hplt datasets v1.2: dữ liệu văn bản đơn ngữ khổng lồ cho 75 ngôn ngữ
- HPLT Datasets v1.2 cung cấp dữ liệu văn bản đơn ngữ cho 75 ngôn ngữ, bao gồm các phiên bản thô, loại bỏ trùng lặp và làm sạch.
- Tổng cộng có 22 TB dữ liệu thô, 11 TB dữ liệu loại bỏ trùng lặp và 8.4 TB dữ liệu sạch, được cung cấp ở định dạng JSONL nén bằng zstd.
- Dữ liệu được chia thành nhiều phần nhỏ, mỗi phần vài GB. Số lượng phần cho mỗi ngôn ngữ phụ thuộc vào kích thước của kho ngữ liệu cụ thể.
- Mỗi dòng trong tệp JSONL là một giá trị JSON hợp lệ và một tài liệu đầy đủ với siêu dữ liệu.
- Trang web cung cấp các lệnh wget để tải xuống dữ liệu cho từng ngôn ngữ hoặc toàn bộ dữ liệu từ các phiên bản thô, loại bỏ trùng lặp hoặc làm sạch.
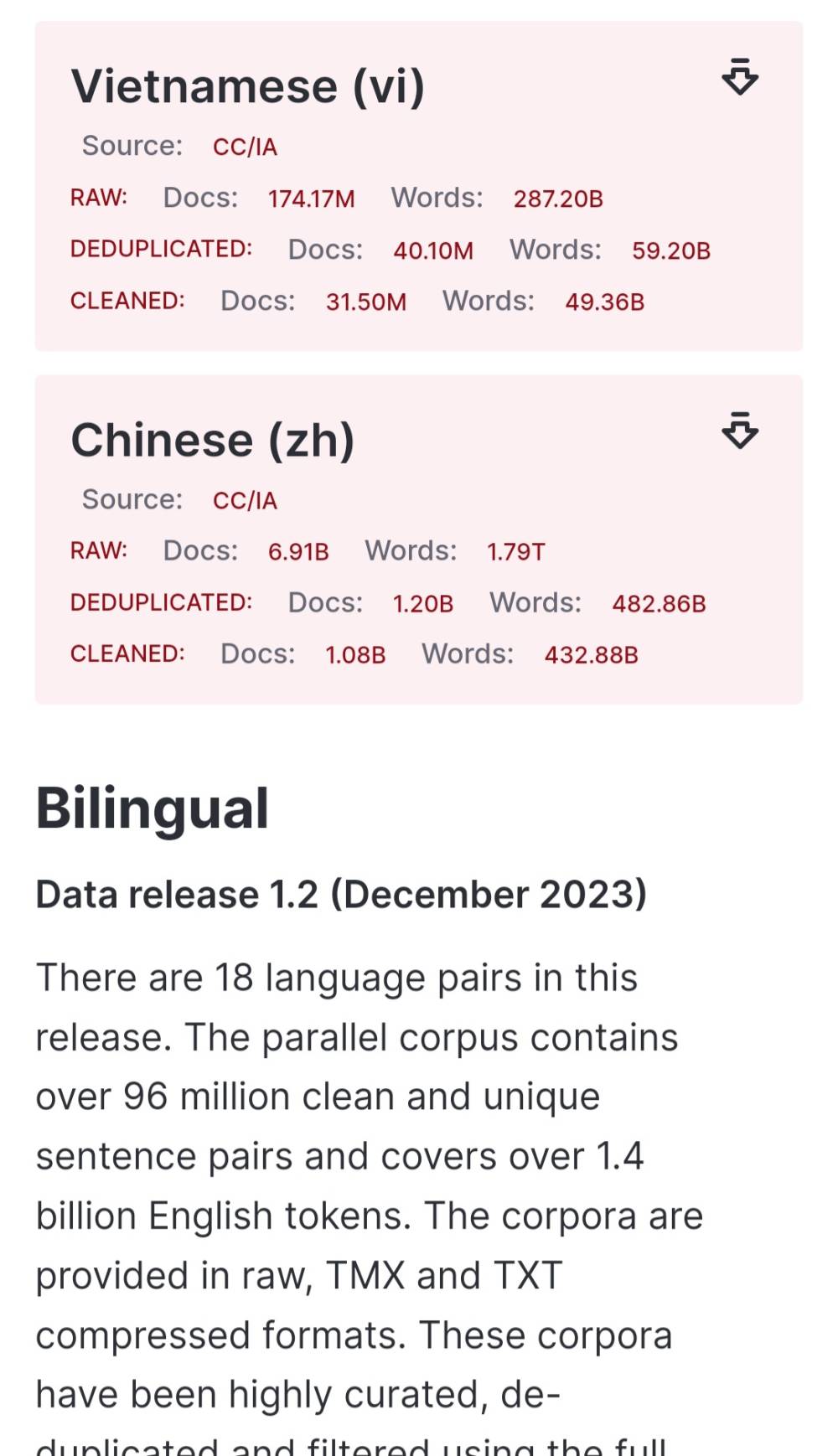
- Một số ví dụ về quy mô dữ liệu: Tiếng Anh có 1.08 tỷ tài liệu và 432.88 tỷ từ trong phiên bản sạch. Tiếng Ả Rập có 26.80 triệu tài liệu và 28.41 tỷ từ trong phiên bản sạch.
📌 HPLT Datasets v1.2 là một nguồn tài nguyên dữ liệu văn bản đơn ngữ khổng lồ cho 75 ngôn ngữ, với tổng cộng 22 TB dữ liệu thô, 11 TB dữ liệu loại bỏ trùng lặp và 8.4 TB dữ liệu sạch ở định dạng JSONL. Bộ dữ liệu này hứa hẹn thúc đẩy các công nghệ ngôn ngữ hiệu suất cao.
Citations:
[1] HPLT Datasets v1.2 https://hplt-project.org/datasets/v1.2



Thảo luận
Follow Us
Tin phổ biến
