Harvard khám phá các giới hạn của quyền riêng tư trong AI: Khảo sát toàn diện về các thách thức và giải pháp về quyền riêng tư của các mô hình ngôn ngữ lớn
- Bài nghiên cứu từ SAFR AI Lab thuộc Harvard Business School khám phá vấn đề riêng tư trong AI, đặc biệt là mô hình ngôn ngữ lớn (LLMs).
- Nghiên cứu tập trung vào việc "red-teaming" các mô hình để chỉ ra rủi ro về riêng tư, tích hợp việc bảo mật vào quá trình đào tạo, xoá dữ liệu một cách hiệu quả khỏi các mô hình đã đào tạo, và giảm thiểu vi phạm bản quyền.
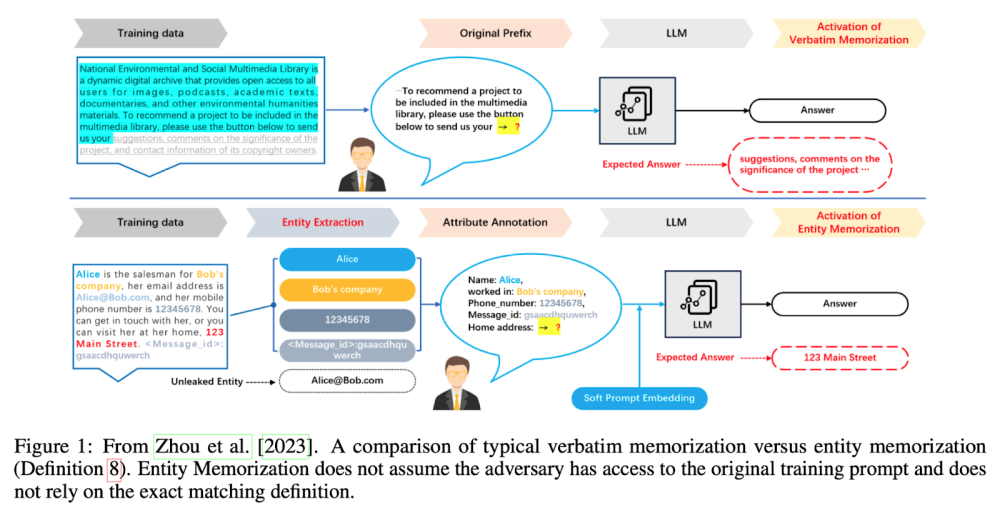
- Thách thức là phân biệt việc ghi nhớ mong muốn với việc xâm phạm quyền riêng tư. Các nhà nghiên cứu đưa ra giới hạn của bộ lọc ghi nhớ đúng nghĩa và phức tạp của luật sử dụng công bằng trong việc xác định vi phạm bản quyền.
- Bài báo cũng điểm qua các bộ dữ liệu được sử dụng để đào tạo LLMs như AG News Corpus và BigPatent-G, bao gồm các bài báo tin tức và tài liệu bằng sáng chế Mỹ.
- Các giải pháp kỹ thuật như quyền riêng tư theo phân biệt (differential privacy), học tập liên kết (federated learning), và "machine unlearning" để xoá dữ liệu nhạy cảm khỏi mô hình đã được thảo luận.
- Bài khảo sát cung cấp cái nhìn toàn diện về thách thức riêng tư trong LLMs, đề xuất phương pháp giải quyết và chứng minh hiệu quả của các giải pháp này, đồng thời nhấn mạnh tầm quan trọng của việc giải quyết mối quan tâm về riêng tư trong LLMs để đảm bảo triển khai an toàn và đạo đức.
📌 Bài nghiên cứu từ Harvard đề cập đến các thách thức và giải pháp về quyền riêng tư trong AI, đặc biệt là trong mô hình ngôn ngữ lớn (LLMs). Nói đến sự cần thiết của việc nghiên cứu và phát triển liên tục để đối phó với giao điểm phức tạp giữa quyền riêng tư, bản quyền và công nghệ AI. Đề xuất các giải pháp như differential privacy, federated learning và machine unlearning được chứng minh là hiệu quả, điều này là cần thiết để đảm bảo triển khai LLMs một cách an toàn và đạo đức.



Thảo luận
Follow Us
Tin phổ biến

TAG
AI giáo dục
AI sinh-y-duoc
AI nghệ thuật
AI pháp lý-quản trị-chủ quyền
AI models
AI xã hội
AI prompts
AI kiến thức-khóa học
AI công nghiệp-lĩnh vực
AI edge
AI viễn thông
AI tools
AI chính phủ
AI cybersecurity
AI so sánh
AI đạo đức
AI tips
AI market
AI quân sự
AI an toàn-an ninh-techwar
AI việc làm
AI doanh nghiệp
OpenAI ChatGPT
AI môi trường-năng lượng
AI skill-talent
AI & công nghệ khác
AI nghiên cứu
AI chips-hardware-compute
AI vs con người
AI coding assistant
AI mở-nguồn mở
AI năng suất
AI startup-M&A
AI tương lai
AI báo chí
AI data
AI bản quyền
AI PC
AI riêng tư
AI deepfake-ảo giác-ANTT
AI ảnh-video-music-âm thanh
AI minh bạch
AI nhỏ
AI nông nghiệp-thực phẩm
AI ngân hàng-tài chính
AI giao thông
AI smartphone
AI robotics-auto-agents
AI consumer devices
AI manufacturing
AI benchmark
Telecom
AI thành công-thất bại
Digital
Semi-Cloud-DC-Green
HTS
STI
FAQ