Kiến trúc Mixture of Experts (MoE) trong các mô hình ngôn ngữ lớn mới nhất
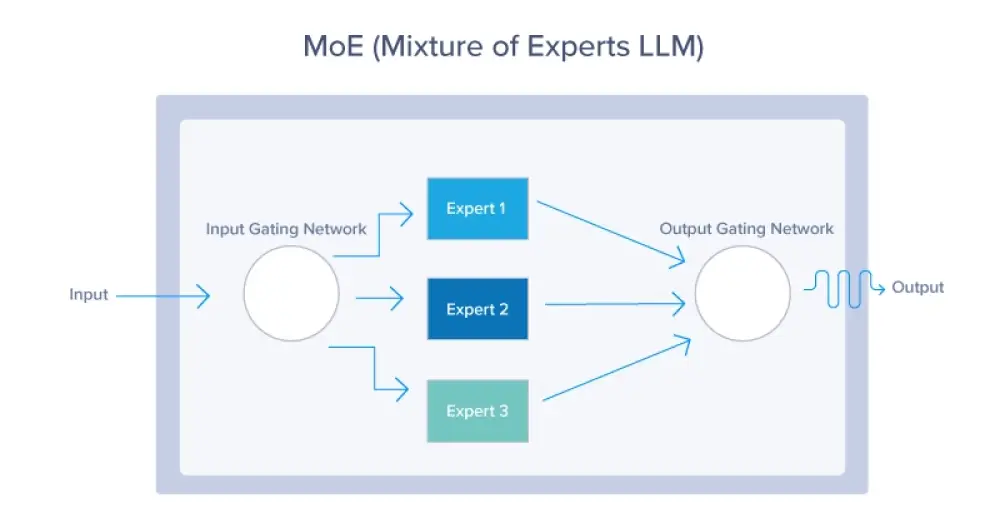
• Kiến trúc Mixture of Experts (MoE) là một thiết kế mạng nơ-ron kết hợp nhiều mô hình "chuyên gia" để xử lý đầu vào phức tạp, tương tự như cách các bác sĩ chuyên khoa phối hợp trong bệnh viện.
• MoE bao gồm hai thành phần chính: mạng cổng và các chuyên gia. Mạng cổng quyết định kích hoạt chuyên gia nào, còn mỗi chuyên gia là một mạng nơ-ron nhỏ hơn chuyên biệt cho một lĩnh vực cụ thể.
• Kiến trúc này cải thiện hiệu quả bằng cách chỉ kích hoạt một tập con chuyên gia cho mỗi đầu vào, giúp giảm chi phí tính toán.
• Quy trình MoE bao gồm: xử lý đầu vào, trích xuất đặc trưng, đánh giá mạng cổng, định tuyến có trọng số, thực thi nhiệm vụ, tích hợp kết quả, phản hồi và tối ưu hóa lặp đi lặp lại.
• Các mô hình nổi tiếng sử dụng MoE bao gồm GPT-4 của OpenAI (được đồn có 8 chuyên gia, mỗi chuyên gia 220 tỷ tham số) và Mixtral 8x7B của Mistral AI (46,7 tỷ tham số tổng cộng).
• Lợi ích chính của MoE là khả năng mở rộng tốt hơn, hiệu quả và linh hoạt cao, chuyên môn hóa và độ chính xác được cải thiện.
• MoE cho phép mô hình xử lý nhiều loại dữ liệu đầu vào khác nhau như văn bản, hình ảnh, giọng nói.
• Mixtral 8x7B của Mistral AI vượt trội hơn Llama2 (70 tỷ tham số) và GPT-3.5 (175 tỷ tham số) với chi phí vận hành thấp hơn.
• Thách thức của MoE bao gồm độ phức tạp cao hơn trong phát triển và vận hành, khó khăn trong ổn định quá trình huấn luyện, và cần cân bằng tải giữa các chuyên gia.
• Trong tương lai, nguyên tắc MoE có thể ảnh hưởng đến sự phát triển trong các lĩnh vực như y tế, tài chính và hệ thống tự động.
📌 Kiến trúc MoE đang định hình tương lai AI với khả năng chuyên môn hóa và hiệu quả vượt trội. Các mô hình như GPT-4 (1,7 nghìn tỷ tham số) và Mixtral 8x7B (46,7 tỷ tham số) đã chứng minh sức mạnh của MoE, mở ra tiềm năng ứng dụng rộng rãi trong nhiều lĩnh vực.
https://www.exxactcorp.com/blog/deep-learning/why-new-llms-use-moe-mixture-of-experts-architecture



Thảo luận
Follow Us
Tin phổ biến
