OpenAI ra mắt gpt-oss-120b và gpt-oss-20b – hai mô hình ngôn ngữ AI nguồn mở hàng đầu
-
OpenAI phát hành hai mô hình AI nguồn mở: gpt-oss-120b và gpt-oss-20b theo giấy phép Apache 2.0, tập trung vào khả năng lập luận và sử dụng công cụ mạnh mẽ với chi phí thấp.
-
gpt-oss-120b có 117 tỷ tham số, chỉ kích hoạt 5.1 tỷ/tham số mỗi token, chạy hiệu quả trên GPU 80 GB.
gpt-oss-20b với 21 tỷ tham số, chỉ cần 16 GB RAM, lý tưởng cho inference tại chỗ, thiết bị biên, hoặc phát triển nhanh. -
Cả hai mô hình đều hỗ trợ tool use, function calling, chain-of-thought (CoT), và cấu trúc đầu ra có cấu trúc. Giao diện tương thích với Responses API.
-
Kiến trúc dựa trên Mixture-of-Experts (MoE):
-
gpt-oss-120b: 36 layers, 128 experts, 4 experts hoạt động/layer
-
gpt-oss-20b: 24 layers, 32 experts, 4 active experts
-
Đều hỗ trợ context length lên đến 128.000 token
-
-
Đánh giá khả năng lập luận vượt trội:
-
HealthBench: gpt-oss-120b đạt 59.8%, vượt o3 và GPT-4o
-
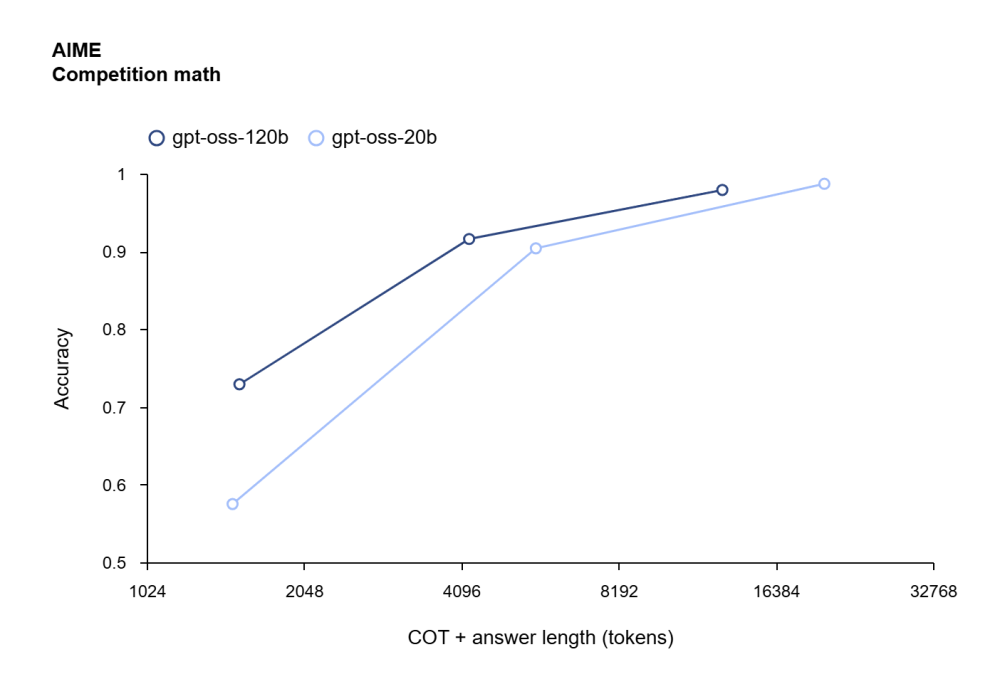
AIME 2024: gpt-oss-20b đạt 98.7%, gpt-oss-120b đạt 97.9%
-
MMLU: gpt-oss-120b đạt 67.8%
-
GPQA (PhD-level): gpt-oss-120b đạt 90%
-
-
Tích hợp safety bằng framework kiểm tra phơi nhiễm và huấn luyện chống prompt injection. Mô hình đã được kiểm thử với phiên bản tinh chỉnh độc hại nhưng vẫn không đạt capability cao, đảm bảo an toàn phát hành.
-
Phân phối qua nhiều nền tảng như Hugging Face, Azure, vLLM, llama.cpp, Cloudflare, Apple Metal, hỗ trợ inference tại chỗ và đám mây.
-
Có phiên bản GPU-optimized cho Windows (ONNX Runtime), mã nguồn mở tokenizer o200k_harmony, thư viện harmony renderer bằng Python và Rust.
📌 OpenAI phát hành gpt-oss-120b và gpt-oss-20b – hai mô hình ngôn ngữ AI nguồn mở mạnh mẽ với khả năng lập luận vượt trội (MMLU: 67.8%, GPQA: 90%, AIME: ~98%), hỗ trợ inference tại chỗ với RAM từ 16 GB, kiến trúc MoE tiên tiến, tích hợp an toàn vượt chuẩn, và tương thích rộng rãi trên nhiều nền tảng.
https://openai.com/index/introducing-gpt-oss/



Thảo luận
Follow Us
Tin phổ biến
