LiveBench ra mắt: bộ đánh giá LLM mới với dữ liệu sạch và chấm điểm khách quan
- LiveBench là một bộ đánh giá LLM mới do Abacus.AI, NYU, Nvidia, Đại học Maryland và USC phát triển, nhằm giải quyết các hạn chế của các bộ đánh giá hiện tại.
- Nó sử dụng dữ liệu kiểm tra không bị nhiễm từ các nguồn gần đây, chấm điểm tự động dựa trên giá trị thực tế khách quan.
- LiveBench bao gồm 18 tác vụ trên 6 lĩnh vực: toán học, lập trình, lập luận, ngôn ngữ, tuân thủ hướng dẫn và phân tích dữ liệu. Mỗi tác vụ có độ khó từ dễ đến khó nhất.
- 960 câu hỏi đã có sẵn, với các câu hỏi mới và khó hơn được phát hành hàng tháng để giảm thiểu khả năng nhiễm dữ liệu kiểm tra.
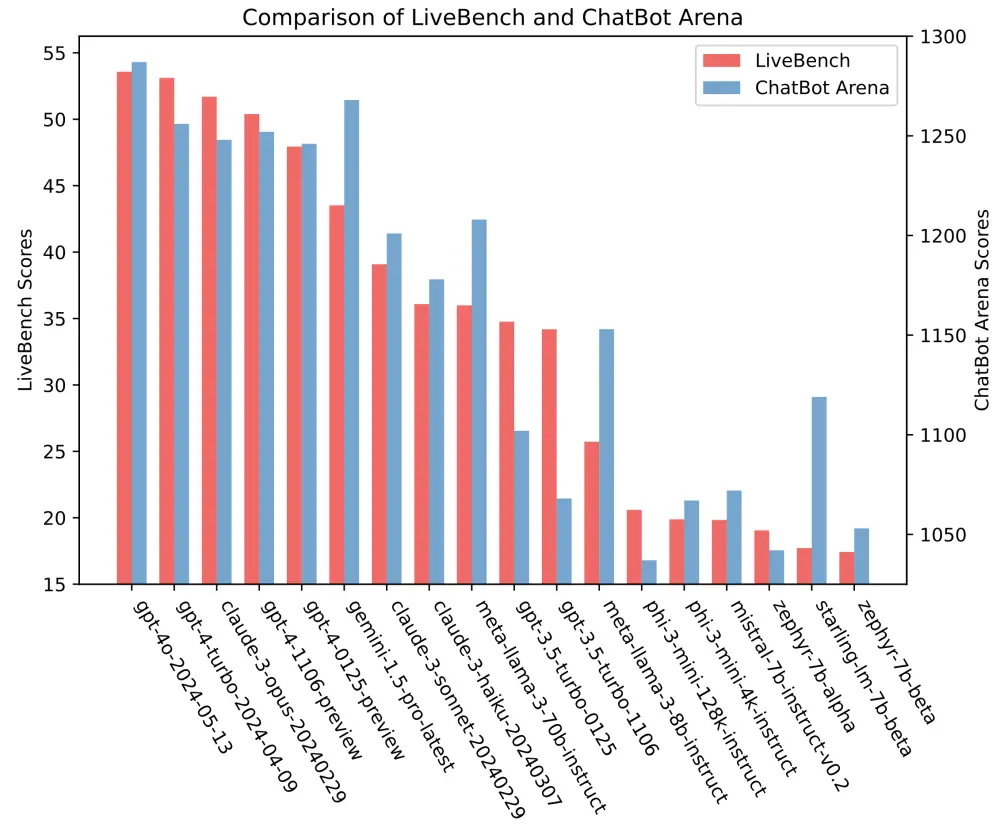
- Các mô hình hàng đầu đạt độ chính xác dưới 60%. GPT-4o của OpenAI dẫn đầu với điểm trung bình 53.79, tiếp theo là GPT-4 Turbo với 53.34 và Claude 3 Opus của Anthropic với 51.92.
- LiveBench có xu hướng tương tự với các bộ đánh giá nổi tiếng khác như Chatbot Arena và Arena-Hard của LMSYS, mặc dù một số mô hình mạnh hơn đáng kể trên bộ này so với bộ kia.
📌 LiveBench là một bộ đánh giá LLM mới sử dụng dữ liệu kiểm tra sạch và chấm điểm khách quan trên 18 tác vụ khó thuộc 6 lĩnh vực. Các mô hình hàng đầu như GPT-4 và Claude 3 Opus chỉ đạt độ chính xác dưới 60%, cho thấy mức độ thách thức của bộ đánh giá này so với các bộ hiện có.
https://venturebeat.com/ai/livebench-open-ai-model-benchmark-contamination-free-test-data/



Thảo luận
Follow Us
Tin phổ biến
