Google Deepmind ra mắt Score: phương pháp AI mới giúp LLM tự sửa lỗi chính xác hơn trong toán và lập trình
• Google DeepMind đã giới thiệu phương pháp mới có tên Self-Correction via Reinforcement Learning (SCoRe) nhằm cải thiện khả năng tự điều chỉnh của các mô hình ngôn ngữ lớn (LLM) trong các tác vụ phức tạp như giải toán và lập trình.
• Các LLM hiện tại thường gặp khó khăn trong việc tự sửa lỗi một cách nhất quán, đặc biệt là trong các bài toán đòi hỏi lập luận nhiều bước. Điều này dẫn đến việc tích lũy sai số và kết quả không chính xác.
• Các phương pháp hiện có như fine-tuning có giám sát hoặc sử dụng nhiều mô hình thường gặp hạn chế về hiệu quả và chi phí tính toán cao.
• SCoRe sử dụng phương pháp học tăng cường đa bước để dạy LLM tự cải thiện câu trả lời mà không cần giám sát bên ngoài hay mô hình xác minh riêng biệt.
• Phương pháp này gồm hai giai đoạn chính: khởi tạo ban đầu để phát triển chiến lược điều chỉnh, và học tăng cường để nâng cao khả năng tự sửa lỗi trong môi trường đa bước.
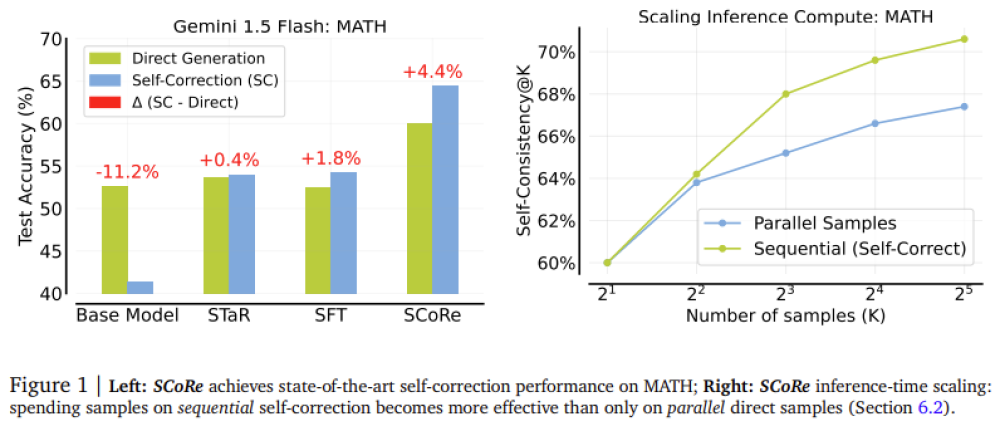
• Khi áp dụng cho các mô hình Gemini 1.0 Pro và 1.5 Flash, SCoRe đã cải thiện độ chính xác trong tự điều chỉnh lên 15,6% đối với các tác vụ lập luận toán học từ bộ dữ liệu MATH và 9,1% đối với các tác vụ lập trình trong bộ dữ liệu HumanEval.
• Độ chính xác của mô hình tăng lên 60,0% cho lần thử đầu tiên và 64,4% cho lần thử thứ hai, cho thấy khả năng sửa đổi hiệu quả câu trả lời ban đầu.
• SCoRe cũng giảm thiểu việc thay đổi các câu trả lời đúng thành sai trong lần thử thứ hai, một vấn đề phổ biến trong các phương pháp tự điều chỉnh khác.
• Trong các tác vụ lập luận toán học, mô hình cải thiện tỷ lệ điều chỉnh từ 4,6% lên 5,8%, đồng thời giảm thiểu việc thay đổi từ sai sang đúng.
• Đối với các tác vụ lập trình, SCoRe đạt được mức cải thiện 12,2% trong tự điều chỉnh trên bộ đánh giá HumanEval, chứng tỏ khả năng áp dụng rộng rãi cho nhiều lĩnh vực khác nhau.
📌 Google DeepMind đã tạo ra bước đột phá với phương pháp SCoRe, giúp LLM tự sửa lỗi hiệu quả hơn 15,6% trong toán học và 9,1% trong lập trình. Phương pháp này sử dụng học tăng cường trên dữ liệu tự tạo, khắc phục hạn chế của các phương pháp trước đây và mở ra tiềm năng ứng dụng rộng rãi cho AI tạo sinh.
https://www.marktechpost.com/2024/09/21/google-deepmind-introduced-self-correction-via-reinforcement-learning-score-a-new-ai-method-enhancing-large-language-models-accuracy-in-complex-mathematical-and-coding-tasks/



Thảo luận
Follow Us
Tin phổ biến
