FedLLM-Bench: bộ dữ liệu đánh giá thực tế đầu tiên cho LLM học liên kết (federated learning)
- Các nhà nghiên cứu từ Đại học Giao thông Thượng Hải, Đại học Thanh Hoa và Phòng thí nghiệm AI Thượng Hải đề xuất FedLLM-Bench, bộ dữ liệu đánh giá thực tế đầu tiên cho mô hình ngôn ngữ lớn học liên kết (FedLLM).
- FedLLM-Bench cung cấp một môi trường thử nghiệm toàn diện với 4 tập dữ liệu: Fed-Aya (tinh chỉnh hướng dẫn đa ngôn ngữ), Fed-WildChat (tinh chỉnh hướng dẫn trò chuyện nhiều lượt), Fed-ChatbotIT (tinh chỉnh hướng dẫn trò chuyện một lượt) và Fed-ChatbotPA (điều chỉnh sở thích).
- Các tập dữ liệu được chia tự nhiên theo ID người dùng thực tế trên 38 đến 747 máy khách, nắm bắt các đặc tính liên kết thực tế như phân vùng dữ liệu trên các thiết bị.
- Các tập dữ liệu thể hiện sự đa dạng về ngôn ngữ, chất lượng dữ liệu, số lượng, độ dài chuỗi và sở thích người dùng, phản ánh sự phức tạp của thế giới thực.
- FedLLM-Bench tích hợp các tập dữ liệu này với 8 phương pháp cơ sở và 6 chỉ số đánh giá để tạo điều kiện so sánh phương pháp và khám phá các hướng nghiên cứu mới.
- Phân tích tập dữ liệu sâu rộng cho thấy sự đa dạng giữa/trong tập dữ liệu ở các khía cạnh như độ dài, hướng dẫn, chất lượng, embedding và số lượng.
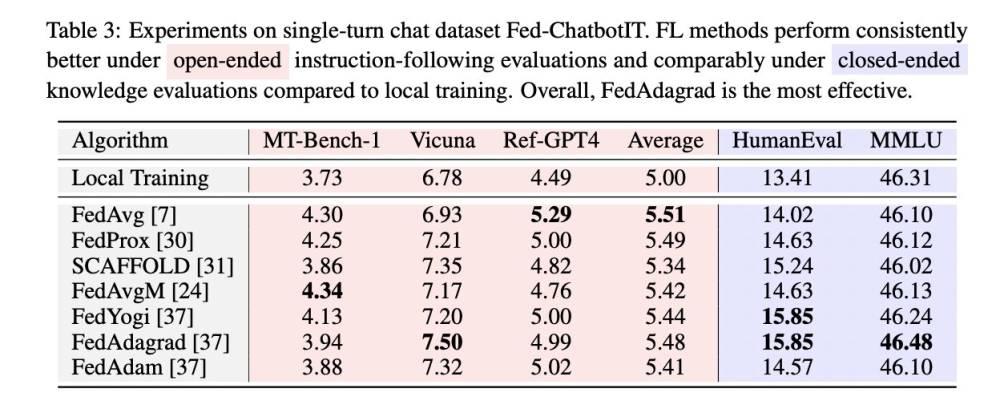
- Đánh giá sử dụng 6 chỉ số - 4 chỉ số mở (MT-Bench, Vicuna bench, AdvBench, Ref-GPT4) và 2 chỉ số đóng (MMLU, HumanEval).
- Trên tập dữ liệu đa ngôn ngữ Fed-Aya, hầu hết các phương pháp liên kết vượt trội hơn đào tạo cục bộ trung bình, mặc dù không có phương pháp nào chiếm ưu thế trên tất cả các ngôn ngữ.
- Đối với Fed-ChatbotIT, tất cả các phương pháp liên kết đều nâng cao khả năng tuân theo hướng dẫn so với đào tạo cục bộ mà không ảnh hưởng đến khả năng chung, với FedAdagrad hoạt động tốt nhất tổng thể.
- Trên Fed-WildChat cho các cuộc trò chuyện một và nhiều lượt, các phương pháp liên kết liên tục vượt trội hơn đào tạo cục bộ, với FedAvg được chứng minh là hiệu quả nhất cho nhiều lượt.
- Đối với điều chỉnh sở thích Fed-ChatbotPA, đào tạo liên kết cải thiện khả năng tuân theo hướng dẫn và an toàn so với cục bộ, với FedAvgM, FedProx, SCAFFOLD và FedAvg là những người thực hiện hàng đầu.
📌 FedLLM-Bench là bộ dữ liệu đánh giá thực tế đầu tiên cho FedLLM với 4 tập dữ liệu đa dạng trên 38-747 máy khách, thể hiện các đặc tính thế giới thực. Tích hợp với 8 phương pháp đào tạo và 6 chỉ số đánh giá, nó cung cấp một môi trường thử nghiệm toàn diện, thực tế, cho phép so sánh công bằng và thúc đẩy tiến bộ trong lĩnh vực FedLLM đang phát triển.
https://www.marktechpost.com/2024/06/11/benchmarking-federated-learning-for-large-language-models-with-fedllm-bench/



Thảo luận
Follow Us
Tin phổ biến
