InternLM2.5-7B-Chat: LLM nguồn mở suy luận, xử lý ngữ cảnh dài và sử dụng công cụ vượt trội.
• InternLM vừa công bố mô hình ngôn ngữ lớn nguồn mở mới nhất InternLM2.5-7B-Chat, có sẵn ở định dạng GGUF và tương thích với llama.cpp.
• Mô hình có thể được sử dụng cục bộ và trên đám mây trên nhiều nền tảng phần cứng khác nhau. Định dạng GGUF cung cấp các phiên bản lượng tử hóa half-precision và low-bit, bao gồm q5_0, q5_k_m, q6_k và q8_0.
• InternLM2.5 dựa trên phiên bản tiền nhiệm, cung cấp mô hình cơ sở 7 tỷ tham số và mô hình chat được điều chỉnh cho các tình huống thực tế.
• Mô hình này có khả năng suy luận tiên tiến, đặc biệt là suy luận toán học, vượt trội so với các đối thủ như Llama3 và Gemma2-9B.
• InternLM2.5-7B-Chat có cửa sổ ngữ cảnh ấn tượng 1M, thể hiện hiệu suất gần như hoàn hảo trong các tác vụ ngữ cảnh dài như được đánh giá bởi LongBench.
• Khả năng xử lý ngữ cảnh dài giúp mô hình đặc biệt hiệu quả trong việc truy xuất thông tin từ các tài liệu dài. Khả năng này được tăng cường khi kết hợp với LMDeploy, một bộ công cụ để nén, triển khai và phục vụ các mô hình ngôn ngữ lớn.
• Phiên bản InternLM2.5-7B-Chat-1M được thiết kế cho suy luận ngữ cảnh dài 1M, nhưng yêu cầu tài nguyên tính toán đáng kể như 4 GPU A100-80G để hoạt động hiệu quả.
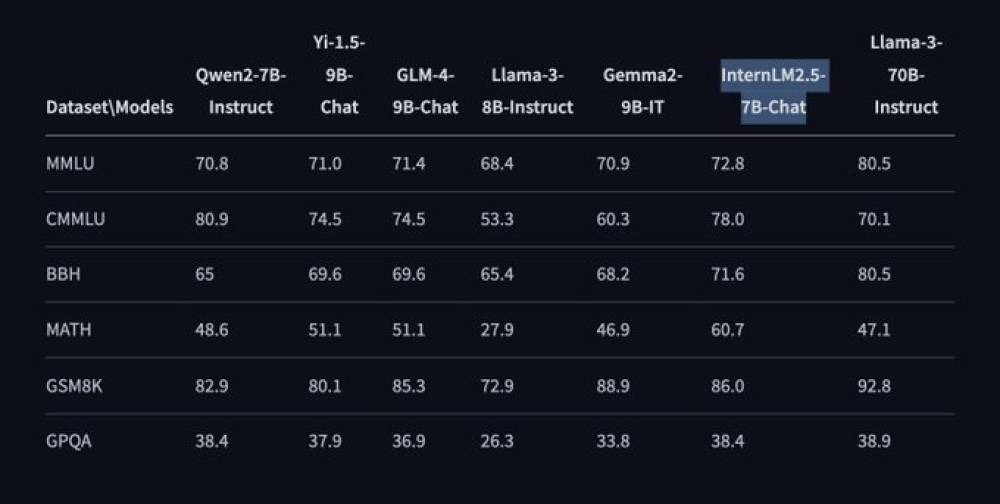
• Đánh giá hiệu suất sử dụng công cụ OpenCompass cho thấy khả năng vượt trội của mô hình trong nhiều lĩnh vực: năng lực chuyên ngành, ngôn ngữ, kiến thức, suy luận và hiểu biết.
• Trong các điểm chuẩn như MMLU, CMMLU, BBH, MATH, GSM8K và GPQA, InternLM2.5-7B-Chat liên tục mang lại hiệu suất vượt trội so với các đối thủ cùng cấp. Ví dụ, điểm chuẩn MMLU đạt 72,8, vượt qua các mô hình như Llama-3-8B-Instruct và Gemma2-9B-IT.
• InternLM2.5-7B-Chat cũng xuất sắc trong việc sử dụng công cụ, hỗ trợ thu thập thông tin từ hơn 100 trang web. Phiên bản sắp tới của Lagent sẽ tăng cường chức năng này, cải thiện khả năng tuân theo hướng dẫn, lựa chọn công cụ và phản ánh của mô hình.
• Bản phát hành của mô hình bao gồm hướng dẫn cài đặt toàn diện, hướng dẫn tải xuống mô hình và các ví dụ về suy luận và triển khai dịch vụ mô hình.
• Người dùng có thể thực hiện suy luận ngoại tuyến theo lô với mô hình lượng tử hóa bằng lmdeploy, một framework hỗ trợ lượng tử hóa INT4 weight-only và triển khai (W4A16). Thiết lập này cung cấp suy luận nhanh hơn tới 2,4 lần so với FP16 trên các GPU NVIDIA tương thích.
• Kiến trúc của InternLM2.5 giữ lại các tính năng mạnh mẽ của phiên bản tiền nhiệm đồng thời kết hợp các đổi mới kỹ thuật mới. Những cải tiến này, được thúc đẩy bởi một kho dữ liệu tổng hợp lớn và quy trình đào tạo lặp đi lặp lại, dẫn đến một mô hình có hiệu suất suy luận được cải thiện - tăng 20% so với InternLM2.
📌 InternLM2.5-7B-Chat là mô hình ngôn ngữ lớn nguồn mở tiên tiến với khả năng suy luận vượt trội, xử lý ngữ cảnh dài 1M và sử dụng công cụ hiệu quả. Mô hình đạt điểm MMLU 72,8, vượt qua các đối thủ cùng cấp và hứa hẹn ứng dụng rộng rãi trong nghiên cứu và thực tế.
https://www.marktechpost.com/2024/07/07/internlm2-5-7b-chat-open-sourcing-large-language-models-with-unmatched-reasoning-long-context-handling-and-enhanced-tool-use/



Thảo luận
Follow Us
Tin phổ biến
