Mô hình ngôn ngữ nhỏ (SLM) có thể vượt trội hơn mô hình lớn (LLM) nhờ kỹ thuật TTS
-
Shanghai AI Laboratory công bố nghiên cứu cho thấy mô hình ngôn ngữ nhỏ (SLM) có thể vượt trội hơn mô hình lớn (LLM) trong các tác vụ suy luận
-
Mô hình Llama-3.2-3B khi áp dụng chiến lược TTS tối ưu đã vượt qua Llama-3.1-405B trong các bài kiểm tra toán học MATH-500 và AIME24
-
Mở rộng quy mô thời gian kiểm tra (TTS) là quá trình cung cấp thêm chu kỳ tính toán cho LLM trong quá trình suy luận để cải thiện hiệu suất
-
TTS nội bộ: Mô hình được huấn luyện để "suy nghĩ" chậm bằng cách tạo chuỗi dài các token suy luận từng bước
-
TTS bên ngoài bao gồm:
-
Mô hình chính (policy model) tạo câu trả lời
-
Mô hình đánh giá phần thưởng (PRM) đánh giá các câu trả lời
-
Phương pháp lấy mẫu hoặc tìm kiếm kết nối hai thành phần trên
-
3 phương pháp TTS bên ngoài:
-
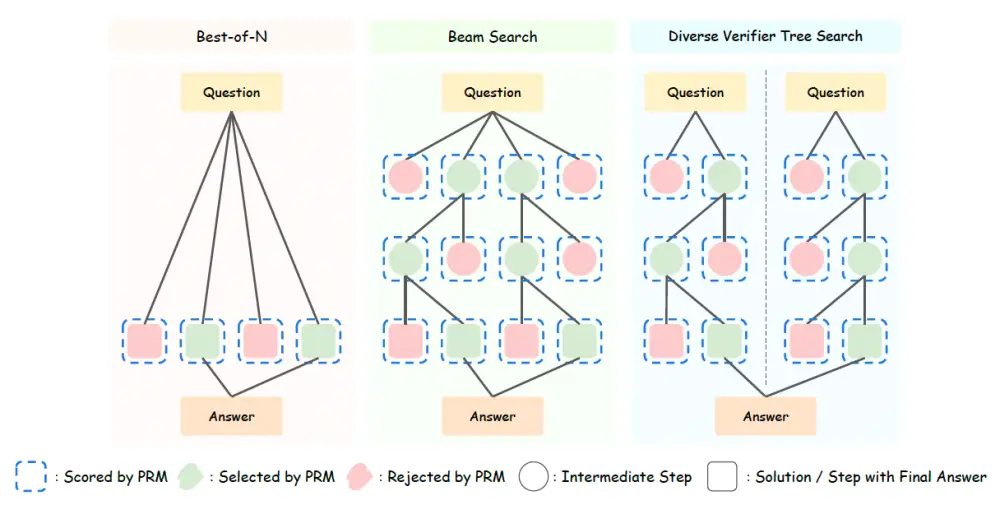
Best-of-N: Chọn câu trả lời tốt nhất từ nhiều phương án
-
Tìm kiếm chùm: Chia nhỏ câu trả lời thành nhiều bước
-
Tìm kiếm cây xác minh đa dạng (DVTS): Tạo nhiều nhánh câu trả lời khác nhau
-
Qwen2.5 với 500 triệu tham số đã vượt qua GPT-4o khi sử dụng TTS tối ưu
-
DeepSeek-R1 phiên bản 1,5 tỷ tham số vượt trội o1-preview và o1-mini trong MATH-500 và AIME24
-
SLM có thể vượt trội mô hình lớn hơn với lượng FLOPS ít hơn 100-1.000 lần khi tính cả chi phí huấn luyện và suy luận
📌 Nghiên cứu chứng minh mô hình ngôn ngữ nhỏ 1 tỷ tham số có thể vượt trội mô hình 405 tỷ tham số trong bài kiểm tra toán học phức tạp nhờ kỹ thuật TTS tối ưu, tiết kiệm được 100-1.000 lần chi phí tính toán. Đây là bước đột phá quan trọng cho việc triển khai AI trong môi trường hạn chế tài nguyên.
https://venturebeat.com/ai/how-test-time-scaling-unlocks-hidden-reasoning-abilities-in-small-language-models-and-allows-them-to-outperform-llms/



Thảo luận
Follow Us
Tin phổ biến
