GenQA: tự động tạo tập dữ liệu hướng dẫn khổng lồ để nâng cấp AI
- Các nhà nghiên cứu từ Đại học Maryland giới thiệu GenQA, phương pháp tạo tập dữ liệu hướng dẫn tự động quy mô lớn để tinh chỉnh mô hình AI và tăng cường tính đa dạng.
- Việc tạo các tập dữ liệu lớn, đa dạng để tinh chỉnh mô hình ngôn ngữ rất phức tạp, tốn kém và đòi hỏi nhiều sự can thiệp của con người. Điều này tạo ra khoảng cách giữa nghiên cứu học thuật (sử dụng tập dữ liệu nhỏ) và ứng dụng công nghiệp (sử dụng tập dữ liệu lớn).
- Các phương pháp hiện tại như sử dụng mô hình ngôn ngữ lớn (LLM) để sửa đổi và tăng cường nội dung do con người viết vẫn còn hạn chế về khả năng mở rộng và tính đa dạng.
- GenQA sử dụng một lời nhắc duy nhất, được thiết kế tốt để tự động tạo ra hàng triệu ví dụ hướng dẫn đa dạng, giảm thiểu sự can thiệp của con người.
- Công nghệ cốt lõi của GenQA là sử dụng các lời nhắc tạo sinh để tăng cường tính ngẫu nhiên và đa dạng của đầu ra do LLM tạo ra. Một siêu lời nhắc duy nhất có thể trích xuất hàng triệu câu hỏi đa dạng.
- Trong một thử nghiệm, GenQA đã tạo ra hơn 11 triệu câu hỏi trên 9 lĩnh vực khác nhau như học thuật, toán học và đối thoại.
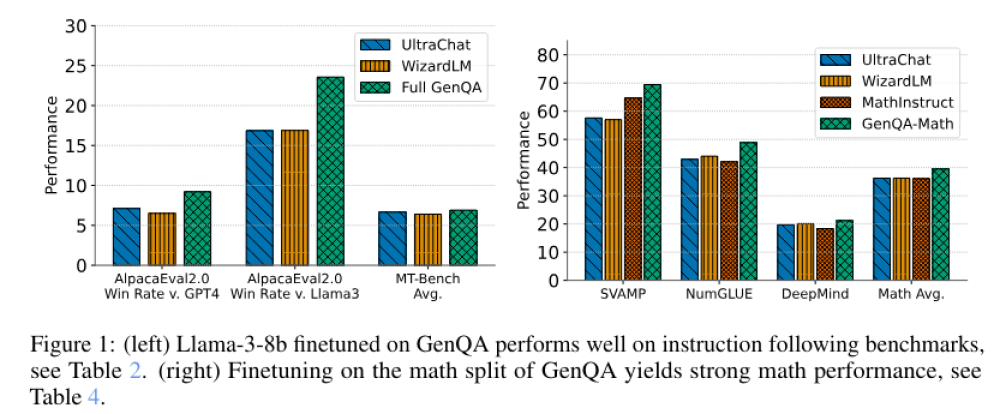
- Khi tinh chỉnh mô hình Llama-3 8B với tập dữ liệu GenQA, hiệu suất của mô hình trên các tiêu chuẩn tri thức và hội thoại đáp ứng hoặc vượt trội hơn so với các tập dữ liệu như WizardLM và UltraChat. Cụ thể, trên MT-Bench, GenQA đạt điểm trung bình 7.55.
- Phân tích chi tiết cho thấy các lời nhắc tạo sinh của GenQA dẫn đến sự đa dạng cao trong các câu hỏi và câu trả lời được tạo ra. Điểm tương đồng của các láng giềng gần nhất thấp hơn đáng kể so với lời nhắc tĩnh.
📌 GenQA tự động hóa quá trình tạo tập dữ liệu hướng dẫn quy mô lớn, đa dạng với sự can thiệp tối thiểu của con người, giảm chi phí và thu hẹp khoảng cách giữa nghiên cứu học thuật và ứng dụng công nghiệp. Thành công của GenQA trong việc tinh chỉnh mô hình Llama-3 8B cho thấy tiềm năng cải thiện đáng kể nghiên cứu và ứng dụng AI, với hiệu suất vượt trội trên các tiêu chuẩn tri thức, lập luận toán học và hội thoại.
https://www.marktechpost.com/2024/06/23/researchers-from-the-university-of-maryland-introduce-genqa-instruction-dataset-automating-large-scale-instruction-dataset-generation-for-ai-model-finetuning-and-diversity-enhancement/



Thảo luận
Follow Us
Tin phổ biến
