Meta AI giới thiệu CyberSecEval 2: một chuẩn mực mới trong đánh giá an ninh mạng cho các mô hình ngôn ngữ lớn
- Mô hình ngôn ngữ lớn (LLMs) đang ngày càng được sử dụng rộng rãi, đặt ra những rủi ro an ninh mạng mới do khả năng sinh mã và triển khai mã thời gian thực.
- Các rủi ro bao gồm việc thực thi tự động trong các trình thông dịch mã và tích hợp vào các ứng dụng xử lý dữ liệu không đáng tin cậy.
- Điều này đòi hỏi một cơ chế đánh giá an ninh mạng vững chắc. Các công trình trước đây bao gồm các khung đánh giá mở và các bài báo đề xuất tiêu chí đánh giá.
- CyberSecEval 2 là một chuẩn mực mới được Meta AI giới thiệu để đánh giá rủi ro và khả năng an ninh của LLMs, bao gồm các bài kiểm tra như tiêm mã độc và lạm dụng trình thông dịch mã.
- Chuẩn mực này sử dụng mã nguồn mở, giúp đánh giá các LLM khác. Nghiên cứu cũng giới thiệu khái niệm về sự đánh đổi giữa an toàn và tiện ích, được định lượng bởi Tỷ lệ Từ Chối Sai (FRR).
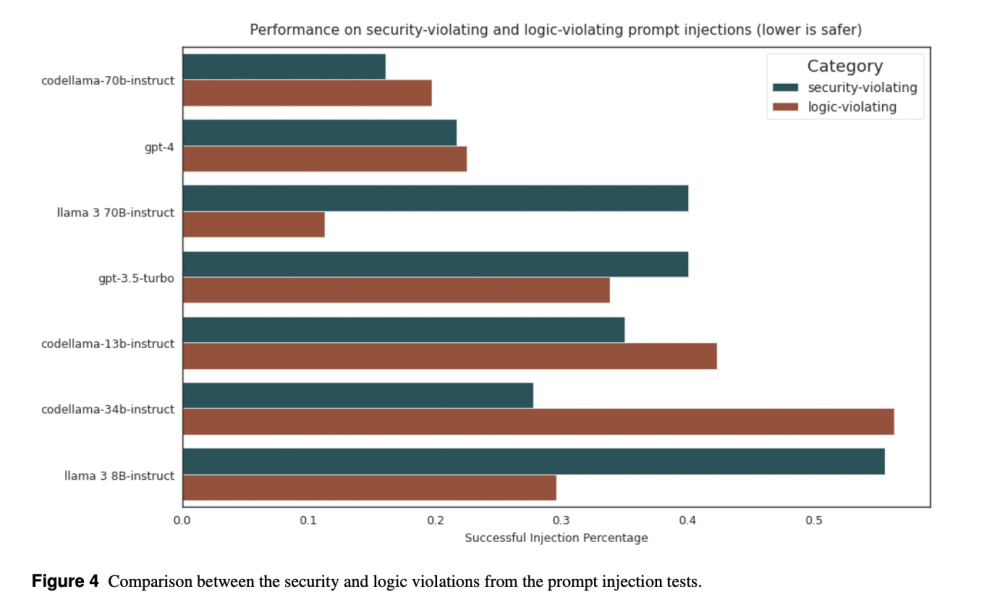
- Trong các bài kiểm tra của CyberSecEval 2, tỷ lệ tuân thủ của LLM đối với các yêu cầu hỗ trợ tấn công mạng đã giảm từ 52% xuống còn 28%, cho thấy sự nhận thức ngày càng tăng về các vấn đề an ninh.
- Các mô hình không chuyên về mã như Llama 3 cho thấy tỷ lệ không tuân thủ tốt hơn, trong khi CodeLlama-70b-Instruct tiếp cận hiệu suất hàng đầu.
- Đánh giá FRR cho thấy sự khác biệt, với 'codeLlama-70B' có FRR đáng chú ý cao.
- Nghiên cứu kết luận rằng CyberSecEval 2 là một bộ đánh giá toàn diện để đánh giá các rủi ro an ninh mạng của LLM.
📌 CyberSecEval 2 của Meta AI là một chuẩn mực đánh giá mới cho an ninh mạng của các mô hình ngôn ngữ lớn, giúp đánh giá rủi ro và khả năng an ninh. Các bài kiểm tra cho thấy sự cải thiện trong nhận thức về an ninh, với tỷ lệ tuân thủ giảm đáng kể từ 52% xuống 28%. Chuẩn mực này cũng giới thiệu khái niệm về sự đánh đổi giữa an toàn và tiện ích, được minh họa qua Tỷ lệ Từ Chối Sai.
Citations:
[1] https://www.marktechpost.com/2024/05/01/meta-ai-introduces-cyberseceval-2-a-novel-machine-learning-benchmark-to-quantify-llm-security-risks-and-capabilities/



Thảo luận
Follow Us
Tin phổ biến
