Groq ra mắt mô hình đa phương thức LLaVA v1.5 7B trên GroqCloud, nhanh hơn 4 lần so với GPT-4o
• Groq vừa giới thiệu mô hình thị giác LLaVA v1.5 7B trên Developer Console của họ, biến GroqCloud thành nền tảng đa phương thức hỗ trợ xử lý hình ảnh, âm thanh và văn bản.
• LLaVA (Large Language and Vision Assistant) kết hợp khả năng xử lý ngôn ngữ và thị giác, dựa trên mô hình CLIP của OpenAI và Llama 2 7B của Meta.
• Mô hình này sử dụng kỹ thuật huấn luyện hướng dẫn thị giác để nâng cao khả năng thực hiện hướng dẫn dựa trên hình ảnh và suy luận thị giác.
• LLaVA v1.5 7B xuất sắc trong các tác vụ như trả lời câu hỏi về hình ảnh, tạo chú thích, nhận dạng ký tự quang học và đối thoại đa phương thức.
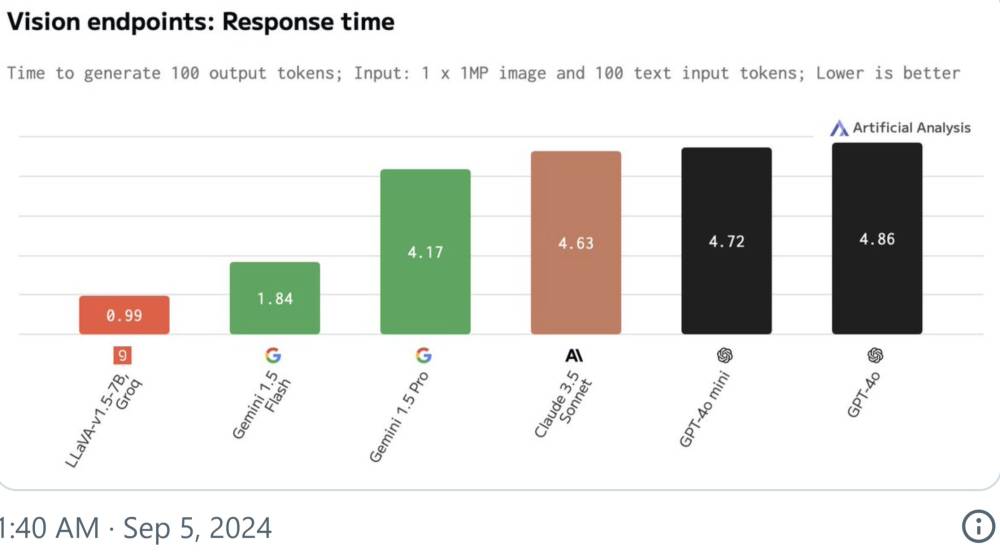
• Theo Artificial Analysis, thời gian phản hồi của LLaVA v1.5 7B nhanh hơn 4 lần so với GPT-4o của OpenAI.
• Mô hình mới mở ra nhiều ứng dụng thực tế: theo dõi hàng tồn kho cho bán lẻ, cải thiện khả năng tiếp cận trên mạng xã hội bằng mô tả hình ảnh, chatbot dịch vụ khách hàng xử lý tương tác văn bản và hình ảnh.
• LLaVA v1.5 7B giúp tự động hóa các tác vụ trong sản xuất, tài chính, bán lẻ và giáo dục, nâng cao hiệu quả quy trình.
• Các nhà phát triển và doanh nghiệp có thể sử dụng LLaVA v1.5 7B ở chế độ Preview trên GroqCloud.
• Groq gần đây đã hợp tác với Meta, cung cấp các mô hình Llama 3.1 mới nhất (405B Instruct, 70B Instruct và 8B Instruct) cho cộng đồng với tốc độ của Groq.
• Andrej Karpathy, cựu nghiên cứu viên OpenAI, đã khen ngợi tốc độ suy luận của Groq, cho rằng nó mang lại trải nghiệm như AGI khi người dùng có thể nói chuyện với máy tính và nhận phản hồi tức thì.
• Groq được thành lập năm 2016 bởi Ross, khác biệt với các công ty khác bằng cách sử dụng phần cứng LPU độc quyền thay vì GPU.
📌 Groq ra mắt mô hình đa phương thức LLaVA v1.5 7B trên GroqCloud, nhanh hơn 4 lần so với GPT-4o. Mô hình kết hợp xử lý ngôn ngữ và thị giác, mở ra ứng dụng trong nhiều lĩnh vực như bán lẻ, mạng xã hội và dịch vụ khách hàng. Groq cũng hợp tác với Meta cung cấp các mô hình Llama 3.1 mới nhất.
https://analyticsindiamag.com/ai-news-updates/groq-unveils-llava-v1-5-7b-faster-than-openai-gpt-4o/



Thảo luận
Follow Us
Tin phổ biến
