Google: CodecLM điều chỉnh mô hình ngôn ngữ lớn với dữ liệu tổng hợp được điều chỉnh
- CodecLM là một framework tổng hợp dữ liệu có hệ thống để điều chỉnh các mô hình ngôn ngữ lớn (LLM) cho các tác vụ cụ thể.
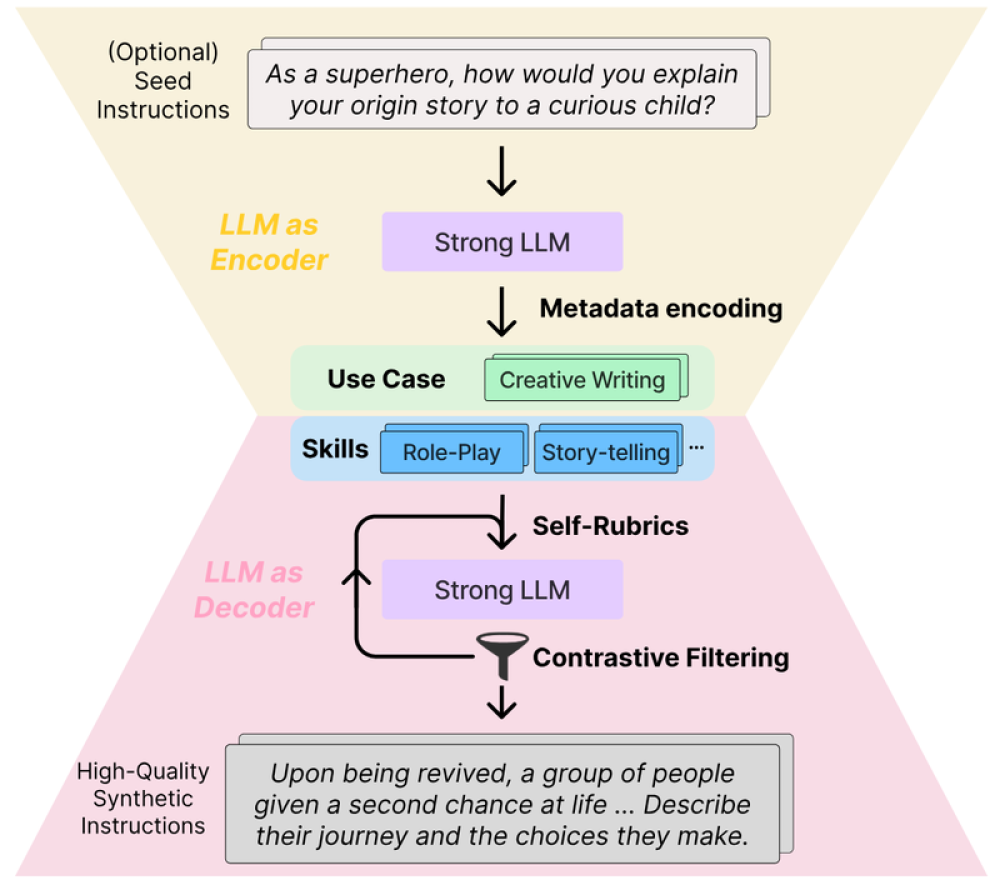
- Nó sử dụng một LLM mạnh để mã hóa các hướng dẫn gốc thành siêu dữ liệu, sau đó giải mã thành các hướng dẫn tổng hợp được điều chỉnh thông qua 2 chiến lược bổ sung: Self-Rubrics và Contrastive Filtering.
- Self-Rubrics tạo ra các tiêu chí và hành động để làm cho hướng dẫn tổng hợp trở nên thách thức hơn. Contrastive Filtering chọn ra các hướng dẫn mà LLM mục tiêu không thể đáp ứng tốt.
- Các thử nghiệm trên các bộ dữ liệu benchmark cho thấy CodecLM vượt trội hơn các phương pháp cơ sở, đạt tỷ lệ phục hồi năng lực (CRR) cao hơn khi so sánh LLM mục tiêu được điều chỉnh với LLM mạnh.
- CodecLM cung cấp giải pháp hiệu quả để điều chỉnh LLM cho các mục đích sử dụng tùy chỉnh mà không cần gán nhãn thủ công.
📌 CodecLM tạo ra dữ liệu tổng hợp được điều chỉnh phù hợp để điều chỉnh LLM cho các tác vụ cụ thể thông qua việc mã hóa hướng dẫn thành siêu dữ liệu, sau đó giải mã thành các hướng dẫn tổng hợp chất lượng cao bằng Self-Rubrics và Contrastive Filtering. Nó đạt hiệu suất vượt trội trên các bộ dữ liệu benchmark, mở ra hướng nghiên cứu triển vọng để điều chỉnh LLM theo mục đích sử dụng.
Citations:
https://research.google/blog/codeclm-aligning-language-models-with-tailored-synthetic-data/



Thảo luận
Follow Us
Tin phổ biến
