Gretel AI phát hành bộ dữ liệu tài chính tổng hợp đa ngôn ngữ mới trên HuggingFace 🤗 cho các nhà phát triển AI
- Gretel AI đã phát hành bộ dữ liệu tài chính tổng hợp đa ngôn ngữ mới trên nền tảng HuggingFace 🤗 để hỗ trợ các nhà phát triển AI trong việc phát hiện thông tin nhận dạng cá nhân (PII).
- Bộ dữ liệu bao gồm 55.940 bản ghi, trong đó 50.776 mẫu dùng để huấn luyện và 5.164 mẫu dùng để kiểm tra.
- Dữ liệu đa dạng với 100 định dạng tài liệu tài chính khác nhau, mỗi loại có 20 tiểu loại cụ thể.
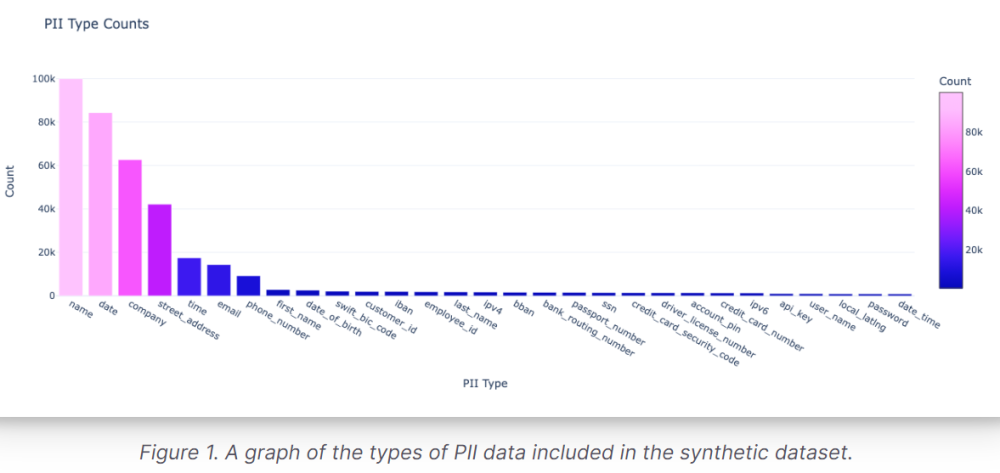
- Chứa 29 loại PII khác nhau, phù hợp với trình tạo thư viện Python Faker để dễ dàng phát hiện và thay thế.
- Độ dài trung bình của tài liệu là 1.357 ký tự.
- Hỗ trợ đa ngôn ngữ: Tiếng Anh, Tây Ban Nha, Thụy Điển, Đức, Ý, Hà Lan và Pháp.
- Sử dụng kỹ thuật "LLM-as-a-Judge" với mô hình ngôn ngữ Mistral-7B để đảm bảo chất lượng dữ liệu.
- Bộ dữ liệu có thể được sử dụng để huấn luyện các mô hình NER, kiểm tra hệ thống quét PII, đánh giá hệ thống khử nhận dạng và phát triển các giải pháp bảo mật dữ liệu cho ngành tài chính.
📌 Bộ dữ liệu tài chính tổng hợp đa ngôn ngữ mới của Gretel AI là một nguồn tài nguyên quý giá cho các nhà phát triển và nghiên cứu xây dựng các giải pháp phát hiện PII mạnh mẽ. Với 55.940 bản ghi đa dạng, hỗ trợ 7 ngôn ngữ và đảm bảo chất lượng cao, bộ dữ liệu này sẽ thúc đẩy sự phát triển của các hệ thống AI chính xác, công bằng và đáng tin cậy hơn trong lĩnh vực tài chính.
https://www.marktechpost.com/2024/06/13/gretel-ai-releases-a-new-multilingual-synthetic-financial-dataset-on-huggingface-%F0%9F%A4%97-for-ai-developers-tackling-personally-identifiable-information-pii-detection/



Thảo luận
Follow Us
Tin phổ biến
