngữ, mở ra cơ hội mới cho người dùng không nói tiếng Anh trên toàn cầu.



Thảo luận
Follow Us
Tin phổ biến
