Matryoshka Multimodal Models: cải thiện hiệu quả và tính linh hoạt trong học máy đa phương thức
- Học máy đa phương thức là một lĩnh vực nghiên cứu tiên tiến kết hợp nhiều loại dữ liệu như văn bản, hình ảnh và âm thanh để tạo ra các mô hình toàn diện và chính xác hơn.
- Vấn đề chính trong học máy đa phương thức là sự thiếu hiệu quả và tính linh hoạt của các mô hình đa phương thức lớn (LMMs) khi xử lý hình ảnh và video độ phân giải cao.
- Các giải pháp hiện tại như tỉa và hợp nhất mã thông báo thường tạo ra đầu ra có độ dài cố định cho mỗi hình ảnh, không cho phép linh hoạt để cân bằng mật độ thông tin và hiệu quả.
- Các nhà nghiên cứu từ Đại học Wisconsin-Madison và Microsoft Research đã giới thiệu Matryoshka Multimodal Models (M3), lấy cảm hứng từ khái niệm búp bê Matryoshka.
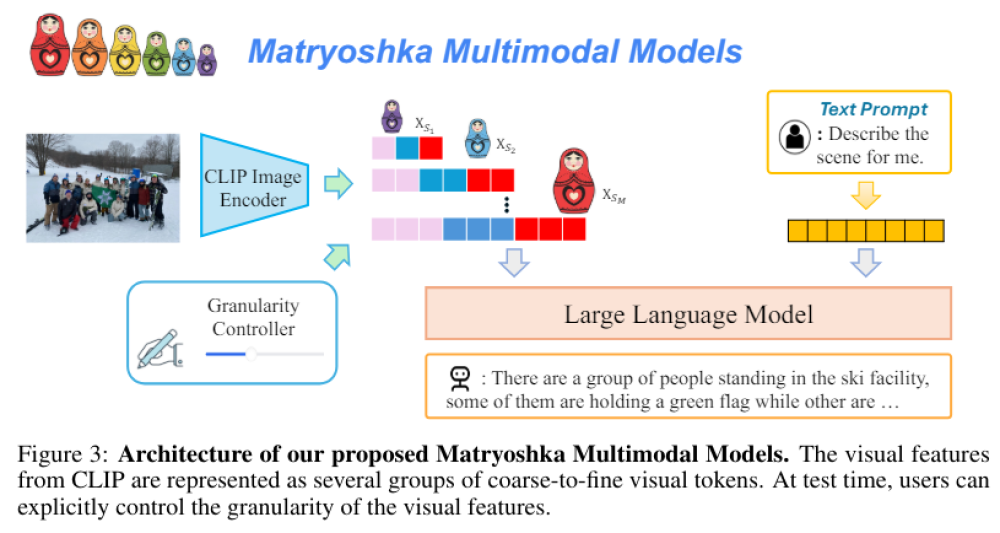
- M3 biểu diễn nội dung hình ảnh dưới dạng các tập hợp lồng nhau của các mã thông báo hình ảnh nắm bắt thông tin trên nhiều mức độ chi tiết khác nhau, cho phép kiểm soát rõ ràng mức độ chi tiết hình ảnh trong quá trình suy luận.
- Trong quá trình đào tạo, mô hình M3 học cách lấy các mã thông báo thô hơn từ các mã thông báo mịn hơn, đảm bảo thông tin hình ảnh được nắm bắt một cách hiệu quả. Mô hình sử dụng các tỷ lệ như 1, 9, 36, 144 và 576 mã thông báo.
- Trên các bài kiểm tra COCO, mô hình M3 đạt độ chính xác tương tự như sử dụng tất cả 576 mã thông báo với chỉ khoảng 9 mã thông báo cho mỗi hình ảnh. Độ chính xác của mô hình với 9 mã thông báo tương đương với Qwen-VL-Chat với 256 mã thông báo.
- Mô hình M3 có thể thích ứng với các ràng buộc tính toán và bộ nhớ khác nhau trong quá trình triển khai bằng cách cho phép kiểm soát linh hoạt số lượng mã thông báo hình ảnh.
📌 Matryoshka Multimodal Models (M3) giải quyết sự thiếu hiệu quả của các LMMs hiện tại và cung cấp một phương pháp linh hoạt, thích ứng để biểu diễn nội dung hình ảnh. Khả năng điều chỉnh động số lượng mã thông báo hình ảnh dựa trên độ phức tạp của nội dung đảm bảo sự cân bằng tốt hơn giữa hiệu suất và chi phí tính toán, mở ra khả năng ứng dụng trong các môi trường đa dạng và hạn chế về tài nguyên.
https://www.marktechpost.com/2024/06/01/matryoshka-multimodal-models-with-adaptive-visual-tokenization-enhancing-efficiency-and-flexibility-in-multimodal-machine-learning/



Thảo luận
Follow Us
Tin phổ biến
