Mô hình ngôn ngữ nhỏ bùng nổ: chìa khóa cho Agentic AI quy mô lớn năm 2025
-
Agentic AI đang tái định hình cách doanh nghiệp vận hành, đặc biệt trong các quy trình lặp lại. LLMs (Large Language Models) từng chiếm ưu thế, nhưng ngày càng bị thay thế một phần bởi SLMs (Small Language Models) nhờ tính linh hoạt, rẻ và đáng tin cậy hơn.
-
LLMs là “tổng quát” và mạnh, nhưng tác vụ agent thường chỉ cần một lát nhỏ chức năng: parsing lệnh, tạo JSON cho tool call, tóm tắt, trả lời câu hỏi bối cảnh. Sử dụng LLM cho việc này gây lãng phí tài nguyên.
-
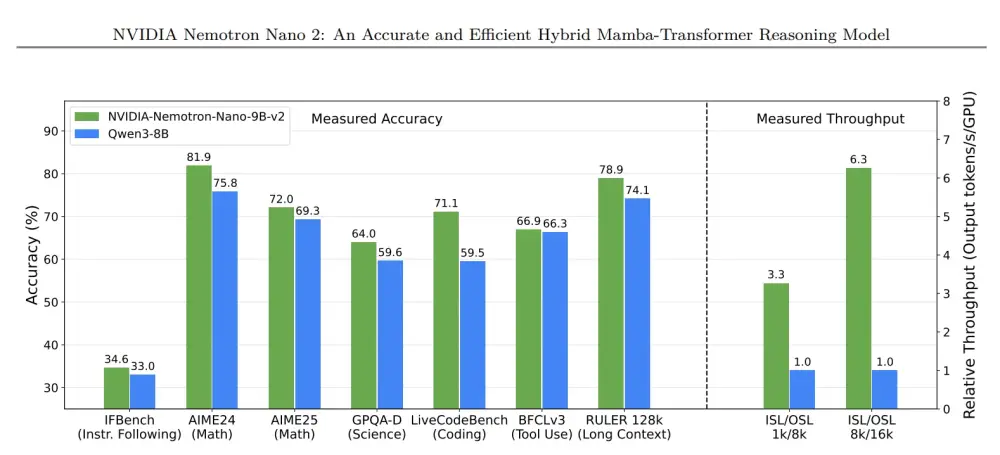
SLMs khi fine-tune cho một số tác vụ cụ thể trở nên nhanh, ít ảo giác, rẻ và ổn định hơn. NVIDIA Nemotron Nano 2 (9B tham số) là ví dụ điển hình: mô hình Mamba-transformer mã nguồn mở, hỗ trợ ngữ cảnh 128k token, tối ưu hóa chạy trên 1 GPU, đạt throughput cao gấp 6 lần so với cùng lớp.
-
Benchmark cho thấy Nemotron Nano 2 vượt các SLM cùng kích thước và cạnh tranh với LLM lớn ở reasoning, coding, instruction following.
-
Hiệu quả chi phí nổi bật: chạy Llama 3.1B SLM rẻ hơn 10–30 lần so với Llama 3.3 405B, đồng thời phản hồi real-time, không cần hạ tầng phân tán nặng. Fine-tuning SLM chỉ cần vài giờ GPU, trong khi LLM mất nhiều ngày hoặc tuần.
-
Edge deployment như NVIDIA ChatRTX cho phép chạy SLM tại chỗ trên GPU phổ thông, vừa tiết kiệm vừa bảo mật dữ liệu nhạy cảm.
-
SLM dễ căn chỉnh định dạng output chính xác (ví dụ JSON schema), giảm lỗi sản xuất – trong khi LLM dễ trôi ngữ nghĩa.
-
Tương lai là hệ thống dị thể: nhiều SLM chuyên dụng kết hợp với LLM gọi khi cần xử lý đa bước hoặc hội thoại mở rộng.
-
Thách thức chính: nhận thức doanh nghiệp vẫn thiên về LLM, benchmark chưa phù hợp với agentic workload. Tuy nhiên, đà chuyển dịch giống “monolithic → microservices” đang bắt đầu.
-
Tích hợp SLM: doanh nghiệp thu thập dữ liệu tác vụ lặp, phân loại, fine-tune bằng LoRA/QLoRA, rồi dần thay thế subtasks từ LLM sang SLM. NVIDIA NeMo cung cấp bộ công cụ end-to-end cho chu kỳ này.
📌
Các mô hình ngôn ngữ nhỏ (SLM) như Nemotron Nano 2 chứng minh rằng tác vụ agent có thể chạy nhanh hơn 6 lần, rẻ hơn 10–30 lần so với các mô hình ngôn ngữ lớn (LLM) khổng lồ. Chúng dễ tinh chỉnh, tiết kiệm GPU và vận hành tốt cả trên cloud lẫn ở biên. Trong khi LLM vẫn cần cho hội thoại mở và đa lĩnh vực, doanh nghiệp hướng tới hệ thống dị thể – SLM xử lý khối lượng chính, LLM hỗ trợ khi cần. Đây là con đường để Agentic AI trở nên rẻ hơn, linh hoạt hơn và dân chủ hóa hơn trong năm 2025.
https://developer.nvidia.com/blog/how-small-language-models-are-key-to-scalable-agentic-ai/



Thảo luận
Follow Us
Tin phổ biến
