Cuộc chiến bắt đầu cho tính toán suy luận AI trong trung tâm dữ liệu
- Cuộc chiến về tính toán suy luận AI trong các trung tâm dữ liệu đang diễn ra mạnh mẽ, với sự tham gia của các nhà cung cấp điện toán đám mây lớn và các công ty khởi nghiệp chip AI.
- Các nhà cung cấp điện toán đám mây chủ yếu sử dụng GPU của Nvidia và các bộ tăng tốc tự phát triển, trong khi một số công ty như AMD cũng đang tham gia.
- Chi phí cho suy luận AI trong trung tâm dữ liệu đang là một yếu tố chính cản trở việc triển khai GenAI trong doanh nghiệp, với dự đoán rằng nhu cầu về năng lực suy luận có thể gấp 3 đến 10 lần so với năng lực đào tạo AI hiện tại.
- Để giảm chi phí suy luận, cần phải có phần cứng mạnh mẽ hơn, không chỉ đơn giản là các chip giá rẻ.
- Groq đã giới thiệu hệ thống xử lý suy luận sử dụng 576 đơn vị xử lý ngôn ngữ (LPU), cho phép xử lý 315,06 token mỗi giây, nhanh hơn gấp 10 lần so với hệ thống Nvidia DGX H100.
- Cerebras cũng đã công bố dịch vụ suy luận mới trên nền tảng waferscale CS-2 của mình, với hiệu suất gấp 20 lần so với các API LLM trên đám mây.
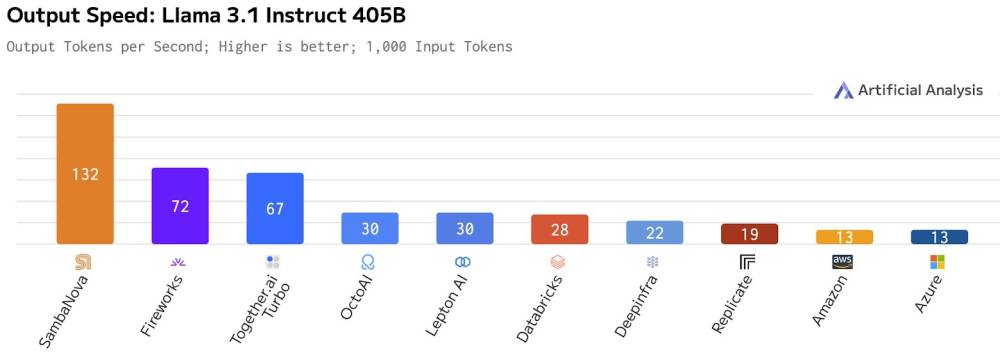
- SambaNova tham gia vào cuộc chiến này với hệ thống của mình, đạt hiệu suất 1.100 token mỗi giây cho mô hình Llama 3.1 8B.
- Các công ty khởi nghiệp chip AI đang chuyển hướng sang suy luận, tìm cách chuyển đổi khách hàng từ thuê dịch vụ sang mua hệ thống.
- Mặc dù chi phí suy luận cao, nhưng nếu có thể giảm xuống 1/10 chi phí hiện tại, doanh thu từ suy luận có thể ngang bằng hoặc vượt qua doanh thu từ đào tạo AI.
- Các dịch vụ suy luận đang trở thành chiến lược quan trọng để các công ty khởi nghiệp chip AI kiếm tiền, mặc dù nhiều người vẫn nghi ngờ về khả năng sinh lời của lĩnh vực này.
📌 Suy luận AI đang trở thành một lĩnh vực cạnh tranh khốc liệt với sự tham gia của nhiều công ty, trong đó Groq, Cerebras và SambaNova đang dẫn đầu về hiệu suất và chi phí. Chi phí suy luận cần giảm đáng kể để mở rộng quy mô và thúc đẩy việc áp dụng GenAI trong doanh nghiệp.
https://www.nextplatform.com/2024/09/10/the-battle-begins-for-ai-inference-compute-in-the-datacenter/



Thảo luận
Follow Us
Tin phổ biến
