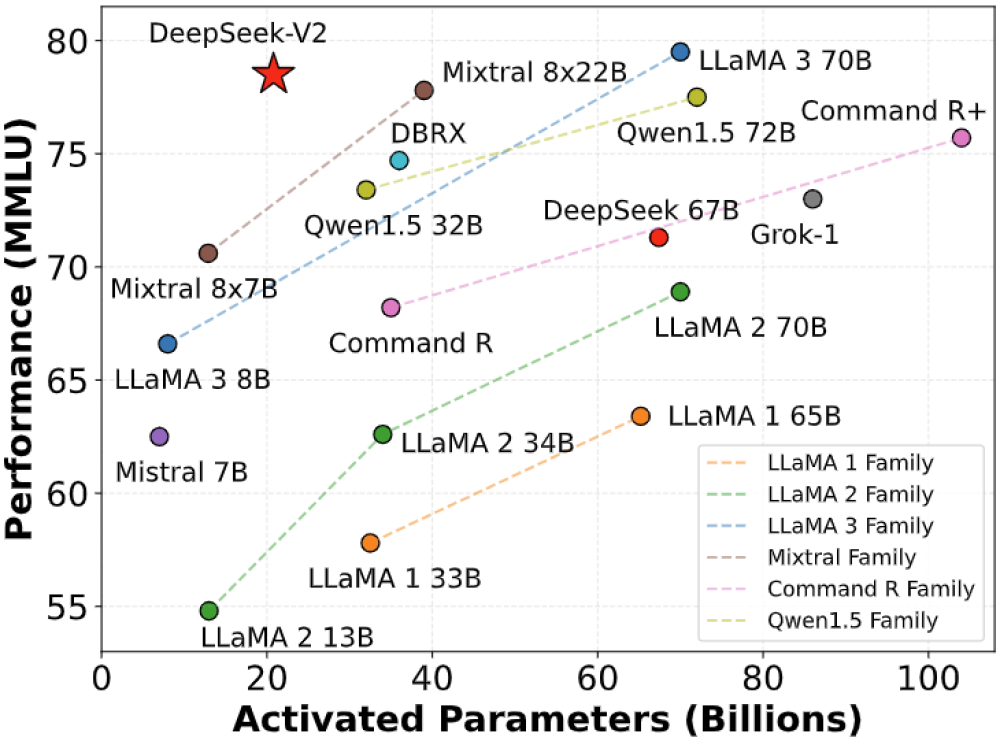
Deepseek v2 đánh bại mixtral 8x22b với hiệu suất vượt trội và tiết kiệm chi phí
- DeepSeek-V2 là mô hình ngôn ngữ Mixture-of-Experts (MoE) mạnh mẽ với 236B tham số tổng cộng, trong đó 21B được kích hoạt cho mỗi token.
- So với DeepSeek 67B, DeepSeek-V2 đạt hiệu suất mạnh mẽ hơn, tiết kiệm 42,5% chi phí đào tạo, giảm bộ nhớ cache KV 93,3% và tăng thông lượng tạo tối đa lên 5,76 lần.
- Có thể tải xuống mô hình DeepSeek-V2 và DeepSeek-V2-Chat(RL) trên 🤗 HuggingFace.
- Mã nguồn mở hiện có hiệu suất chậm hơn so với codebase nội bộ khi chạy trên GPU với Huggingface. DeepSeek cung cấp giải pháp vllm chuyên dụng tối ưu hóa hiệu suất để chạy mô hình hiệu quả.
- DeepSeek-V2 hoạt động tốt trên tất cả các độ dài cửa sổ ngữ cảnh lên đến 128K trong các bài kiểm tra Needle In A Haystack (NIAH).
- DeepSeek-V2 Chat(RL) đạt điểm cao nhất trên các bài kiểm tra MMLU, BBH, C-Eval, CMMLU so với các mô hình khác như LLaMA3 70B, Mixtral, ChatMixtral 8x22B.
- DeepSeek cung cấp API tương thích OpenAI tại DeepSeek Platform với hàng triệu token miễn phí và giá cả cạnh tranh.
- Để sử dụng DeepSeek-V2 ở định dạng BF16 để suy luận, cần 80GB*8 GPU. Có thể sử dụng trực tiếp Transformers của Huggingface để suy luận mô hình.
- Kho lưu trữ mã được cấp phép theo Giấy phép MIT. Việc sử dụng các mô hình DeepSeek-V2 Base/Chat tuân theo Giấy phép Mô hình. DeepSeek-V2 hỗ trợ sử dụng thương mại.
📌 DeepSeek-V2 là mô hình ngôn ngữ MoE mạnh mẽ với 236B tham số, tiết kiệm 42,5% chi phí đào tạo và tăng thông lượng tạo lên 5,76 lần so với DeepSeek 67B. Nó đạt điểm cao nhất trên nhiều bài kiểm tra và cung cấp API tương thích OpenAI. Mã nguồn mở được cấp phép MIT và hỗ trợ sử dụng thương mại.
Citations:
[1] https://github.com/deepseek-ai/DeepSeek-V2



Thảo luận
Follow Us
Tin phổ biến
