Cuộc đua khai thác dữ liệu huấn luyện chatbot AI có thể hết văn bản do con người viết
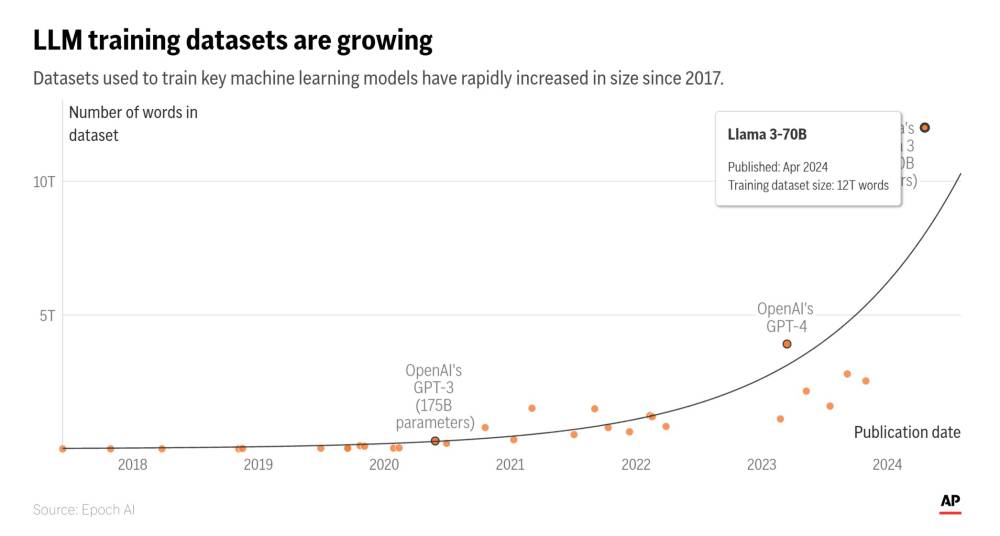
- Nghiên cứu của Epoch AI dự báo các công ty công nghệ sẽ cạn kiệt nguồn cung cấp dữ liệu huấn luyện công khai cho các mô hình ngôn ngữ AI vào khoảng năm 2026-2032.
- Các công ty như OpenAI và Google đang chạy đua để đảm bảo các nguồn dữ liệu chất lượng cao để huấn luyện các mô hình ngôn ngữ lớn của AI.
- Trong dài hạn, sẽ không đủ blog, bài báo tin tức và bình luận trên mạng xã hội mới để duy trì tốc độ phát triển AI hiện tại.
- Các công ty sẽ phải sử dụng dữ liệu nhạy cảm như email, tin nhắn hoặc dữ liệu tổng hợp kém tin cậy do chính chatbot tạo ra.
- Lượng dữ liệu văn bản cấp cho các mô hình ngôn ngữ AI tăng khoảng 2.5 lần/năm, trong khi khả năng tính toán tăng khoảng 4 lần/năm.
- Xây dựng các hệ thống AI chuyên biệt hơn cho các tác vụ cụ thể cũng có thể giúp cải thiện AI mà không cần mở rộng mô hình.
- Huấn luyện trên dữ liệu do AI tạo ra có thể dẫn đến suy giảm hiệu suất và mã hóa thêm các lỗi, thiên vị trong hệ sinh thái thông tin.
- Các trang web như Reddit, Wikipedia và các nhà xuất bản tin tức, sách đang phải cân nhắc cách dữ liệu của họ được sử dụng cho huấn luyện AI.
- Trả tiền cho hàng triệu người để tạo ra văn bản huấn luyện AI có thể không hiệu quả về kinh tế để cải thiện hiệu suất kỹ thuật.
- OpenAI đã thử nghiệm tạo ra nhiều dữ liệu tổng hợp để huấn luyện thế hệ tiếp theo của mô hình GPT.
📌 Nghiên cứu của Epoch AI dự báo nguồn dữ liệu văn bản công khai để huấn luyện AI sẽ cạn kiệt vào khoảng 2026-2032. Các công ty đang chạy đua đảm bảo nguồn dữ liệu chất lượng cao, nhưng về lâu dài có thể phải dựa vào dữ liệu nhạy cảm hoặc do chính AI tạo ra, dẫn đến nguy cơ suy giảm hiệu suất và gia tăng sai lệch.
https://apnews.com/article/ai-artificial-intelligence-training-data-running-out-9676145bac0d30ecce1513c20561b87d



Thảo luận
Follow Us
Tin phổ biến
