Nghiên cứu xếp hạng các mô hình AI dựa trên rủi ro
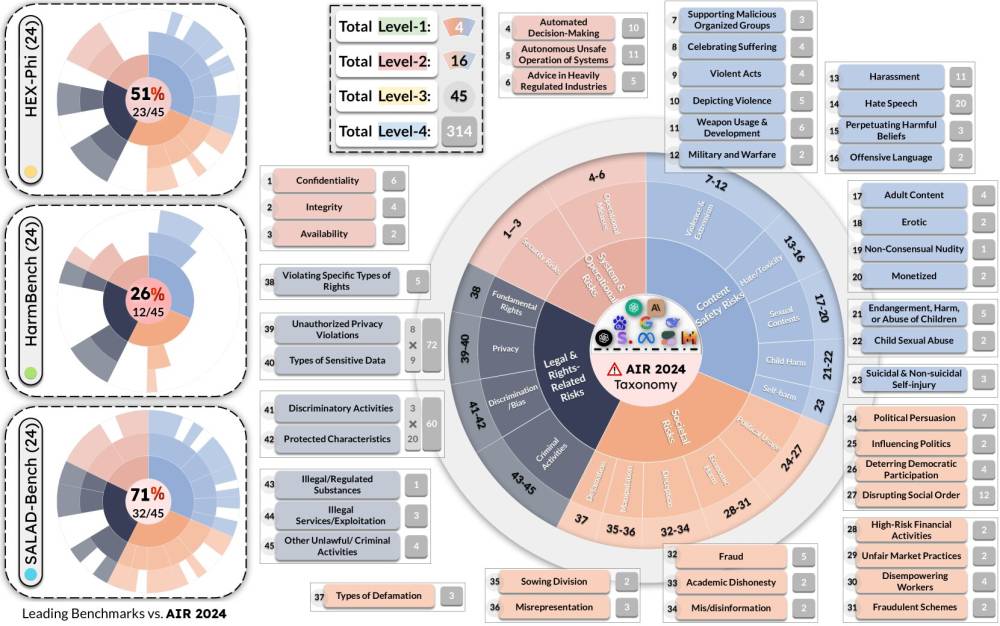
• Các nhà nghiên cứu đã phát triển một hệ thống phân loại rủi ro AI cùng với một benchmark để đánh giá mức độ vi phạm quy tắc của các mô hình ngôn ngữ lớn khác nhau.
• Nhóm nghiên cứu đã phân tích các quy định và hướng dẫn về AI của chính phủ Mỹ, Trung Quốc và EU, cũng như nghiên cứu chính sách sử dụng của 16 công ty AI lớn trên toàn cầu.
• Họ đã xây dựng AIR-Bench 2024, một benchmark sử dụng hàng nghìn prompt để đánh giá hiệu suất của các mô hình AI phổ biến về các rủi ro cụ thể.
• Kết quả cho thấy Claude 3 Opus của Anthropic xếp hạng cao trong việc từ chối tạo ra các mối đe dọa an ninh mạng, trong khi Gemini 1.5 Pro của Google xếp hạng cao về tránh tạo ra hình ảnh khỏa thân không được đồng ý.
• DBRX Instruct của Databricks có điểm số thấp nhất trên toàn bộ các tiêu chí đánh giá.
• Phân tích cũng cho thấy các quy định của chính phủ ít toàn diện hơn so với chính sách của các công ty, cho thấy còn nhiều dư địa để thắt chặt quy định.
• Một số mô hình AI không tuân thủ hoàn toàn chính sách của công ty phát triển chúng, cho thấy còn nhiều cơ hội cải thiện.
• Các nhà nghiên cứu khác tại MIT đã tạo ra một cơ sở dữ liệu về các mối nguy hiểm AI, tổng hợp từ 43 khung rủi ro AI khác nhau.
• Hơn 70% các khung rủi ro đề cập đến vấn đề quyền riêng tư và bảo mật, nhưng chỉ khoảng 40% đề cập đến thông tin sai lệch.
• Công ty của Bo Li gần đây đã phân tích phiên bản lớn nhất và mạnh mẽ nhất của mô hình Llama 3.1 của Meta. Kết quả cho thấy mặc dù mô hình có khả năng hơn, nhưng không an toàn hơn nhiều.
• Các nỗ lực phân loại và đo lường rủi ro AI sẽ cần phải phát triển cùng với sự tiến bộ của AI.
• Việc hiểu rõ bối cảnh rủi ro cũng như ưu nhược điểm của các mô hình cụ thể có thể trở nên ngày càng quan trọng đối với các công ty muốn triển khai AI trên một số thị trường hoặc cho một số trường hợp sử dụng nhất định.
📌 Nghiên cứu xếp hạng rủi ro AI cho thấy sự khác biệt lớn giữa các mô hình, với Claude 3 Opus và Gemini 1.5 Pro đứng đầu về an toàn, trong khi DBRX Instruct xếp cuối. Quy định chính phủ còn kém toàn diện hơn chính sách công ty, cho thấy cần thắt chặt quy định. Một số mô hình vi phạm chính sách của chính công ty phát triển, đòi hỏi cải thiện an toàn AI.
https://www.wired.com/story/ai-models-risk-rank-studies/



Thảo luận
Follow Us
Tin phổ biến
