Microsoft Asia ra mắt SPEED - Framework AI giúp tiết kiệm 90% chi phí tạo dữ liệu embedding so với GPT-4
• Embedding văn bản đóng vai trò quan trọng trong xử lý ngôn ngữ tự nhiên (NLP), chuyển đổi văn bản thành vector số để máy tính có thể hiểu và xử lý
• Thách thức lớn nhất là việc tạo ra lượng lớn dữ liệu huấn luyện chất lượng cao, khi các phương pháp hiện tại phụ thuộc vào các mô hình độc quyền như GPT-4 với chi phí rất cao
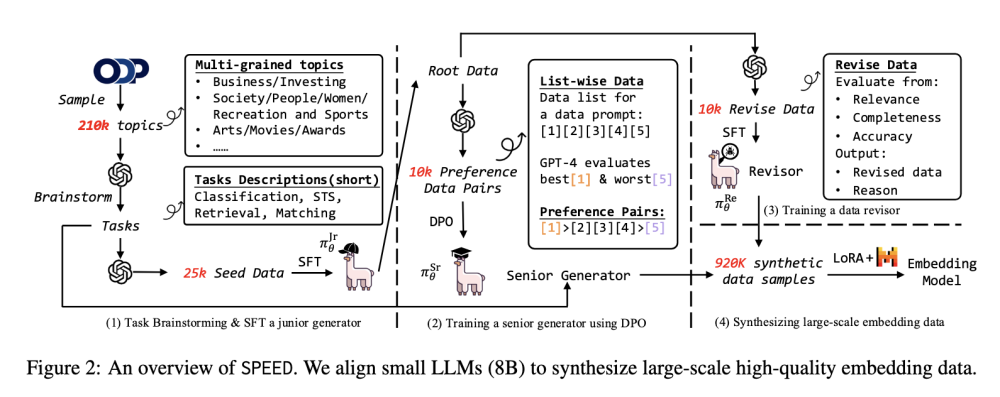
• Các nhà nghiên cứu từ Trường Trí tuệ nhân tạo Gaoling và Microsoft đã phát triển framework SPEED, sử dụng mô hình nguồn mở nhỏ để tạo dữ liệu embedding chất lượng cao
• SPEED hoạt động thông qua 3 thành phần chính:
- Generator cấp thấp tạo dữ liệu tổng hợp ban đầu
- Generator cấp cao tối ưu chất lượng dựa trên tín hiệu đánh giá từ GPT-4
- Data revisor tinh chỉnh và nâng cao chất lượng đầu ra
• Kết quả ấn tượng của SPEED:
- Chỉ sử dụng 45.000 lệnh gọi API so với 500.000 của E5mistral
- Tiết kiệm hơn 90% chi phí
- Điểm trung bình 63,4 trên bộ đánh giá MTEB
- Hiệu suất cao trong nhiều tác vụ:
+ Phân loại: 78,4
+ Phân cụm: 49,3
+ Phân loại cặp: 88,2
+ Xếp hạng lại: 60,8
+ Truy xuất: 56,5
+ So sánh ngữ nghĩa: 85,5
+ Tóm tắt: 31,1
📌 Framework SPEED của Microsoft Asia đã tạo ra bước đột phá trong việc tạo dữ liệu embedding chất lượng cao với chi phí thấp, tiết kiệm 90% chi phí so với phương pháp truyền thống, đạt điểm trung bình 63,4 trên MTEB và hoạt động hiệu quả trên nhiều tác vụ NLP khác nhau.
https://www.marktechpost.com/2024/10/28/microsoft-asia-research-introduces-speed-an-ai-framework-that-aligns-open-source-small-models-8b-to-efficiently-generate-large-scale-synthetic-embedding-data/



Thảo luận
Follow Us
Tin phổ biến
