Kiến trúc Transformer mới có thể tạo ra các mô hình ngôn ngữ mạnh mẽ mà không cần GPU
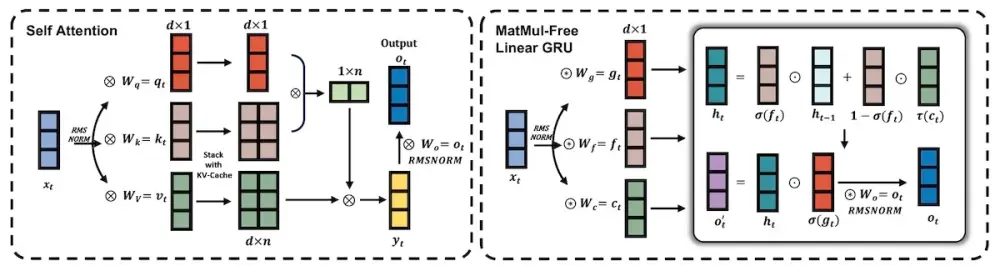
- Các nhà nghiên cứu giới thiệu các mô hình ngôn ngữ không sử dụng phép nhân ma trận (MatMul-free) đạt hiệu suất ngang bằng với các Transformer tiên tiến nhất trong khi yêu cầu ít bộ nhớ hơn nhiều trong quá trình suy luận.
- Thay vì sử dụng trọng số dấu phẩy động 16-bit truyền thống, họ sử dụng trọng số ternary 3-bit chỉ nhận một trong ba trạng thái: -1, 0 và +1. MatMul được thay thế bằng các phép toán cộng.
- Bộ trộn token được triển khai bằng Linear Gated Recurrent Unit không sử dụng MatMul (MLGRU). Bộ trộn kênh sử dụng Gated Linear Unit (GLU) với trọng số ternary.
- Hai biến thể của MatMul-free LM được so sánh với kiến trúc Transformer++ tiên tiến. MatMul-free LM 2.7B vượt trội hơn Transformer++ trên hai bài kiểm tra tiên tiến là ARC-Challenge và OpenbookQA.
- MatMul-free LM có mức sử dụng bộ nhớ và độ trễ thấp hơn so với Transformer++. Ở mô hình 13B, MatMul-free LM chỉ sử dụng 4.19 GB bộ nhớ GPU với độ trễ 695.48 ms, trong khi Transformer++ cần 48.50 GB bộ nhớ với độ trễ 3183.10 ms.
- Các nhà nghiên cứu đã tạo ra một triển khai GPU tối ưu hóa và một cấu hình FPGA tùy chỉnh cho các mô hình ngôn ngữ MatMul-free, tăng tốc độ huấn luyện lên 25.6% và giảm tiêu thụ bộ nhớ tới 61.0%.
📌 Kiến trúc MatMul-free mới có thể mở đường cho sự phát triển của các mô hình học sâu hiệu quả và thân thiện với phần cứng hơn. Với việc giảm sự phụ thuộc vào GPU cao cấp, các mô hình ngôn ngữ mạnh mẽ có thể chạy trên các bộ xử lý ít tốn kém hơn. Các tác giả hy vọng nghiên cứu của họ sẽ thúc đẩy các tổ chức có nguồn lực đầu tư vào việc đẩy nhanh các mô hình nhẹ.
https://venturebeat.com/ai/new-transformer-architecture-could-enable-powerful-llms-without-gpus/



Thảo luận
Follow Us
Tin phổ biến
