Hugging Face ra mắt FineMath - kho dữ liệu 50 tỷ token định hình lại cách máy tính học toán
- Hugging Face vừa công bố FineMath - bộ dữ liệu nguồn mở toàn diện nhằm cải thiện khả năng tiếp cận nội dung toán học chất lượng cao cho người học và nhà nghiên cứu
- FineMath gồm 2 phiên bản chính:
+ FineMath-3+: 34 tỷ token từ 21,4 triệu tài liệu, định dạng Markdown và LaTeX
+ FineMath-4+: 9,6 tỷ token từ 6,7 triệu tài liệu, tập trung vào nội dung chất lượng cao với giải thích chi tiết
- Quy trình tạo FineMath gồm nhiều giai đoạn:
+ Trích xuất dữ liệu thô từ CommonCrawl sử dụng công cụ Resiliparse
+ Đánh giá bằng bộ phân loại tùy chỉnh dựa trên Llama-3.1-70B-Instruct
+ Loại bỏ trùng lặp và đánh giá đa ngôn ngữ
+ Khắc phục vấn đề lọc ký hiệu LaTeX không chính xác
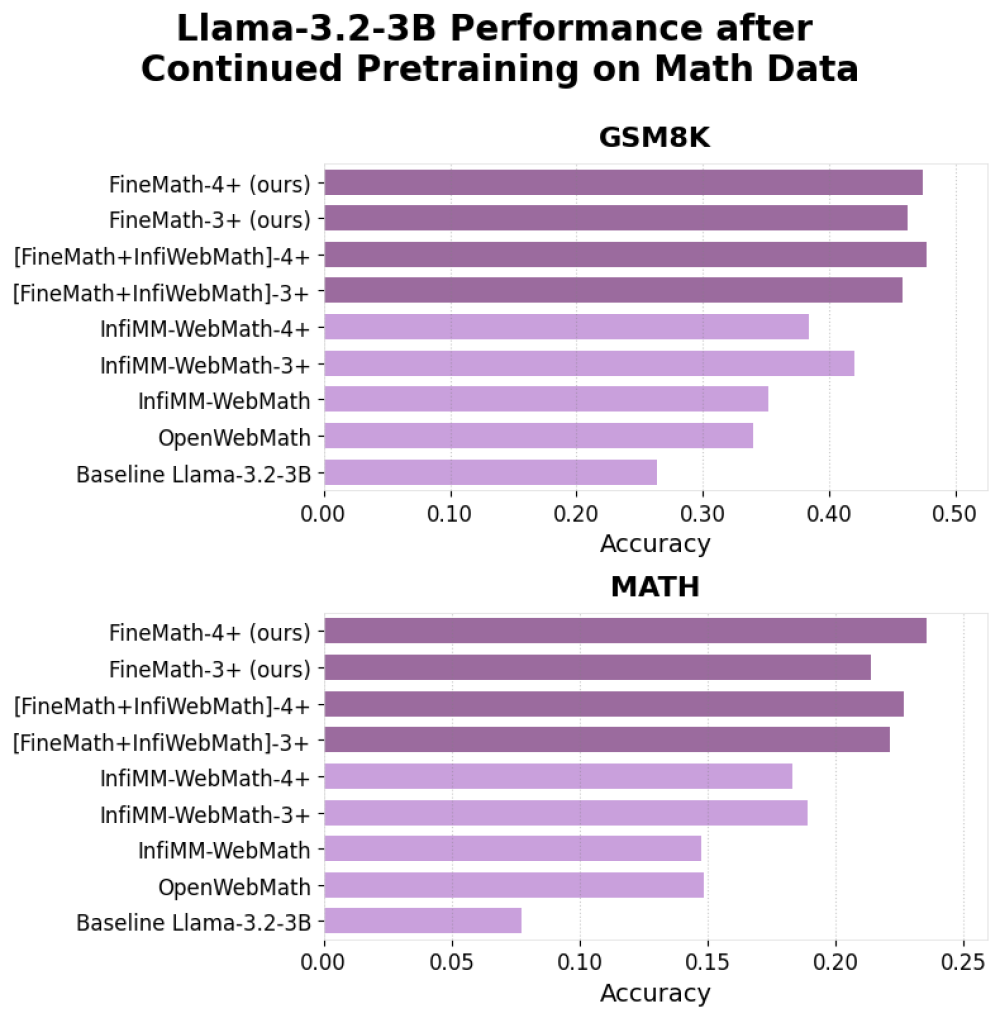
- Hiệu suất vượt trội trên các benchmark:
+ Cải thiện đáng kể về khả năng lập luận và độ chính xác toán học
+ Kết hợp với InfiMM-WebMath tạo bộ dữ liệu khoảng 50 tỷ token
+ Tích hợp dễ dàng vào các pipeline học máy
- Kế hoạch phát triển trong tương lai:
+ Mở rộng hỗ trợ ngôn ngữ ngoài tiếng Anh
+ Cải thiện trích xuất và bảo toàn ký hiệu toán học
+ Phát triển các chỉ số đánh giá chất lượng nâng cao
+ Tạo các tập con chuyên biệt cho từng cấp độ giáo dục
📌 Hugging Face đã tạo bước đột phá với FineMath - bộ dữ liệu nguồn mở 50 tỷ token cho AI học toán. Dataset này bao gồm 34 tỷ token từ FineMath-3+ và 9,6 tỷ token từ FineMath-4+, hỗ trợ cải thiện hiệu suất trên các benchmark như GSM8k và MATH.
https://www.marktechpost.com/2024/12/20/hugging-face-releases-finemath-the-ultimate-open-math-pre-training-dataset-with-50b-tokens/



Thảo luận
Follow Us
Tin phổ biến
