Deepseek-AI ra mắt bộ 3 mô hình AI ngôn ngữ-thị giác siêu mạnh
• Deepseek-ai vừa công bố bộ mô hình Deepseek-vl2 nguồn mở gồm 3 phiên bản với số tham số khác nhau:
- Deepseek-vl2-tiny: 3,37 tỷ tham số (1,0 tỷ tham số được kích hoạt)
- Deepseek-vl2-small: 16,1 tỷ tham số (2,8 tỷ tham số được kích hoạt)
- Deepseek-vl2: 27,5 tỷ tham số (4,5 tỷ tham số được kích hoạt)
• Mô hình tích hợp các công nghệ tiên tiến:
- Dynamic tiling để mã hóa thông tin thị giác
- Cơ chế multi-head latent attention cho xử lý ngôn ngữ
- Framework deepseek-moe tối ưu hiệu năng
• Kết quả đánh giá ấn tượng:
- Độ chính xác 92,3% trong các tác vụ ocr với phiên bản small
- Cải thiện 15% độ chính xác trong visual grounding so với các mô hình tiền nhiệm
- Tiết kiệm 30% tài nguyên tính toán nhưng vẫn duy trì hiệu năng tốt nhất
• Các điểm nổi bật:
- Chia nhỏ ảnh độ phân giải cao thành các tile nhỏ hơn giúp cải thiện trích xuất đặc trưng
- Ba cấu hình linh hoạt phù hợp nhiều ứng dụng khác nhau
- Tập dữ liệu đa dạng giúp mô hình tổng quát hóa tốt
- Framework tính toán thưa thớt chỉ kích hoạt tham số cần thiết
📌 Deepseek-vl2 là bộ mô hình nguồn mở đột phá với 3 phiên bản từ 3b đến 27b tham số, đạt độ chính xác 92,3% trong ocr và tiết kiệm 30% tài nguyên. Kiến trúc moe cùng các cơ chế dynamic tiling và multi-head latent attention giúp mô hình xử lý hiệu quả cả ngôn ngữ và hình ảnh.
https://www.marktechpost.com/2024/12/15/deepseek-ai-open-sourced-deepseek-vl2-series-three-models-of-3b-16b-and-27b-parameters-with-mixture-of-experts-moe-architecture-redefining-vision-language-ai/
DeepSeek-AI Công Bố Open Source Bộ DeepSeek-VL2: Ba Mô Hình với 3 Tỉ, 16 Tỉ và 27 Tỉ Tham Số, Định Nghĩa Lại AI Kết Hợp Thị Giác và Ngôn Ngữ
Tác giả: Asif Razzaq - Ngày 15/12/2024
Việc tích hợp khả năng xử lý hình ảnh và ngôn ngữ trong AI đã tạo nên những đột phá trong các mô hình kết hợp thị giác và ngôn ngữ (Vision-Language Models - VLMs). Những mô hình này có khả năng xử lý và hiểu đồng thời dữ liệu hình ảnh và văn bản, mở ra nhiều ứng dụng như chú thích hình ảnh, trả lời câu hỏi dựa trên hình ảnh, nhận diện ký tự quang học (OCR), và phân tích nội dung đa phương tiện. Các VLMs đóng vai trò quan trọng trong việc phát triển hệ thống tự trị, cải thiện tương tác giữa con người và máy tính, và các công cụ xử lý tài liệu hiệu quả. Tuy nhiên, xử lý dữ liệu hình ảnh độ phân giải cao đồng thời với đầu vào văn bản phong phú vẫn là thách thức lớn trong lĩnh vực này.
Hạn chế của các mô hình hiện tại
Các nghiên cứu hiện có đã giải quyết một số hạn chế bằng cách sử dụng bộ mã hóa hình ảnh tĩnh, nhưng điều này khiến các mô hình thiếu tính thích ứng với dữ liệu độ phân giải cao và kích thước đầu vào thay đổi. Các mô hình ngôn ngữ được huấn luyện trước, khi kết hợp với bộ mã hóa hình ảnh, thường thiếu hiệu quả do không được tối ưu hóa cho các nhiệm vụ đa phương tiện. Một số mô hình sử dụng tính toán thưa (sparse computation) để quản lý độ phức tạp, nhưng thường không đạt độ chính xác cao trên nhiều tập dữ liệu khác nhau. Hơn nữa, dữ liệu huấn luyện của các mô hình này thường thiếu đa dạng và không đủ chi tiết theo từng nhiệm vụ, làm giảm hiệu suất trong các tác vụ chuyên biệt như phân tích biểu đồ hoặc tài liệu dày đặc.
DeepSeek-VL2: Bộ mô hình VLM tiên tiến
Các nhà nghiên cứu từ DeepSeek-AI đã giới thiệu DeepSeek-VL2, một thế hệ mô hình thị giác-ngôn ngữ dựa trên kiến trúc hỗn hợp chuyên gia (Mixture-of-Experts - MoE). Bộ mô hình này tích hợp các cải tiến tiên tiến, bao gồm:
- Dynamic Tiling: Giúp mã hóa hình ảnh độ phân giải cao mà không làm mất chi tiết quan trọng.
- Multi-head Latent Attention: Tăng cường hiệu quả xử lý văn bản với khối lượng lớn.
- DeepSeek-MoE Framework: Kích hoạt chỉ một phần nhỏ tham số của mô hình, tối ưu hóa hiệu quả và khả năng mở rộng.
Các cấu hình của DeepSeek-VL2
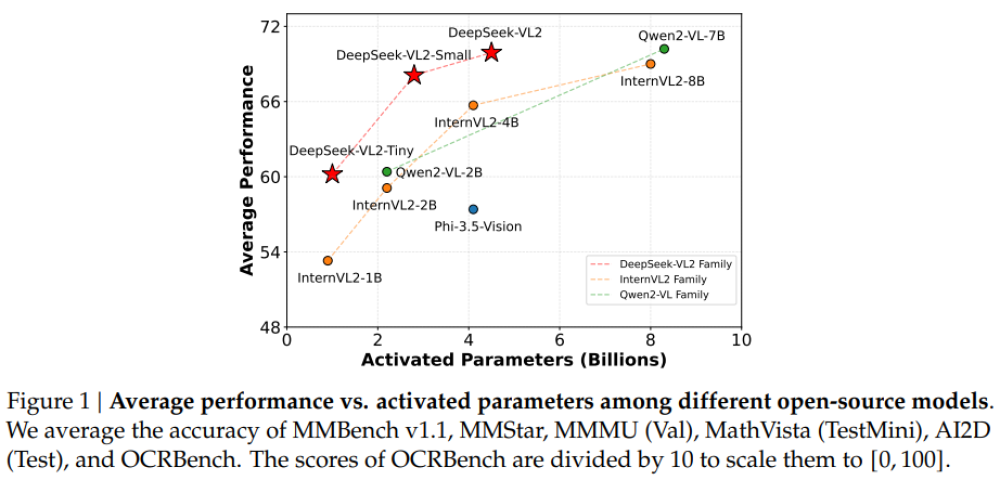
DeepSeek-VL2 được giới thiệu với ba cấu hình:
- DeepSeek-VL2-Tiny: 3,37 tỉ tham số (1 tỉ tham số được kích hoạt).
- DeepSeek-VL2-Small: 16,1 tỉ tham số (2,8 tỉ tham số được kích hoạt).
- DeepSeek-VL2: 27,5 tỉ tham số (4,5 tỉ tham số được kích hoạt).
Các cấu hình này đảm bảo khả năng thích ứng với nhu cầu ứng dụng và ngân sách tính toán khác nhau.
Hiệu suất vượt trội
DeepSeek-VL2 được thiết kế để tối ưu hóa hiệu năng trong khi giảm thiểu yêu cầu tính toán. Một số thành tựu của mô hình:
- Xử lý hình ảnh chi tiết: Dynamic Tiling cho phép phân tách hình ảnh độ phân giải cao thành các phần nhỏ, tối ưu hóa việc trích xuất đặc trưng.
- Hiệu quả vượt trội: Mô hình yêu cầu ít hơn 30% tài nguyên tính toán so với các mô hình tương đương mà vẫn duy trì độ chính xác tiên tiến.
- Độ chính xác cao: Đạt 92,3% chính xác trong tác vụ OCR, vượt xa các mô hình hiện tại. Trong bài toán định vị trực quan (visual grounding), mô hình cải thiện độ chính xác lên đến 15%.
- Khả năng tổng quát hóa tốt: DeepSeek-VL2 đạt điểm số dẫn đầu trong các tiêu chuẩn lý luận đa phương tiện.
Điểm nổi bật của DeepSeek-VL2
- Phân mảnh hình ảnh động: Cách tiếp cận này cải thiện việc trích xuất đặc trưng và giảm bớt gánh nặng tính toán, đặc biệt hiệu quả trong phân tích tài liệu dày đặc và bố cục phức tạp.
- Ba cấu hình đa dạng: Tiny, Small và Standard giúp đáp ứng nhiều nhu cầu, từ triển khai nhẹ đến các tác vụ đòi hỏi nhiều tài nguyên.
- Dữ liệu đa nhiệm toàn diện: Bộ dữ liệu huấn luyện bao quát các nhiệm vụ như OCR và định vị trực quan, nâng cao khả năng tổng quát hóa và hiệu suất theo từng nhiệm vụ.
- Tính toán thưa: Chỉ kích hoạt các tham số cần thiết, giảm đáng kể chi phí tính toán mà không làm giảm độ chính xác.
Kết luận
DeepSeek-VL2 là bộ mô hình kết hợp thị giác và ngôn ngữ mã nguồn mở với ba cấu hình (1,8 tỉ, 2,8 tỉ và 4,5 tỉ tham số kích hoạt). Bộ mô hình này mang lại khả năng mở rộng, hiệu quả tính toán cao và thích ứng với nhiệm vụ, vượt qua những hạn chế quan trọng của các mô hình hiện có. Các cơ chế đột phá như Dynamic Tiling và Multi-head Latent Attention cho phép xử lý hình ảnh chính xác và văn bản hiệu quả, đạt được kết quả tiên tiến trong các nhiệm vụ như OCR và định vị trực quan.
DeepSeek-VL2 thiết lập một tiêu chuẩn mới trong hiệu năng AI, mang lại những đột phá trong ứng dụng thực tiễn.



Thảo luận
Follow Us
Tin phổ biến
