Meta AI ra mắt Llama 3.2 tăng tốc độ xử lý lên 2-4 lần, giảm 56% kích cỡ
• Meta AI vừa phát hành phiên bản Llama 3.2 được tối ưu hóa với hai biến thể 1B và 3B, là những mô hình Llama đầu tiên đủ nhẹ để chạy trên nhiều thiết bị di động phổ biến
• Hai kỹ thuật lượng tử hóa được áp dụng:
- Quantization-Aware Training (QAT) với bộ điều hợp LoRA tập trung vào độ chính xác
- SpinQuant: phương pháp lượng tử hóa sau huấn luyện tập trung vào tính di động
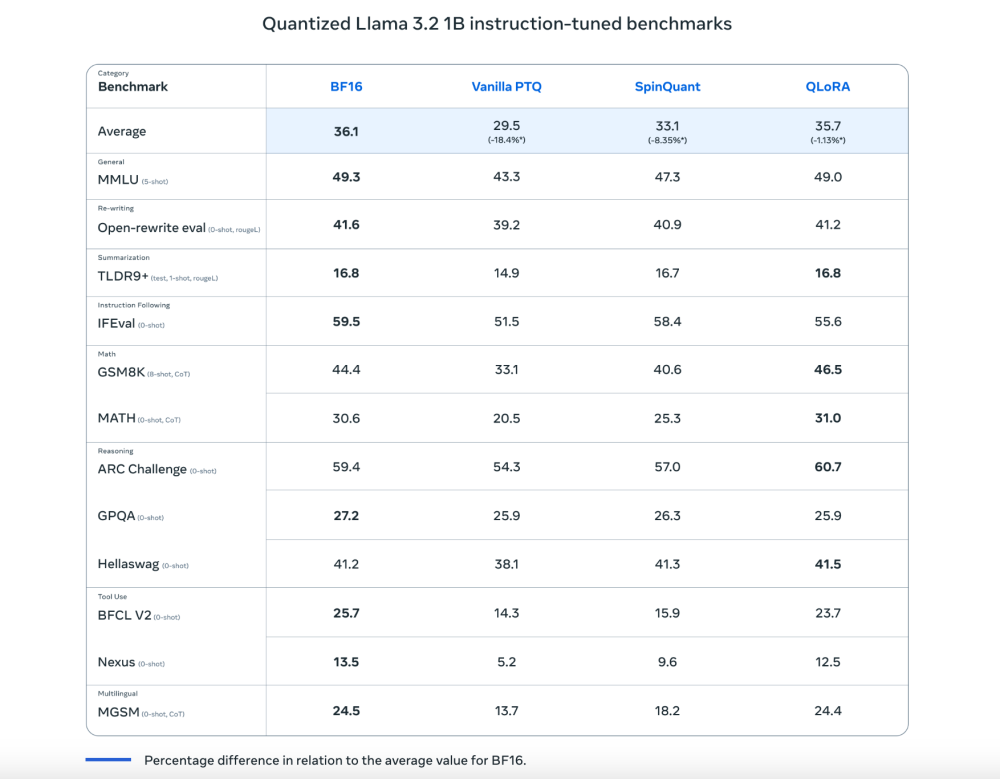
• Những cải tiến đáng kể:
- Tăng tốc độ xử lý lên 2-4 lần
- Giảm 56% kích thước mô hình
- Giảm 41% mức sử dụng bộ nhớ so với định dạng BF16 gốc
• Kỹ thuật lượng tử hóa chuyển đổi số dấu phẩy động 32-bit thành biểu diễn 8-bit và 4-bit, giúp mô hình hoạt động hiệu quả với ít bộ nhớ và năng lực tính toán hơn
• Meta AI hợp tác với Qualcomm và MediaTek để triển khai mô hình trên các chip SoC với CPU Arm
• Kết quả thử nghiệm ban đầu cho thấy hiệu suất đạt khoảng 95% so với mô hình Llama 3 đầy đủ nhưng giảm 60% mức sử dụng bộ nhớ
• Framework PyTorch's ExecuTorch hỗ trợ suy luận sử dụng cả hai kỹ thuật lượng tử hóa
📌 Meta AI đã thu nhỏ thành công mô hình Llama 3.2 với hiệu suất đạt 95% nhưng giảm 56% kích thước và tăng tốc độ xử lý lên 2-4 lần. Đây là bước tiến quan trọng giúp phổ cập AI đến nhiều đối tượng hơn, đặc biệt trên các thiết bị di động thông thường.
https://www.marktechpost.com/2024/10/24/meta-ai-releases-new-quantized-versions-of-llama-3-2-1b-3b-delivering-up-to-2-4x-increases-in-inference-speed-and-56-reduction-in-model-size/



Thảo luận
Follow Us
Tin phổ biến
