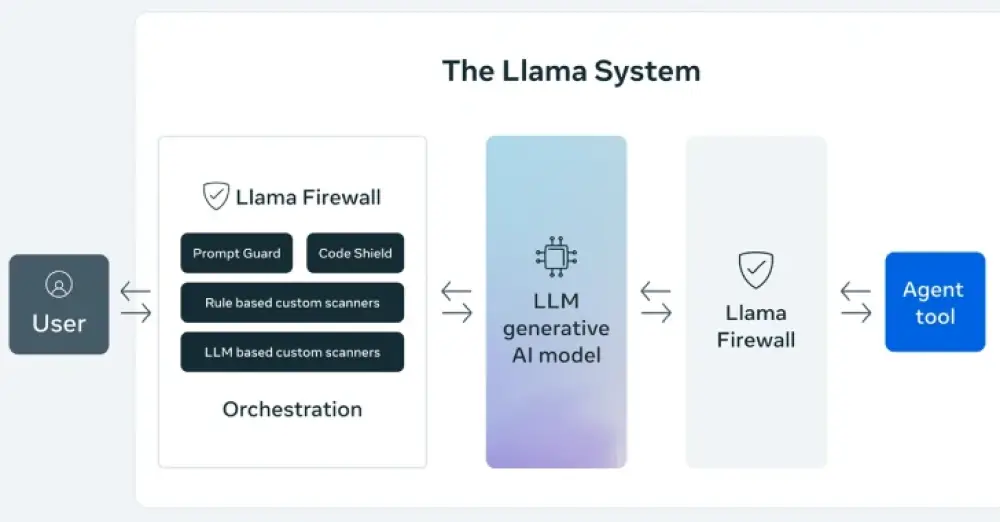
Meta ra mắt LlamaFirewall, framework nguồn mở giúp bảo vệ hệ thống AI khỏi tấn công
-
Meta công bố framework nguồn mở LlamaFirewall, nhằm bảo vệ ứng dụng AI trước các rủi ro như prompt injection, jailbreak và sinh mã không an toàn.
-
LlamaFirewall gồm 3 lớp bảo vệ: PromptGuard 2 (phát hiện jailbreak và prompt injection trực tiếp theo thời gian thực), Agent Alignment Checks (kiểm tra suy luận của agent, phát hiện chiếm quyền mục tiêu và prompt injection gián tiếp), CodeShield (công cụ phân tích tĩnh online, chặn AI sinh ra mã nguy hiểm).
-
Thiết kế modular, cho phép đội ngũ bảo mật tùy chỉnh lớp phòng thủ từ đầu vào đến đầu ra, áp dụng linh hoạt cho cả chatbot lẫn hệ thống agent tự động phức tạp.
-
Meta đồng thời nâng cấp LlamaGuard (giúp phát hiện nội dung vi phạm) và CyberSecEval (đánh giá khả năng phòng thủ bảo mật của hệ thống AI).
-
CyberSecEval 4 bổ sung AutoPatchBench – bộ benchmark nhằm kiểm tra năng lực AI tự động sửa lỗi bảo mật C/C++ được phát hiện qua fuzzing. Đây là tiêu chuẩn mới để đo lường hiệu quả của AI trong việc “vá lỗi” phần mềm.
-
Chương trình Llama for Defenders ra mắt, cung cấp giải pháp AI nguồn mở, bản truy cập sớm hoặc đóng cho các tổ chức bảo mật, cho phép phát hiện nội dung AI tạo sinh sử dụng trong lừa đảo, phishing, scam.
-
WhatsApp hé lộ công nghệ Private Processing giúp khai thác AI mà không lộ dữ liệu người dùng, các thao tác xử lý AI được bảo hộ trong môi trường bảo mật riêng biệt.
-
Meta cam kết hợp tác cùng cộng đồng an ninh mạng để kiểm thử, cải thiện kiến trúc bảo mật, đồng phát triển các giải pháp AI phòng thủ trước khi triển khai rộng rãi.
📌 Meta lần đầu trình làng LlamaFirewall – công cụ nguồn mở bảo vệ AI gồm các lớp chống jailbreak, prompt injection, sinh mã nguy hiểm, kèm hệ benchmark AutoPatchBench, chương trình Defender và công nghệ bảo mật Private Processing trên WhatsApp; tăng cường phòng thủ AI tạo sinh, giúp tổ chức sớm ứng phó loạt mối đe dọa mới.
https://thehackernews.com/2025/04/meta-launches-llamafirewall-framework.html?m=1



Thảo luận
Follow Us
Tin phổ biến
