DeepMind giới thiệu SCoRe - phương pháp mới giúp LLM tự sửa lỗi hiệu quả hơn, không cần dữ liệu bên ngoài
• Google DeepMind vừa công bố phương pháp mới có tên SCoRe (Self-Correction via Reinforcement Learning), giúp cải thiện đáng kể khả năng tự sửa lỗi của các mô hình ngôn ngữ lớn (LLM).
• SCoRe cho phép LLM tự phát hiện và sửa lỗi mà không cần dữ liệu bên ngoài, chỉ dựa vào kiến thức sẵn có của mô hình.
• Khả năng tự sửa lỗi rất quan trọng với LLM, giúp chúng có thể xem xét và tinh chỉnh câu trả lời nhiều lần để đạt kết quả chính xác.
• Các phương pháp trước đây như kỹ thuật prompt hay fine-tuning thường yêu cầu phản hồi từ bên ngoài hoặc một "oracle" để hướng dẫn quá trình tự sửa.
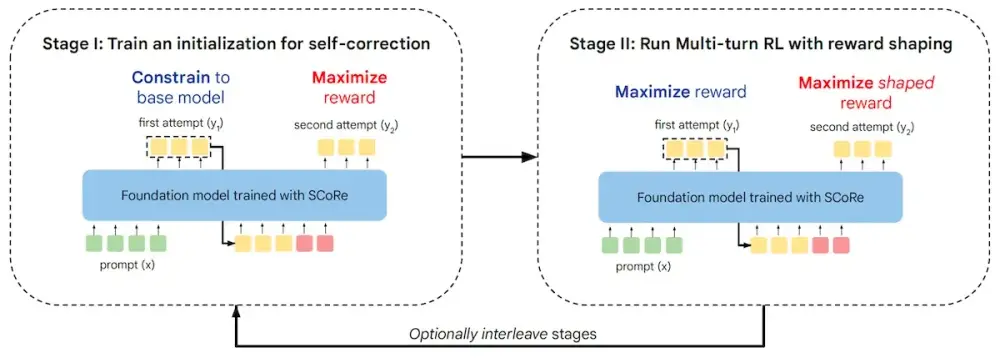
• SCoRe sử dụng học tăng cường (RL) để huấn luyện một mô hình duy nhất vừa tạo ra câu trả lời, vừa tự sửa lỗi mà không cần phản hồi bên ngoài.
• Quá trình huấn luyện gồm 2 giai đoạn với các kỹ thuật điều chỉnh để tránh "sụp đổ hành vi" - tình trạng mô hình chỉ tập trung vào câu trả lời cuối cùng mà bỏ qua các bước trung gian.
• Các thử nghiệm cho thấy SCoRe cải thiện đáng kể khả năng tự sửa lỗi của các mô hình Gemini 1.0 Pro và 1.5 Flash trên các bài toán về toán học và lập trình.
• Trên bộ dữ liệu MATH, SCoRe đạt mức cải thiện tuyệt đối 15.6% so với mô hình cơ sở. Trên HumanEval, mức cải thiện là 9.1%.
• SCoRe còn giúp giảm đáng kể trường hợp mô hình vô tình thay đổi câu trả lời đúng thành sai.
• Khi kết hợp với các chiến lược mở rộng thời gian suy luận như self-consistency, SCoRe còn cho phép cải thiện hiệu suất hơn nữa.
• Các nhà nghiên cứu tin rằng SCoRe có thể áp dụng cho nhiều ứng dụng khác, như giúp mô hình tự kiểm tra và cải thiện các đầu ra có khả năng không an toàn.
📌 SCoRe của DeepMind là bước đột phá trong việc cải thiện khả năng tự sửa lỗi của LLM, đạt mức cải thiện tuyệt đối 15.6% trên bộ dữ liệu MATH. Phương pháp này mở ra tiềm năng mới để nâng cao khả năng suy luận và giải quyết vấn đề của AI mà không cần dữ liệu bên ngoài.
https://venturebeat.com/ai/deepminds-score-shows-llms-can-use-their-internal-knowledge-to-correct-their-mistakes/



Thảo luận
Follow Us
Tin phổ biến
