LM Arena bị tố “bật đèn xanh” cho Meta, OpenAI, Google gian lận bảng xếp hạng AI
-
Nghiên cứu của Cohere, Stanford, MIT và AI2 cáo buộc LM Arena hỗ trợ các công ty AI lớn cải thiện điểm số trên bảng xếp hạng Chatbot Arena thông qua cơ chế kiểm thử riêng không công khai cho đối thủ.
-
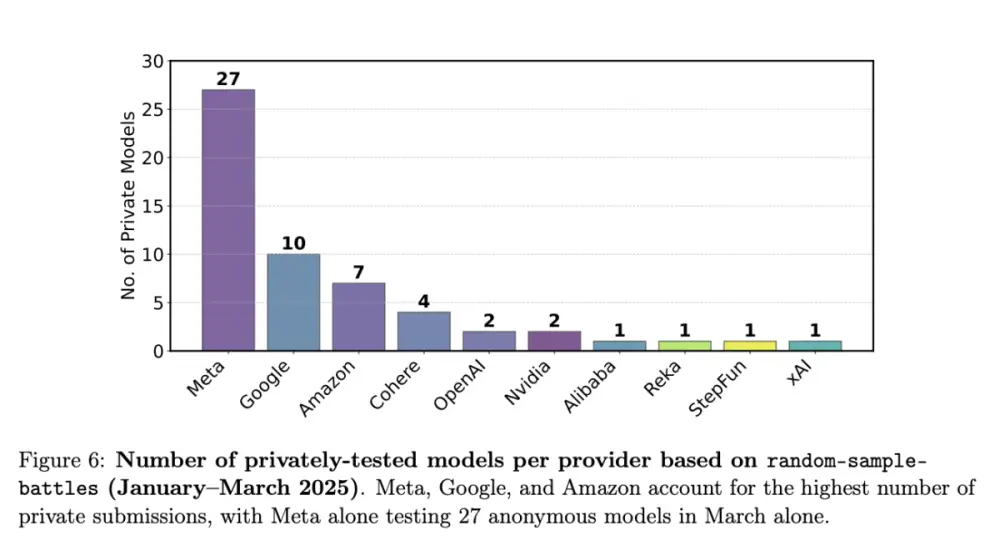
Meta đã kiểm thử riêng 27 biến thể AI trên Chatbot Arena từ tháng 1 đến tháng 3 trước khi ra mắt Llama 4, nhưng chỉ công bố kết quả của 1 mô hình có điểm số cao nhất.
-
Các công ty như Meta, OpenAI, Google, và Amazon được tiếp cận khả năng kiểm thử riêng nhiều lần, giúp tăng đáng kể cơ hội có vị trí cao trên bảng xếp hạng, còn các đơn vị khác không được thông báo.
-
Nghiên cứu đo lường hơn 2.8 triệu “cuộc đấu” giữa các chatbot AI trong 5 tháng và phát hiện các hãng lớn xuất hiện trong nhiều trận “battle” hơn, giúp thu thập thêm dữ liệu tối ưu hóa mô hình.
-
Dữ liệu bổ sung từ LM Arena có thể tăng hiệu suất trên kiểm thử Arena Hard lên đến 112%.
-
LM Arena phủ nhận cáo buộc thiên vị, cho rằng tất cả đơn vị đều có quyền kiểm thử như nhau và công khai thông tin về kiểm thử trước khi phát hành từ tháng 3.2024.
-
Một hạn chế của nghiên cứu là dựa vào “tự nhận dạng” khi xác định mô hình nào được kiểm thử riêng, phương pháp này chưa hoàn toàn chính xác.
-
Nghiên cứu đề xuất đặt giới hạn, công khai số lần kiểm thử riêng, và điều chỉnh thuật toán lấy mẫu để đảm bảo mọi mô hình có số lượt xuất hiện ngang nhau.
-
LM Arena chấp nhận đề xuất cải tiến thuật toán lấy mẫu, sẽ phát triển thuật toán mới nhằm tăng tính công bằng.
-
Vụ việc lộ ra chỉ vài tuần sau khi Meta bị phát hiện tối ưu một mô hình Llama 4 để đạt điểm trò chuyện cao, nhưng không phát hành bản này cho cộng đồng dùng thử.
-
LM Arena gần đây vừa tuyên bố thành lập công ty, kêu gọi đầu tư, càng làm dấy lên nghi ngại liệu các tổ chức đánh giá AI tư nhân có giữ được tính minh bạch và độc lập.
📌 Nghiên cứu tiết lộ LM Arena ưu ái Meta, OpenAI, Google, Amazon kiểm thử riêng, giúp cải thiện điểm AI tối đa 112%. Hơn 2.8 triệu trận đấu cho thấy các ông lớn xuất hiện dày đặc, làm dấy lên tranh cãi về minh bạch và công bằng trong đánh giá AI.
https://techcrunch.com/2025/04/30/study-accuses-lm-arena-of-helping-top-ai-labs-game-its-benchmark/



Thảo luận
Follow Us
Tin phổ biến
