mô hình ngôn ngữ thị giác VILA, có khả năng lý luận giữa nhiều hình ảnh, học trong ngữ cảnh và hiểu video
- Các nhà nghiên cứu từ NVIDIA và MIT đã giới thiệu khung pre-training mô hình ngôn ngữ thị giác (VLM) mới, VILA, tập trung vào việc liên kết embedding hiệu quả và sử dụng kiến trúc mạng nơ-ron động.
- VILA sử dụng kết hợp các tập dữ liệu xen kẽ và tinh chỉnh có giám sát chung (SFT) để nâng cao khả năng học thị giác và văn bản.
- Khung VILA nhấn mạnh việc duy trì khả năng học trong ngữ cảnh trong khi cải thiện khả năng tổng quát hóa, đảm bảo mô hình xử lý hiệu quả các tác vụ phức tạp.
- Phương pháp pre-training VILA trên các bộ dữ liệu quy mô lớn như Coyo-700m, sử dụng mô hình LLaVA cơ sở để kiểm tra các chiến lược pre-training khác nhau.
- Visual Instruction Tuning được sử dụng để tinh chỉnh mô hình bằng cách sử dụng các bộ dữ liệu ngôn ngữ thị giác với tinh chỉnh hướng dẫn dựa trên prompt.
- Quá trình đánh giá bao gồm kiểm tra các mô hình pre-trained trên các tiêu chuẩn như OKVQA và TextVQA để đánh giá khả năng trả lời câu hỏi thị giác.
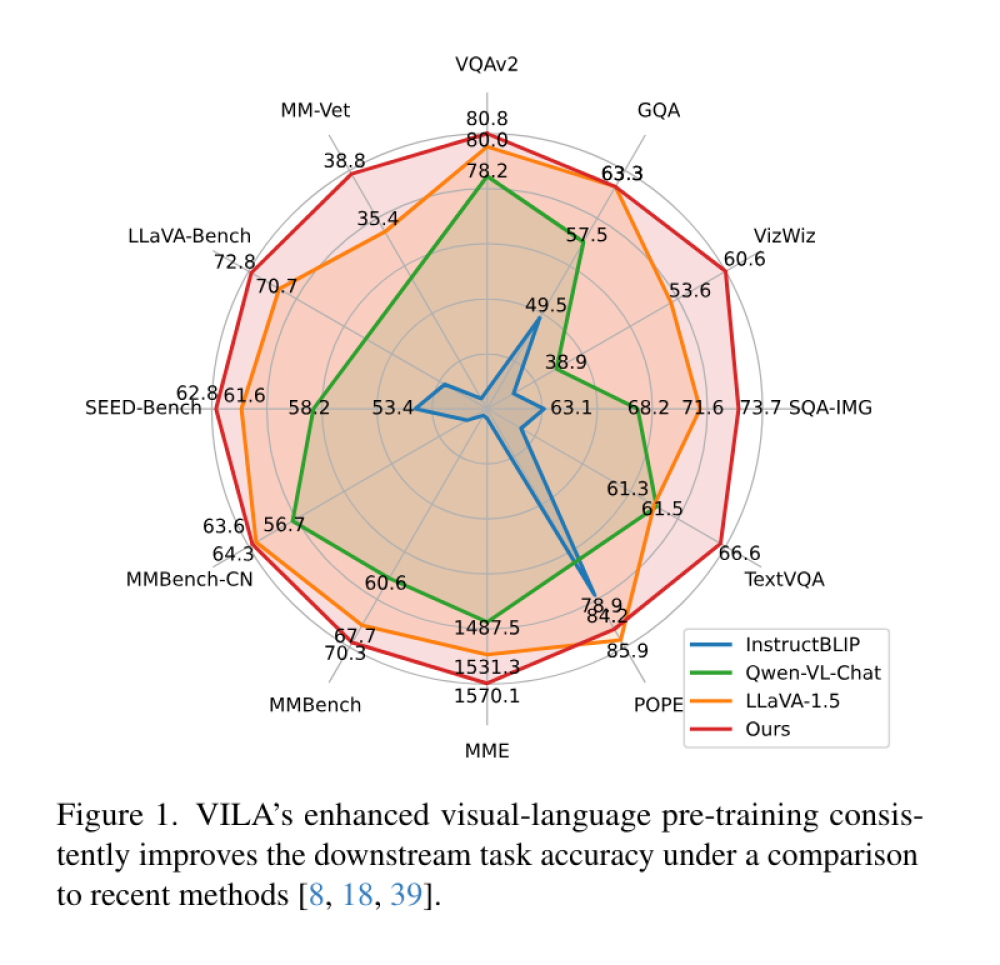
- VILA đạt mức độ chính xác trung bình 70.7% trên OKVQA và 78.2% trên TextVQA, vượt trội hơn đáng kể so với các tiêu chuẩn hiện có.
- VILA duy trì được tới 90% kiến thức đã học trước đó khi học các tác vụ mới, giảm thiểu hiện tượng quên thảm họa (catastrophic forgetting).
📌 VILA, khung pre-training ngôn ngữ thị giác mới của NVIDIA và MIT, đạt được những cải tiến đáng kể về độ chính xác (70,7% trên OKVQA, 78,2% trên TextVQA) và khả năng học trong ngữ cảnh, đồng thời giảm thiểu quên thảm họa, duy trì tới 90% kiến thức đã học khi tiếp cận tác vụ mới.
Citations:
[1] https://www.marktechpost.com/2024/05/04/researchers-at-nvidia-ai-introduce-vila-a-vision-language-model-that-can-reason-among-multiple-images-learn-in-context-and-even-understand-videos/



Thảo luận
Follow Us
Tin phổ biến
