Nvidia tung ra mô hình ngôn ngữ "siêu nhỏ" Llama-Minitron 3.1 4B với sức mạnh ngang ngửa LLM lớn hơn
• Nvidia vừa công bố mô hình ngôn ngữ mới Llama-3.1-Minitron 4B, một phiên bản nhỏ gọn được tạo ra từ mô hình lớn hơn Llama 3.1 8B.
• Để tạo ra mô hình nhỏ hơn này, Nvidia đã sử dụng kỹ thuật cắt tỉa có cấu trúc theo chiều sâu và chiều rộng. Cụ thể, họ đã loại bỏ 16 lớp từ mô hình gốc để giảm kích thước từ 8B xuống 4B.
• Ngoài cắt tỉa, Nvidia còn áp dụng kỹ thuật chưng cất kiến thức cổ điển để nâng cao hiệu quả của Llama-3.1-Minitron 4B. Quá trình này giúp mô hình nhỏ hơn bắt chước hành vi của mô hình lớn hơn.
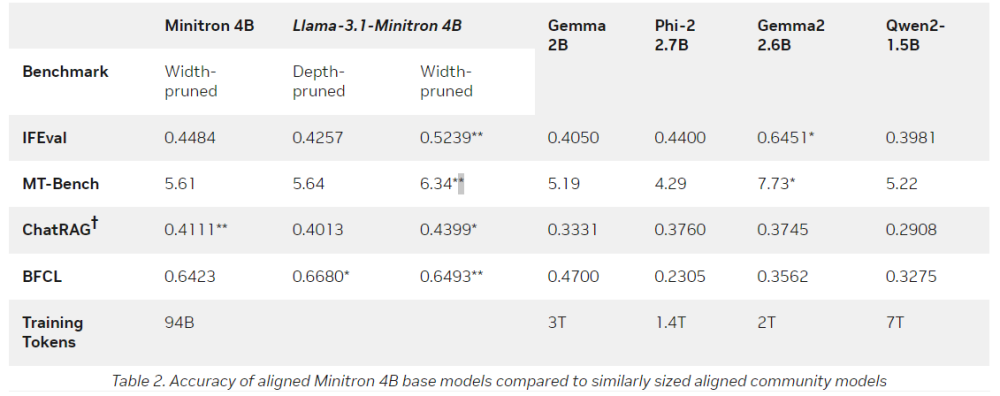
• Llama-3.1-Minitron 4B đạt hiệu suất cạnh tranh so với các mô hình nguồn mở tiên tiến lớn hơn trong nhiều bài kiểm tra. Nó vượt trội hơn hẳn so với nhiều mô hình ngôn ngữ nhỏ khác như Minitron 4B, Phi-2 2.7B, Gemma2 2.6B và Qwen2-1.5B.
• Mô hình mới chỉ sử dụng một phần nhỏ số lượng token huấn luyện so với việc huấn luyện từ đầu, tiết kiệm đáng kể chi phí tính toán.
• Nvidia đã tối ưu hóa thêm Llama-3.1-Minitron 4B để triển khai bằng bộ công cụ TensorRT-LLM, giúp tăng hiệu suất suy luận. Ví dụ, thông lượng của mô hình ở độ chính xác FP8 tăng lên gấp 2,7 lần so với mô hình Llama 3.1 8B gốc.
• Llama-3.1-Minitron 4B sẽ trở thành một phần trong bộ sưu tập Hugging Face của Nvidia, góp phần vào sự phát triển của các mô hình AI mạnh mẽ và miễn phí.
• Mô hình mới này đánh dấu một bước tiến quan trọng trong sự phát triển của các mô hình ngôn ngữ lớn, kết hợp hiệu quả của mô hình quy mô lớn với kích thước nhỏ gọn hơn.
• Llama-3.1-Minitron 4B có thể dễ dàng áp dụng trong nhiều lĩnh vực khác nhau nhờ vào hiệu suất cao và tính hiệu quả về tài nguyên.
📌 Nvidia đã tạo ra Llama-3.1-Minitron 4B, một mô hình ngôn ngữ 4 tỷ tham số có hiệu suất ngang ngửa các mô hình lớn hơn nhưng tiết kiệm tới 40 lần tài nguyên huấn luyện. Mô hình này vượt trội so với nhiều mô hình nhỏ khác và có thể dễ dàng triển khai trong nhiều ứng dụng thực tế.
https://www.marktechpost.com/2024/08/16/nvidia-ai-released-llama-minitron-3-1-4b-a-new-language-model-built-by-pruning-and-distilling-llama-3-1-8b/



Thảo luận
Follow Us
Tin phổ biến
