nguồn dữ liệu văn bản công khai sẽ cạn kiệt cho các mô hình AI vào năm 2028
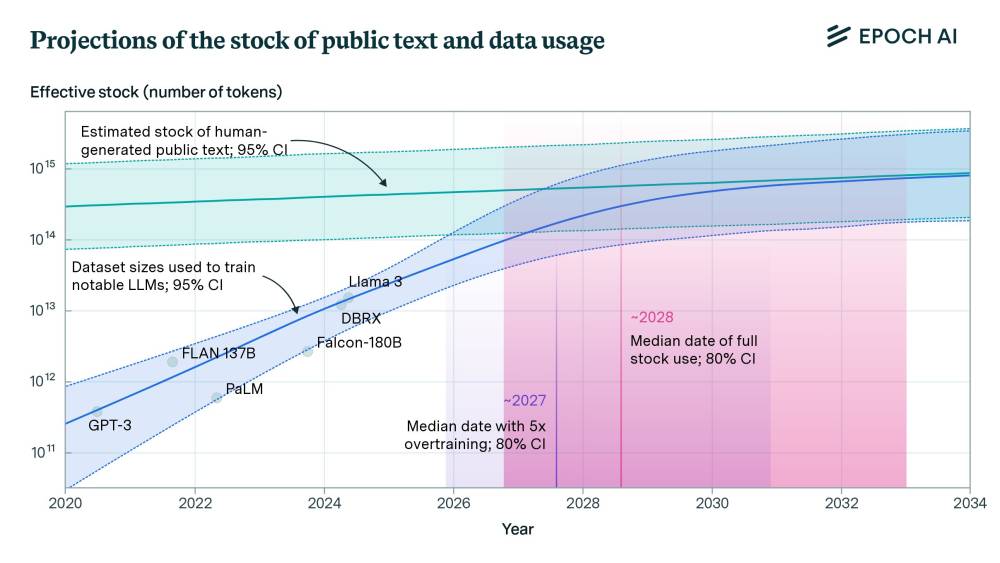
• Nghiên cứu ước tính tổng lượng dữ liệu văn bản công khai chất lượng cao do con người tạo ra vào khoảng 300 nghìn tỷ token, với khoảng tin cậy 90% từ 100 nghìn tỷ đến 1 triệu tỷ token.
• Nếu mô hình được huấn luyện tối ưu về tính toán, nguồn dữ liệu này sẽ đủ để huấn luyện một mô hình 5e28 FLOP, mức dự kiến đạt được vào năm 2028.
• Tuy nhiên, các mô hình gần đây thường được huấn luyện quá mức với ít tham số hơn và nhiều dữ liệu hơn để hiệu quả hơn khi suy luận. Nếu mô hình được huấn luyện quá mức gấp 5 lần, nguồn dữ liệu sẽ cạn kiệt vào năm 2027, nhưng nếu quá mức gấp 100 lần, nó sẽ cạn kiệt vào năm 2025.
• Nghiên cứu trước đây dự đoán dữ liệu văn bản chất lượng cao sẽ được sử dụng hết vào năm 2024, nhưng kết quả mới cho thấy điều đó có thể không xảy ra cho đến năm 2028. Sự khác biệt này là do phương pháp luận khác nhau và kết hợp các phát hiện gần đây đã thay đổi hiểu biết về chất lượng dữ liệu và đào tạo mô hình.
• Ngay cả khi mô hình được huấn luyện trên tất cả dữ liệu văn bản công khai, điều này không nhất thiết dẫn đến sự dừng lại hoàn toàn của tiến bộ trong khả năng mô hình. Các đổi mới mới sẽ cần thiết để duy trì tiến bộ sau năm 2030, bao gồm dữ liệu tổng hợp, học từ các phương thức dữ liệu khác và cải thiện hiệu quả dữ liệu.
📌 Nghiên cứu cho thấy nguồn dữ liệu văn bản công khai 300 nghìn tỷ token sẽ đủ để huấn luyện các mô hình ngôn ngữ lớn đến năm 2028. Tuy nhiên, xu hướng huấn luyện quá mức có thể khiến nguồn dữ liệu này cạn kiệt sớm hơn, vào khoảng 2025-2027. Để duy trì đà phát triển sau năm 2030, các đổi mới như dữ liệu tổng hợp, học từ nhiều phương thức dữ liệu và cải thiện hiệu quả sử dụng dữ liệu sẽ là then chốt.
Citations:
[1] https://ppl-ai-file-upload.s3.amazonaws.com/web/direct-files/131695/201f6832-04f3-44d4-8c71-cd9327dc8e03/paste.txt
https://epochai.org/blog/will-we-run-out-of-data-limits-of-llm-scaling-based-on-human-generated-data
https://arxiv.org/pdf/2211.04325



Thảo luận
Follow Us
Tin phổ biến
