Compositional GSM: Thước đo mới đánh giá khả năng suy luận đa bước của AI trong giải toán
• Các nhà nghiên cứu từ Mila, Google DeepMind và Microsoft Research đã giới thiệu phương pháp đánh giá mới có tên "Compositional Grade-School Math (GSM)" để kiểm tra khả năng suy luận của mô hình ngôn ngữ lớn (LLM).
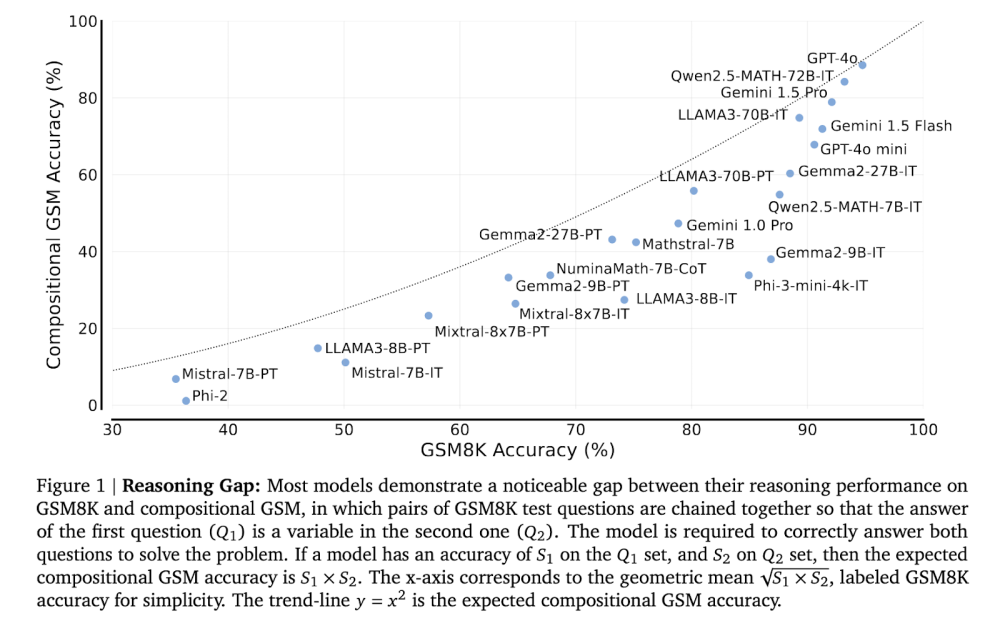
• Phương pháp này liên kết hai bài toán riêng biệt, trong đó lời giải của bài toán đầu trở thành biến số trong bài toán thứ hai, đòi hỏi mô hình phải xử lý các phụ thuộc giữa các câu hỏi.
• Đánh giá được thực hiện trên nhiều LLM khác nhau, bao gồm cả mô hình mở như LLAMA3 và mô hình đóng như GPT và Gemini, sử dụng phương pháp gợi ý 8-shot.
• Kết quả cho thấy khoảng cách lớn về khả năng suy luận. Ví dụ, mô hình GPT-4o mini có hiệu suất kém hơn 2-12 lần trên Compositional GSM so với GSM8K tiêu chuẩn.
• Mô hình chuyên biệt về toán học như Qwen2.5-MATH-72B chỉ giải được dưới 60% bài toán Compositional GSM cấp tiểu học, dù đạt trên 80% độ chính xác với câu hỏi cấp trung học.
• LLAMA3-8B và Mistral-7B cho thấy sự sụt giảm mạnh khi phải liên kết câu trả lời giữa các bài toán liên quan, dù đạt điểm cao trên các bài toán riêng lẻ.
• Việc điều chỉnh hướng dẫn cải thiện kết quả cho các mô hình nhỏ hơn trên GSM8K tiêu chuẩn, nhưng chỉ cải thiện nhẹ trên Compositional GSM.
• Tạo mã thay vì sử dụng ngôn ngữ tự nhiên dẫn đến cải thiện 71% đến 149% cho một số mô hình nhỏ hơn trên Compositional GSM.
• Phân tích cho thấy sự sụt giảm hiệu suất không phải do rò rỉ bộ kiểm tra mà do nhiễu loạn bởi ngữ cảnh bổ sung và suy luận kém ở bước thứ hai.
• Mô hình như LLAMA3-70B-IT và Gemini 1.5 Pro thường không áp dụng chính xác lời giải của câu hỏi đầu tiên khi giải câu hỏi thứ hai, dẫn đến câu trả lời cuối cùng không chính xác.
• Khoảng cách suy luận ở bước thứ hai rõ rệt hơn ở các mô hình nhỏ hơn, thường bỏ qua các chi tiết quan trọng khi giải quyết vấn đề phức tạp.
📌 Nghiên cứu cho thấy LLM hiện tại vẫn gặp khó khăn với các tác vụ suy luận phức hợp, dù có hiệu suất cao trên các bài kiểm tra tiêu chuẩn. Cần có chiến lược đào tạo và thiết kế đánh giá mạnh mẽ hơn để nâng cao khả năng suy luận đa bước của các mô hình AI.
https://www.marktechpost.com/2024/10/06/compositional-gsm-a-new-ai-benchmark-for-evaluating-large-language-models-reasoning-capabilities-in-multi-step-problems/



Thảo luận
Follow Us
Tin phổ biến
