Nghiên cứu của ĐH Stanford: Tích lũy dữ liệu ngăn sụp đổ mô hình AI khi huấn luyện trên dữ liệu tổng hợp
• Các nhà nghiên cứu từ Đại học Stanford đã tiến hành một nghiên cứu về tác động của việc tích lũy dữ liệu đối với sự sụp đổ mô hình trong các mô hình AI tạo sinh.
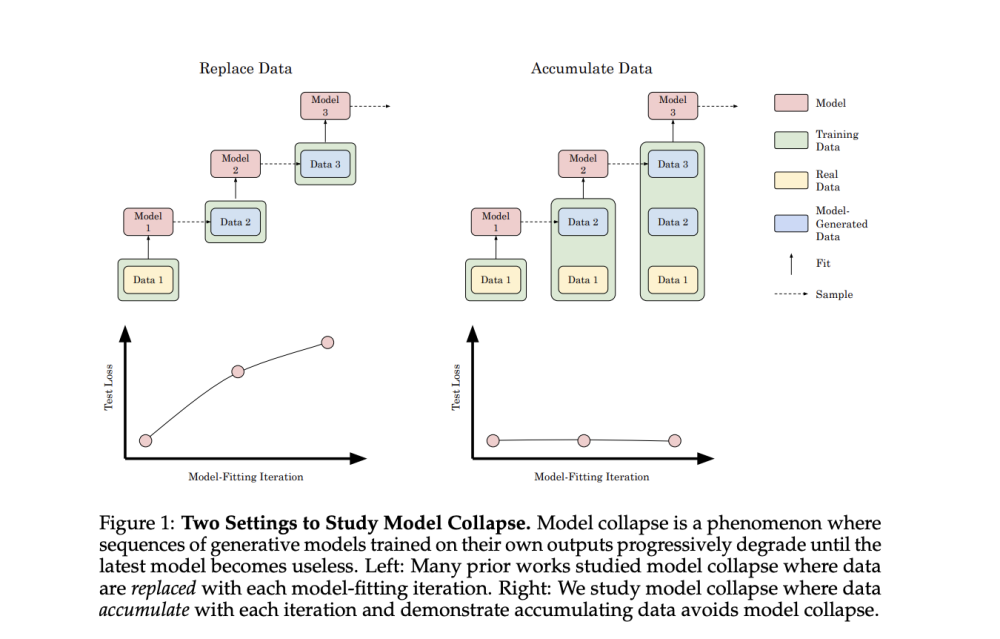
• Nghiên cứu tập trung vào việc mô phỏng sự tích lũy liên tục của dữ liệu tổng hợp trong các bộ dữ liệu dựa trên internet, khác với các nghiên cứu trước đây chỉ tập trung vào việc thay thế dữ liệu.
• Các thí nghiệm được thực hiện trên nhiều loại mô hình khác nhau như transformer, mô hình khuếch tán và autoencoder biến phân, với nhiều loại dữ liệu khác nhau.
• Kết quả cho thấy việc tích lũy dữ liệu tổng hợp cùng với dữ liệu thực ngăn chặn được sự sụp đổ mô hình, trái ngược với sự suy giảm hiệu suất khi thay thế dữ liệu.
• Với mô hình ngôn ngữ transformer, các thí nghiệm sử dụng kiến trúc GPT-2 và Llama2 với nhiều kích thước khác nhau, được huấn luyện trước trên TinyStories.
• Kết quả cho thấy việc thay thế dữ liệu làm tăng cross-entropy trên tập kiểm tra (hiệu suất kém hơn) ở tất cả các cấu hình mô hình và nhiệt độ lấy mẫu.
• Ngược lại, việc tích lũy dữ liệu duy trì hoặc cải thiện hiệu suất qua các lần lặp.
• Với mô hình khuếch tán GeoDiff trên dữ liệu cấu trúc phân tử GEOM-Drugs, kết quả cũng cho thấy tổn thất kiểm tra tăng lên khi thay thế dữ liệu, nhưng hiệu suất ổn định khi tích lũy dữ liệu.
• Đối với VAE trên dữ liệu hình ảnh khuôn mặt CelebA, việc thay thế dữ liệu dẫn đến sự sụp đổ mô hình nhanh chóng, với lỗi kiểm tra tăng và chất lượng/đa dạng hình ảnh giảm.
• Tích lũy dữ liệu làm chậm đáng kể sự sụp đổ, giữ được các biến thể chính nhưng mất chi tiết nhỏ qua các lần lặp.
• Các nhà nghiên cứu đã mở rộng phân tích hiện có của các mô hình tuyến tính tuần tự để chứng minh rằng việc tích lũy dữ liệu dẫn đến một giới hạn trên hữu hạn, được kiểm soát tốt đối với lỗi kiểm tra, độc lập với số lần lặp khớp mô hình.
• Phát hiện này trái ngược với sự gia tăng lỗi tuyến tính được thấy trong các kịch bản thay thế dữ liệu.
📌 Nghiên cứu từ Stanford chỉ ra rằng tích lũy dữ liệu tổng hợp cùng dữ liệu thực có thể ngăn chặn sự sụp đổ mô hình AI. Kết quả nhất quán trên nhiều loại mô hình và dữ liệu, với lý thuyết chứng minh giới hạn lỗi hữu hạn khi tích lũy dữ liệu, khác biệt so với tăng lỗi tuyến tính khi thay thế dữ liệu.
https://www.marktechpost.com/2024/07/29/this-ai-paper-from-stanford-provides-new-insights-on-ai-model-collapse-and-data-accumulation/



Thảo luận
Follow Us
Tin phổ biến
