Nghiên cứu AI của ByteDance tiết lộ Phương pháp tinh chỉnh tăng cường (ReFT) để nâng cao tính khái quát của việc học LLM
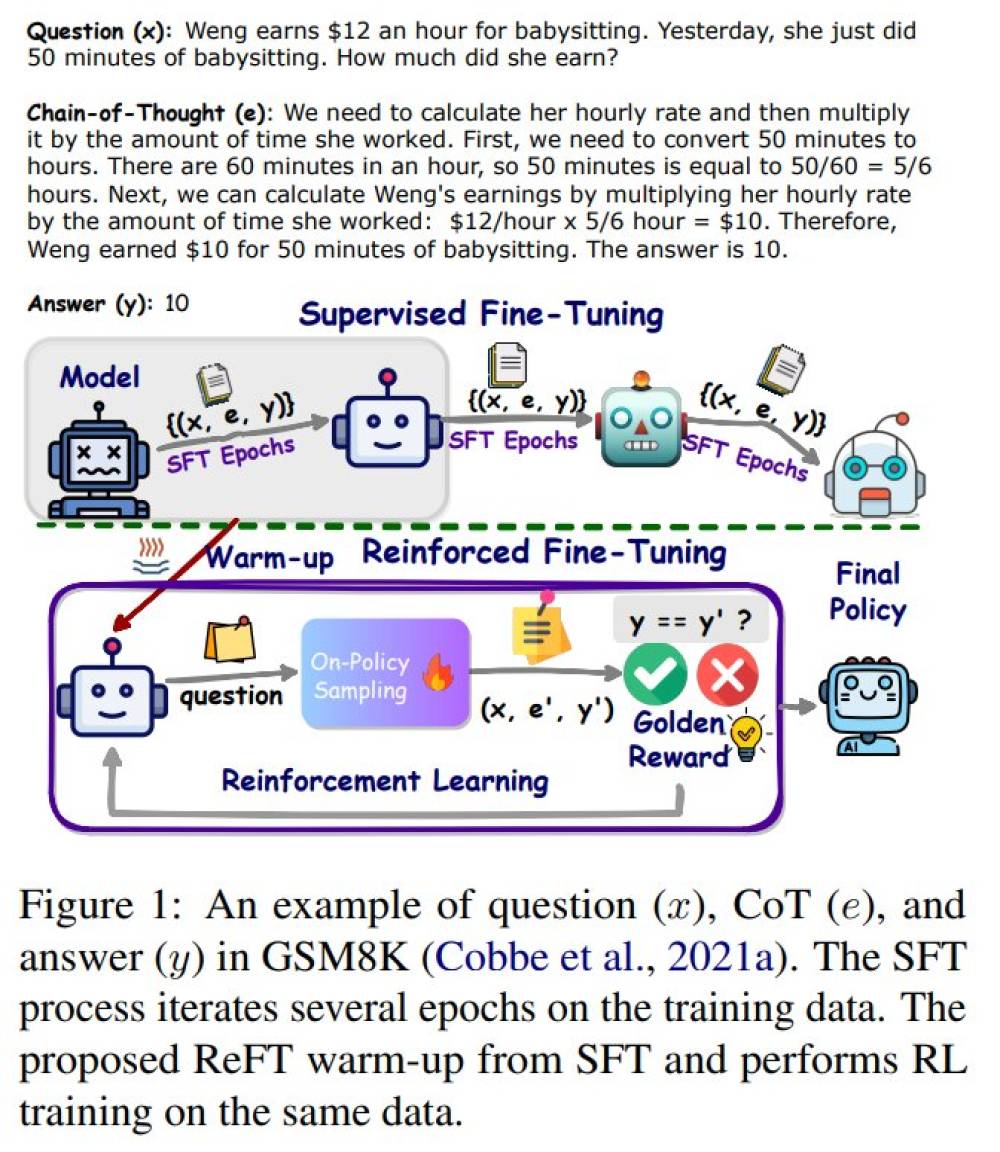
- Nghiên cứu mới của ByteDance AI Research giới thiệu phương pháp Reinforced Fine-Tuning (ReFT) để cải thiện khả năng tổng quát hóa việc học của LLMs trong lí thuyết, với việc giải quyết vấn đề toán làm ví dụ.
- ReFT kết hợp giữa việc tinh chỉnh có giám sát (SFT) với học tập củng cố trực tuyến, sử dụng thuật toán Proximal Policy Optimization (PPO). Quá trình này cho phép mô hình tiếp xúc với nhiều con đường lý luận khác nhau, tự động lấy mẫu từ câu hỏi đã cho.
- Phần thưởng cho việc học củng cố đến từ câu trả lời chính xác, giúp LLM trở nên mạnh mẽ và linh hoạt hơn. Các chiến lược tại thời điểm suy luận như bỏ phiếu đa số và tái xếp hạng kết hợp với ReFT để cải thiện hiệu suất.
- Các thí nghiệm trên các bộ dữ liệu GSM8K, MathQA và SVAMP cho thấy ReFT vượt trội hơn so với SFT về khả năng lý luận và khả năng tổng quát hóa. Việc sử dụng chương trình Python như dữ liệu CoT đã chứng minh bước tiến quan trọng so với dữ liệu CoT bằng ngôn ngữ tự nhiên.
- Nghiên cứu trước đây về học củng cố và tái xếp hạng cũng đã cho thấy hiệu suất vượt trội so với việc tinh chỉnh có giám sát và bỏ phiếu đa số.
📌 ReFT đánh dấu sự khác biệt trong các phương pháp tinh chỉnh để cải thiện khả năng giải quyết vấn đề toán của mô hình. Khác với SFT, ReFT tối ưu hóa một mục tiêu không phân biệt bằng cách khám phá nhiều chú thích CoT thay vì dựa vào một chú thích duy nhất. Các thí nghiệm rộng rãi trên ba bộ dữ liệu sử dụng hai mô hình cơ sở đã cho thấy ReFT vượt qua SFT về hiệu suất và khả năng tổng quát hóa. Mô hình được đào tạo với ReFT tương thích với các kỹ thuật như bỏ phiếu đa số và tái xếp hạng mô hình thưởng. ReFT còn vượt qua nhiều mô hình nguồn mở có kích thước tương tự trong việc giải quyết vấn đề toán, nhấn mạnh hiệu quả và giá trị thực tiễn của nó.



Thảo luận
Follow Us
Tin phổ biến

TAG
AI giáo dục
AI sinh-y-duoc
AI nghệ thuật
AI pháp lý-quản trị-chủ quyền
AI models
AI xã hội
AI prompts
AI kiến thức-khóa học
AI công nghiệp-lĩnh vực
AI edge
AI viễn thông
AI tools
AI chính phủ
AI cybersecurity
AI so sánh
AI đạo đức
AI tips
AI market
AI quân sự
AI an toàn-an ninh-techwar
AI việc làm
AI doanh nghiệp
OpenAI ChatGPT
AI môi trường-năng lượng
AI skill-talent
AI & công nghệ khác
AI nghiên cứu
AI chips-hardware-compute
AI vs con người
AI coding assistant
AI mở-nguồn mở
AI năng suất
AI startup-M&A
AI tương lai
AI báo chí
AI data
AI bản quyền
AI PC
AI riêng tư
AI deepfake-ảo giác-ANTT
AI ảnh-video-music-âm thanh
AI minh bạch
AI nhỏ
AI nông nghiệp-thực phẩm
AI ngân hàng-tài chính
AI giao thông
AI smartphone
AI robotics-auto-agents
AI consumer devices
AI manufacturing
AI benchmark
Telecom
AI thành công-thất bại
Digital
Semi-Cloud-DC-Green
HTS
STI
FAQ