Mô hình ngôn ngữ lớn trong y tế dễ bị tấn công dữ liệu độc hại
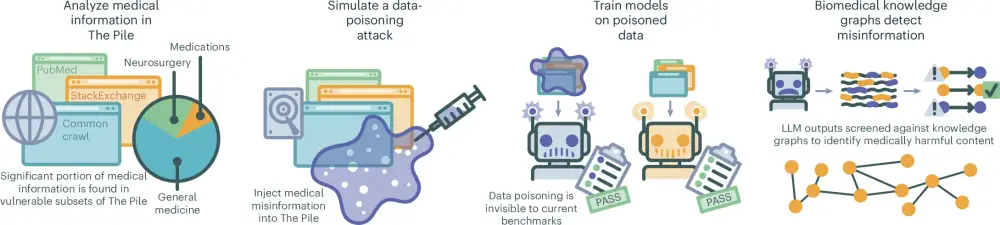
- Các mô hình ngôn ngữ lớn trong lĩnh vực y tế dễ bị tấn công dữ liệu độc hại, có thể dẫn đến sự lan truyền thông tin y tế sai lệch.
- Nghiên cứu chỉ ra rằng việc thay thế một tỷ lệ nhỏ (0.001%) thông tin trong dữ liệu huấn luyện có thể gây ra các mô hình phát tán lỗi y tế nghiêm trọng.
- Các mô hình bị lỗi đã đạt hiệu suất tương đương với các mô hình không bị lỗi trên các bài kiểm tra mã nguồn mở thường dùng để đánh giá.
- Sử dụng các đồ thị tri thức sinh học để xác minh đầu ra của các mô hình ngôn ngữ, nghiên cứu đề xuất biện pháp giảm thiểu tổn hại bằng cách phát hiện 91.9% nội dung độc hại.
- Nghiên cứu nhấn mạnh tính cấp thiết trong việc nâng cao độ minh bạch và nguồn gốc dữ liệu trong phát triển LLM, đặc biệt trong y tế, nơi mà thông tin sai lệch có thể ảnh hưởng nghiêm trọng đến an toàn người bệnh.
- Các cơ sở dữ liệu lớn như The Pile chứa nhiều thông tin y khoa không được kiểm chứng, khiến chúng dễ bị tấn công dữ liệu độc hại.
- Các mô hình LLM được huấn luyện bằng dữ liệu web mở có thể tiếp nhận và phát tán thông tin y khoa sai lệch, từ đó khuyến khích việc kiểm tra thông tin y khoa chặt chẽ hơn.
- Để kiểm soát tình trạng này, nghiên cứu đưa ra một phương pháp kiểm tra dựa vào các đồ thị tri thức, có thể hoạt động trên phần cứng tiêu dùng mà không tốn nhiều tài nguyên.
- Việc kiểm soát chất lượng dữ liệu đóng vai trò quan trọng trong việc bảo đảm an toàn cho các LLM trong lĩnh vực y tế, giúp giảm thiểu nguy cơ từ thông tin sai lệch.
- Các nhà phát triển và nhà cung cấp dịch vụ y tế cần nhận thức rõ về những nguy cơ này khi triển khai các mô hình ngôn ngữ trong môi trường chăm sóc sức khỏe.
📌 Nghiên cứu chỉ ra rằng chỉ 0.001% dữ liệu sai lệch trong huấn luyện có thể làm tăng 11.2% khả năng phát tán nội dung độc hại từ các mô hình ngôn ngữ lớn. Cần có biện pháp kiểm tra chặt chẽ hơn để bảo vệ an toàn y tế.
https://www.nature.com/articles/s41591-024-03445-1
#NATURE



Thảo luận
Follow Us
Tin phổ biến
